Testing that Scales
Extensive testing is an indispensable part of building large systems in the Wolfram Language and PacletAssurance provides some key functionality to complement the built-in testing framework. In particular, managing large numbers of tests requires decomposing them into manageable chunks but this contains a flip-side--subsequently composing these chunks back together to inform system-critical decisions. The insight exploited by this package is that this decomposing/composing need not always involve the entirety of the tests themselves---it can sometimes usefully involve summary information about the tests--information captured by running TestSummary. By more efficiently and frequently recording the summarized state of a testing regime, decisions about optimal testing strategies become more data-driven as your system scales.
One significant drawback with a unit-testing system lacking summaries is that many repeatable tasks become increasingly unwieldy as the system scales. Take, for example, two reports each containing 100K tests which we will model here with a toy test checking an integer's parity.
To simulate the described scenario, create two collections of 100K tests each. First a helper function to define the parity test and starting point.
In the wild, test suites of this order might take years to assemble but with these now generated, we can at least start a simulation of producing respective test reports:
Already the memory usage exceeds that which is ordinarily stored in notebooks as evidenced from the special "Save now" request for each report generated. No such memory issues arise however, when generating test summaries.
The notebook entreaty persists (exacerbated by a memory-doubling) but of no concern here when summaries are merged.
The resources needed to ascertain this core outcome however, are vastly different. While the memory disparity is the most alarming (a non-negligible percentage of total memory), there also exists a significant time-penalty when merging reports compared with summaries. The following quantifies the respective differences in this simulation.
The real-world consequences of the order-of-magnitude differences in resources needed to combine test summaries and test reports are discussed later in the section Scaling Up. Naturally, not retaining individual tests means losing some information about the test data. It turns out however, that even basic statistics on this data can be precisely retained when using summaries--a topic to which we now turn.
A test report contains certain numerical properties like AbsoluteTimeUsed, CPUTimeUsed, MemoryUsed that are essentially aggregated values from the entire collection of individual tests. Often this is useful information in its own right but other insights relate to the distribution of testing dataset can also become important. For example, knowing the AbsoluteTimeUsed in a test report assists planning by estimating how long future runs are likely to take. Knowing the spread of the AbsoluteTimeUsed however, can also be a useful marker for characterizing tests, detecting bottlenecks or even as a feature through which especially effective test-suites can be machine-learned.
Generating the type of descriptive statistics just described is obviously easily available in the WL. For example, compute the standard deviation of the 100K values of AbsoluteTimeUsed for each test in the suite.
Basic statistics are similarly available using summaries but are far more efficiently computable (~0.3 milliseconds vs ~2.0 seconds).
Similarly, while MemoryUsed measures the total memory used in a test report, its sequential evaluation includes recycled memory suggesting maximum memory as an alternative measure. For example, determine the maximum memory used by any individual test by traversing the report's 100K tests.
This descriptive statistic is also available however, in the corresponding summary but more efficiently extractable (~0.3 milliseconds vs ~2.0 seconds).
While merged summaries readily maintain incremental statistics like: minimum, maximum and the mean, perhaps more surprising is that summaries can do likewise for more distributive measures like variance, skewness and kurtosis. By maintaining "MomentrSums" (  xir) and then aggregating these across multiple summaries, more efficient merging becomes available. In particular, updating basic statistics when merging summaries can be performed in virtually constant-time independent of the number of tests. In contrast, merging test reports depends explicitly on the number of tests and hence is susceptible to degradedperformance as a system scales.
xir) and then aggregating these across multiple summaries, more efficient merging becomes available. In particular, updating basic statistics when merging summaries can be performed in virtually constant-time independent of the number of tests. In contrast, merging test reports depends explicitly on the number of tests and hence is susceptible to degradedperformance as a system scales.
The InputForm of a summary shows its stored moment information that, despite its comparatively light memory-footprint, useful properties can nonetheless still be extracted.
From combining these moments basic statistics can be precisely reconstructed with traditional reservations about floating-point arithmetic errors overcome by WL's arbitrary precision.
Naturally, more detailed analyses will always require the original tests traditionally stored in test reports. This reinforces an idiom of best-practice consisting of using TestSummary as a complement to TestReport rather than as a replacement. Nonetheless, the performance advantage of working with more lightweight summaries, improves with the number of tests solidifying a WL-based system with the following section outlining the scale of this potential advantage.
We have just observed then, that summary provide more efficient extraction of statistical measures in addition to the lighter time and memory footprints needed for merging as was earlier observed. Putting these together in the following table collates this overall advantage.
While the order of magnitude differences are clear for this manufactured sample of 200K toy tests, 1-2s computations occupying ~2% of available memory might seem manageable. There are however, emerging trends that point towards these resources increasing substantially over time, perhaps even by orders of magnitude for WL-based systems with serious growth ambitions. These trends relate to three factors that influence the resources needed to run and manage test suites namely; the number of tests, the nature of tests and the frequency of test runs.
Number of tests
While a number of tests in the order of 200K are well beyond what is needed for the types of packages historically implemented in the WL, this calculus changes as fully-fledged WL-based computational systems become more commonplace. Unit tests remain the gold standard for ensuring system-correctness and with the infrastructure for third-party developers continuing to grow, (particularly the paclet repository), the volume of tests is set to rapidly accelerate along with their efficient management. To provide some forward-leaning context, the number of unit tests for Mathematica is, by now, in the millions which no doubt requires considerable management while also incurring significant computational costs.
Nature of tests
The nature of tests also impacts the resources needed in their management. While the very notion of a unit test speaks to a unit of functionality, in practice, it is usually more efficient to pack several pieces of functionality into a single test. Further, TestCreate allows tests to be stored (without necessarily being run) rendering the formed TestReportObject as a type of test repository further incentivizing its routine summarization. Finally, as the number of packages within a system grows, the interrelatedness between tests inexorably increases portending the arrival of non-trivial memory footprints well before an arbitrary 200K benchmark as just simulated.
Frequency of testing
The frequency of testing forms part of a modern trend in software development and deployment or continuous integration/continuous development (CI/CD). And the extra flexibility in these activities requires a similar flexibility in an accompanying testing program; in short, successful CI/CD rests on having versatile and scalable test suites. For large systems, versatile testing often involves decisions about allocating de-bugging resources, nightly builds, merging multiple test-suites, staged releases etc. with each process invariably carrying its own correctness threshold as reflected in corresponding test-suites. Being able to organizing such bespoke test-suites in terms of summaries then, (especially when expressed in responsive dashboards) plays a critical role in modern software creation.
Test suites are traditionally not shipped with software products instead being restricted to the quality-control undertaken prior to official release. We think this is a mistake and worth changing. Routinely including such tests imposes a discipline and accountability on developers that can but improve the robustness of their published software. Further, users benefit from enjoying new standard of transparency born from being able to, if so inclined, peak under the development-hood to gain insights into a function's scope, robustness and historical evolution.
A function's documentation is one important marker of functionality but in our view, equally important are the sum total of a function's unit tests. This is because it is via the thoroughness of an explicit test suite that a package's underlying correctness can be established in a way that is arguably fundamentally impossible to achieve through any other methodology. A transparent testing regime bundled with any release then, represents a form of certificate that can ultimately vouch for the quality and integrity of a WL-based system.
This spirit of transparency and accountability motivates a convention that promotes a healthy, robust WL ecosystem, namely one whereby paclets routinely include a TestFiles directory containing multiple test files that effectively certifies a package's functionality. For example, the PacleteAssurance package abides by this convention through its TestFiles directory in addition to the other standard directories that appear in a production release:
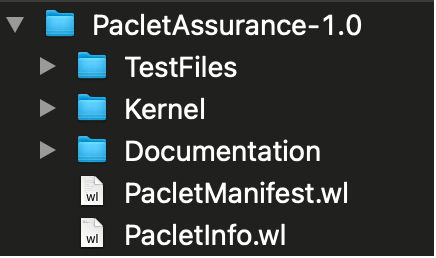
The TestFiles directory is "seen" by PacletAssurance from its PacletInfo.wl file containing a "TestFiles" extension as illustrated:
PacletObject[
<|"Name"->"PacletAssurance",
"Version"->"1.0",
"Description"->"Advanced Unit-testing in the WL",
"Extensions"->{
{"Kernel","Root"->"Kernel","Context"->"PacletAssurance`"},
{"Documentation", Language -> "English"},
{"TestFiles","Root"->"TestFiles"}
} |>]
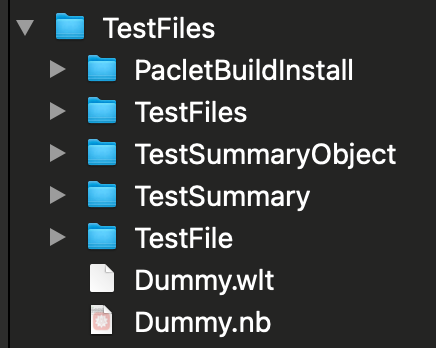
The contents of theTestFiles directory and its subdirectories contain the test files which, by convention, are arranged in folders corresponding to the package's public functions---here comprising: TestSummary, TestSummaryObject, TestFile and TestFiles (Dummy.wlt is a trivial test file that is used to test the package's file-finding and file-loading functionality).
The actual organization and naming of test files within these folders is likely to depend on the complexity of the function however one minimal approach suggests breaking down tests according to a function's: 1) core functionality 2) exception-handling and 3) documentation examples not previously covered. So, for example, the TestFiles directory (as a function now, not as the generic, top-level directory) in PacletAssurance contains the following layout:
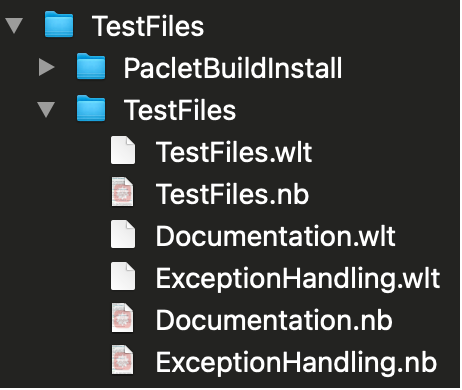
Note that the snapshot above is of the "build" paclet directory and hence, in particular each test file comes in two flavours, .nb and .wlt files. This is useful since the the .nb files acts essentially as a "front-end" container which developers can add, delete or edit tests while the corresponding .wlt files are more efficiently used by during production testing (essentially the extraction of tests from the .nb file into "raw" form is being pre-computed). The deployed paclet only includes the .wlt files since these are one that can be run by end-users.
With this convention in place, it now becomes straightforward for both developers and end-users to carry out package-testing to any desired degree of granularity. For example, the following runs all unit tests associated with PacletAssurance by running all tests found in all subdirectories:
This indicates that the package's correctness has been benchmarked at 100% and to the tune of 76 tests which takes ~1s to complete. This is the type of final check that the package must pass prior to release.
If, rather, a more granulated test is desired, running all the tests associated with the TestFiles function can be accomplished by using the TestFiles function (here acting on itself).
This indicates that the correctness of the TestFiles function has been benchmarked at 100% over 15 tests while taking about 170 ms to complete.
If even further granularity is desired, say down to the level of an individual test file, then this can be attained by using TestFile.
This indicates that the correctness of the TestFiles function in relation to its core functionality has been benchmarked at 100% over 12 tests while taking about 200 ms to complete.
If this level of test-file granularity is still desired but applied to another aspect of TestFiles' functionality, say its error-handling, the following can be invoked:
This indicates that the correctness of the TestFiles function in relation to exception-handling has been benchmarked at 100% over 12 tests while taking about 200 ms to complete.
Note that TestFile and TestFiles search for .wlt files by default, but searches for .nb test files can instead be requested through the "TestFileExtension" option. This however, can be considerably more inefficient.
If basic statistics are all that is required test summaries offer a lighter footprint with a roughly constant memory of around 10K.
While the previous differential in memory footprint was modelled on artificially-generated tests, this example "from the wild" is already indicating a non-trivial differential even for a moderately-sized package like PacletAssurance (coming in at ~1000 lines of WL code).
In conclusion we can see that using test summaries while adopting the convention of organizing test file in a paclet layout offers a convenient and powerful way to manage the complexity of testing WL-based systems
Types of Testing Categories & Developing Best Practice.
The decomposing of a system's tests into testing files within paclet folders provides a basic framework for managing testing complexity that developers can exploit further by standardizing the types of testing files constructed and using these as meta-data for developing best testing practice. Earlier it was suggested that a starting point for such standardization includes dedicated files for testing a function's 1) core functionality 2) exception-handling and 3) any outstanding documentation examples. There are however further types that may advantageously extend this coverage and granularization. These might include, for example, dedicated files for: error-handling, corner-cases, file-system-touching, computationally-intensive, known bugs to name a few along with surely other domain-specific possibilities.
There are also other "best-practice" questions worth monitoring as test-suites evolve in building large-scale WL-systems: What is the maximum number of tests per notebook? What is the relationship between the "complexity" of a code-base and the number of unit-tests needed to surpass reliability thresholds? What forms of unit test consistently prove optimal? It seems likely that both leading WL-based systems of tomorrow and a healthy WL package ecosystem will begin to develop insightful answers into exactly these types of questions.
Working in concert with both TestReport and TestSummary.
While summaries provide a fast, lightweight way to measure the current correctness of a WL-based systems, sometimes the granularization needs to reach right down to the level of tests--such as that available in test reports. But in such cases existing syntax need only be marginally adjusted. Suppose for example, one was initially interested in the maximum test size across all the tests used in PacletAssurance. This size can be quickly retrieved: