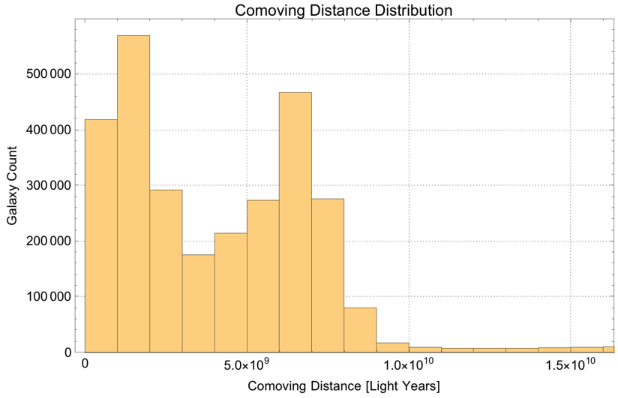
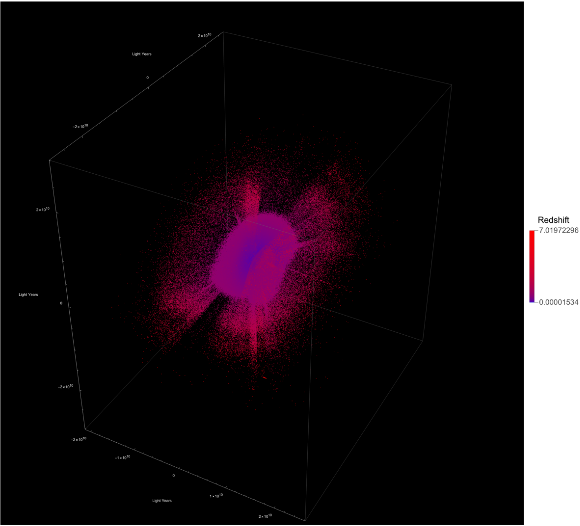
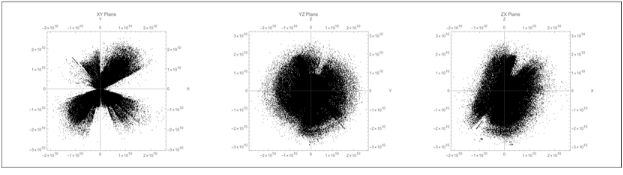
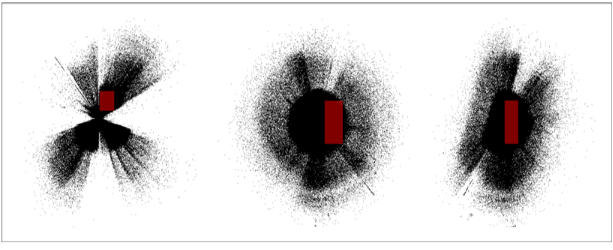
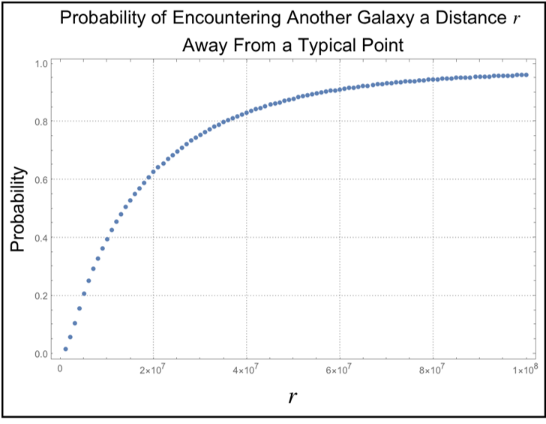
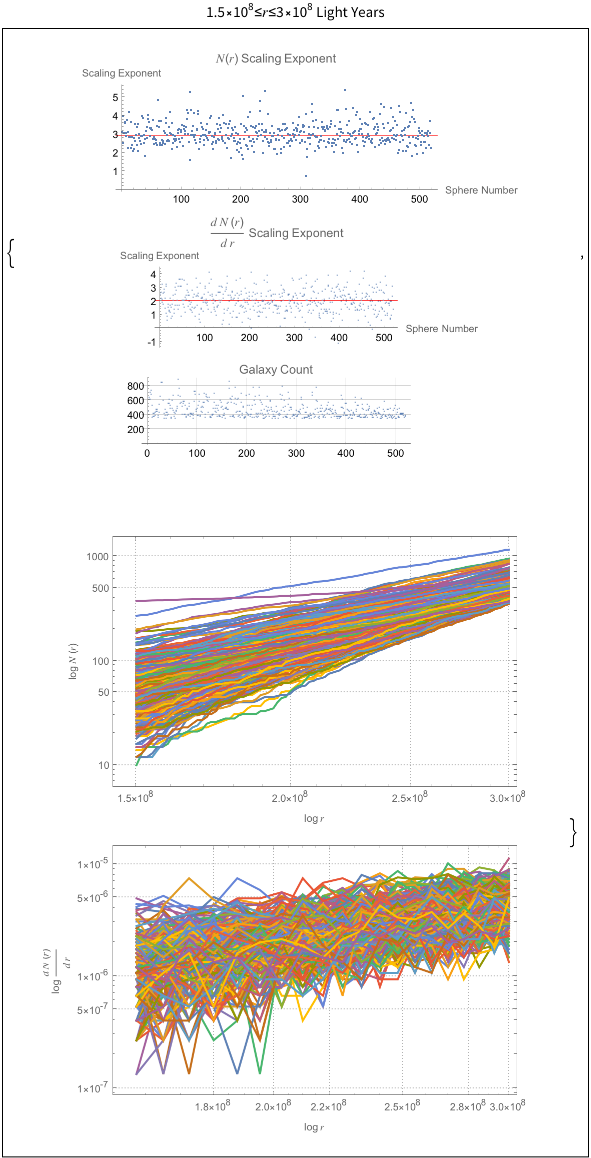
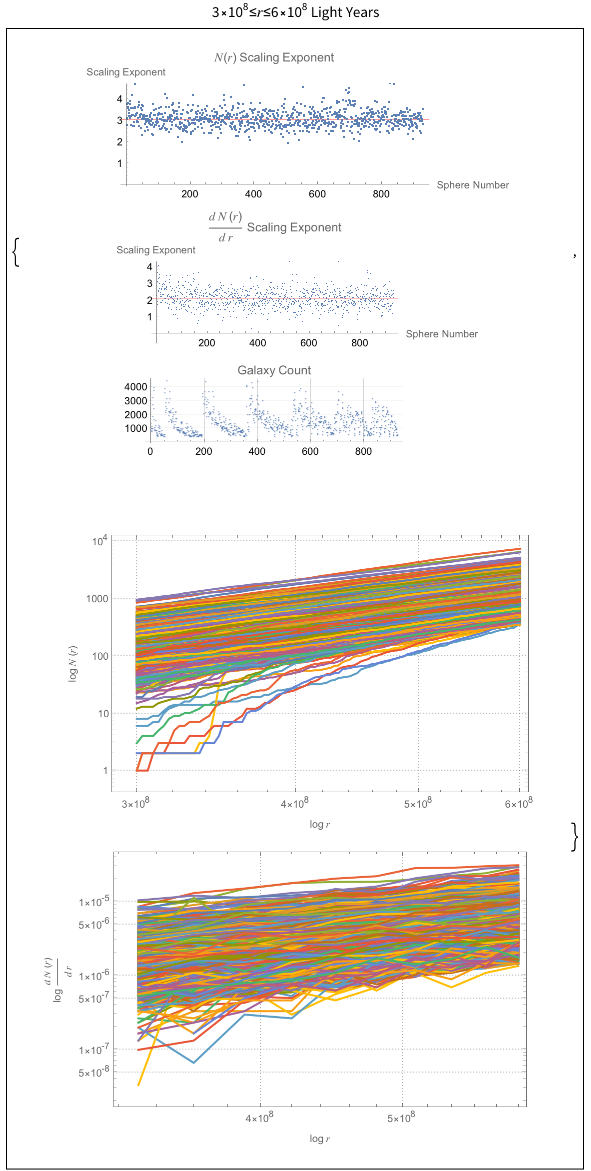
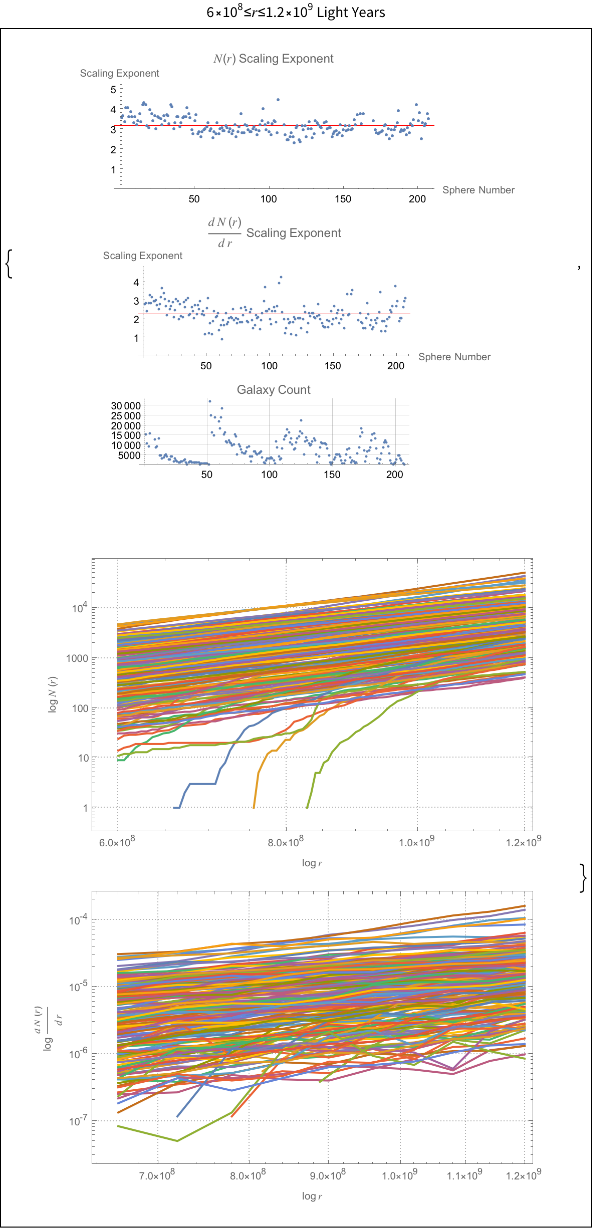
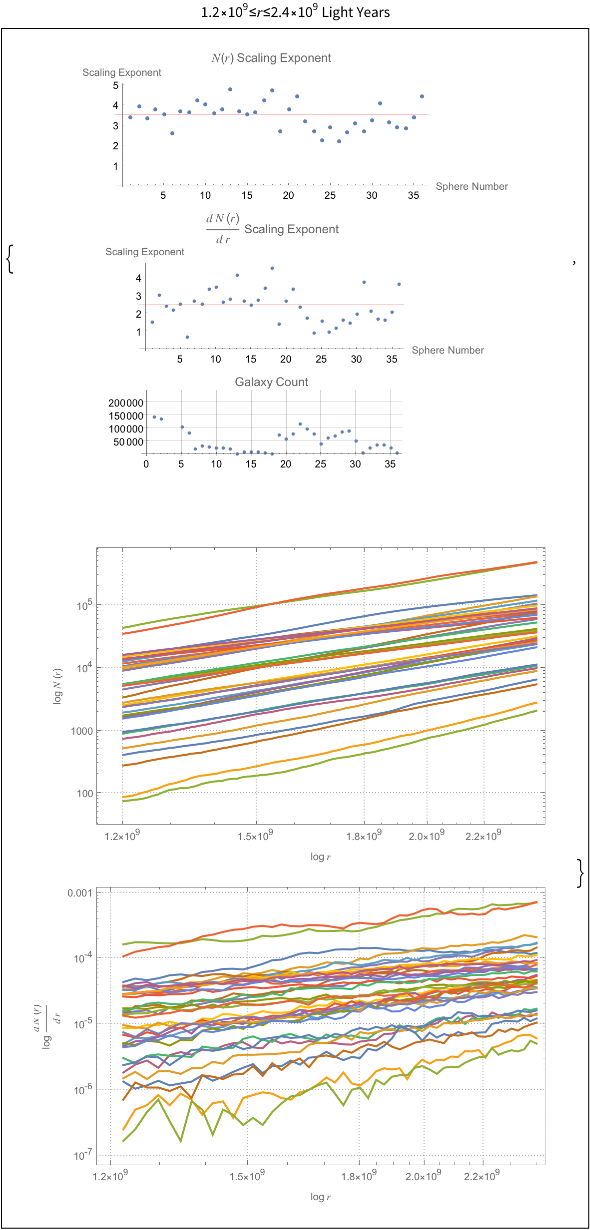
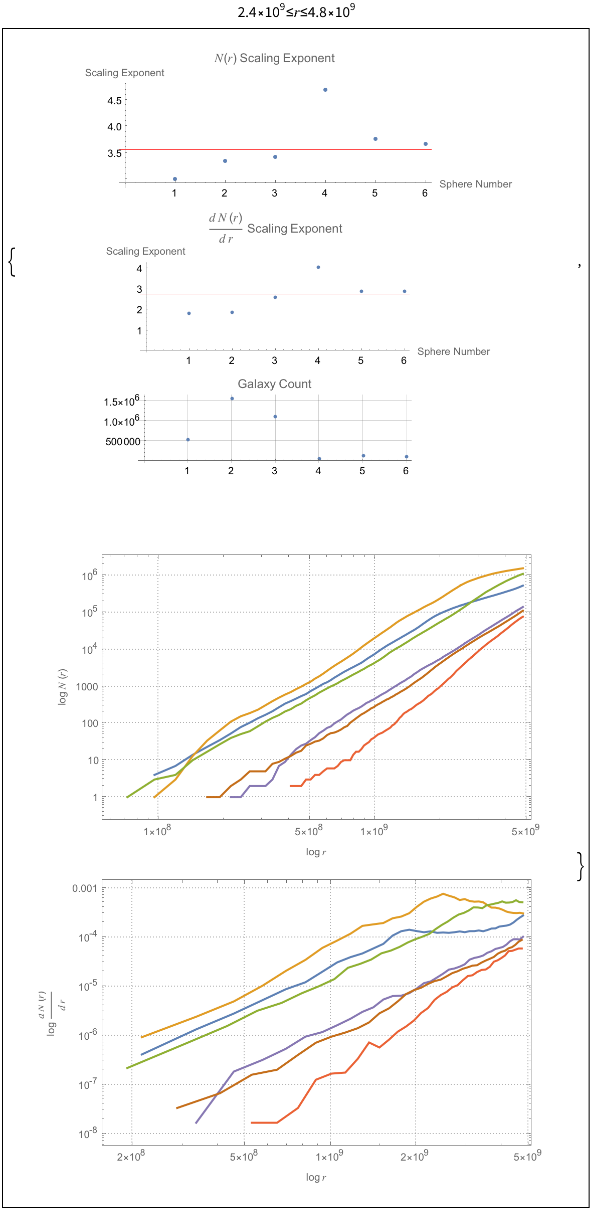
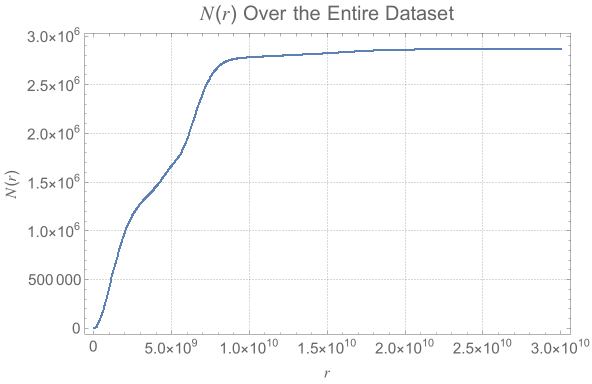
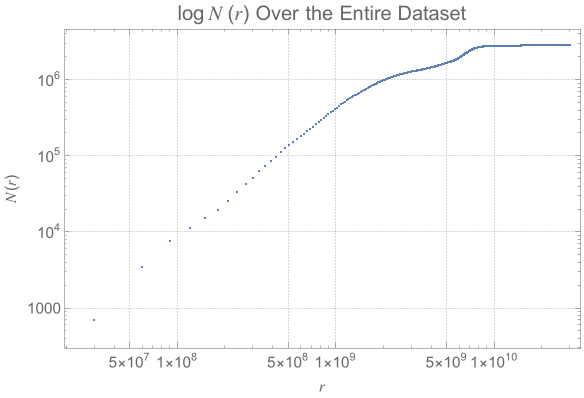
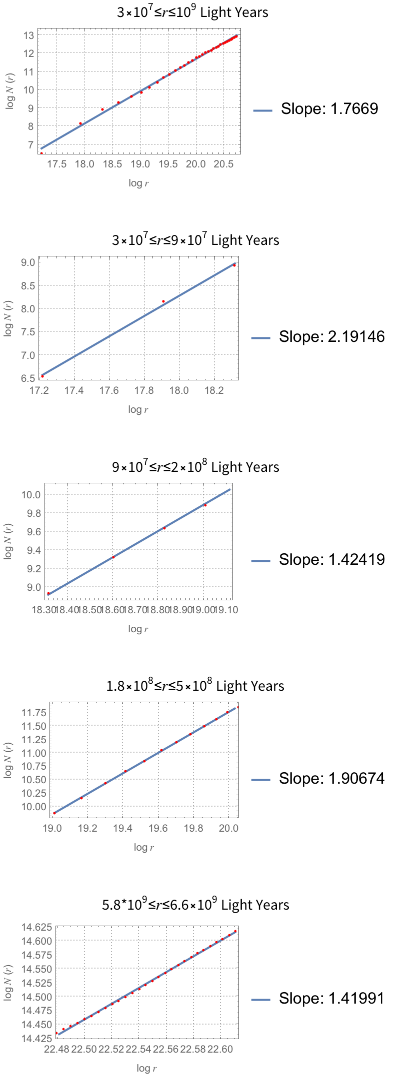
The power law scaling of galaxy distributions sourced from HyperLEDA are measured using growing spherical shells. Measurements are performed in isolation as well as in a three dimensional grid configuration using hundreds of shells. It is found that the power law exponent is not uniform in isolation, but will always cluster around a particular value when repeated enough times using a sphere radius that is not too large. The results found are unsurprising, and typically center around the expected values of , and ∝, but exceed these values for light years. The explanation for such a deviation can likely be explained by the introduction of large scale structures in the spheres causing a lack of uniformity in the distributions.
N(r)∝
3
r
dN(r)
dr
2
r
r>1.2
9
10