This project uses LLMs to review student work samples, specifically ACT writing essays. First, I explore using LLMs to apply a descriptive grading rubric which maps descriptions of writing quality to quantitative scores. Second, I use LLMs and the approach of Few-Shot Learning to perform GEC, Grammatical Error Correction, which is the process of identifying and fixing errors in the categories of spelling, punctuation, grammar, and word choice.
For most of the writing samples, the LLM was able to accurately asses the correct score, however each test produced some inaccurate and inconsistent results. I see several opportunities for further experimentation which may lead to performance adequate for practical use such as varying temperature, preening effective examples for few-shot learning, and implementing multiple calls to LLMs to disambiguate scores which vary by a single point.
For the GEC task utilizing Few-Shot Learning, the LLMs showed a generally powerful ability to find errors and return them in a structured data format. However, the LLMs also “hallucinated” several false errors. In practice, a combination of traditional GEC tools with LLM-powered reviews will likely lead to the best results.
LLMs currently have the power and flexibility to provide useful reviews of student work samples, but the tools which I believe will succeed in practice will be those which add additional computational power and human judgement to LLM-powered workflows.
For most of the writing samples, the LLM was able to accurately asses the correct score, however each test produced some inaccurate and inconsistent results. I see several opportunities for further experimentation which may lead to performance adequate for practical use such as varying temperature, preening effective examples for few-shot learning, and implementing multiple calls to LLMs to disambiguate scores which vary by a single point.
For the GEC task utilizing Few-Shot Learning, the LLMs showed a generally powerful ability to find errors and return them in a structured data format. However, the LLMs also “hallucinated” several false errors. In practice, a combination of traditional GEC tools with LLM-powered reviews will likely lead to the best results.
LLMs currently have the power and flexibility to provide useful reviews of student work samples, but the tools which I believe will succeed in practice will be those which add additional computational power and human judgement to LLM-powered workflows.
Applying a Descriptive Evaluation Rubric
Applying a Descriptive Evaluation Rubric
For the ACT Writing test, students are instructed to write an essay in response to a prompt. Two trained (human) evaluators score the essays from 1 to 6, in increments of 1, across each of four categories: (1) Ideas and Analysis, (2) Development and Support, (3) Organization, and (4) Language Use. The overall score is the rounded sum of the four category scores.
Note that for reporting purposes, the ACT score is reported as the sum of the essay score as graded by two separate graders, thus the reported range includes integers from 2 to 12. If the two graders report scores differing by more than 1, a third grader is consulted to resolve the scoring discrepancy (although the exact procedure for resolution is not reported on the ACT website) .
In this experiment, I use six ACT Writing sample essays and the official evaluation rubric, all provided by the creator of the test, ACT, Inc. Each of the samples is numbered from 1 to 6. The sample numbers used below correspond with the essay’s actual score, ranging from 1 (lowest) to 6 (highest).
To access the essays or rubric, follow these links: Essays, Rubric
Note that for reporting purposes, the ACT score is reported as the sum of the essay score as graded by two separate graders, thus the reported range includes integers from 2 to 12. If the two graders report scores differing by more than 1, a third grader is consulted to resolve the scoring discrepancy (although the exact procedure for resolution is not reported on the ACT website) .
In this experiment, I use six ACT Writing sample essays and the official evaluation rubric, all provided by the creator of the test, ACT, Inc. Each of the samples is numbered from 1 to 6. The sample numbers used below correspond with the essay’s actual score, ranging from 1 (lowest) to 6 (highest).
To access the essays or rubric, follow these links: Essays, Rubric
Assigning an Overall Score
Assigning an Overall Score
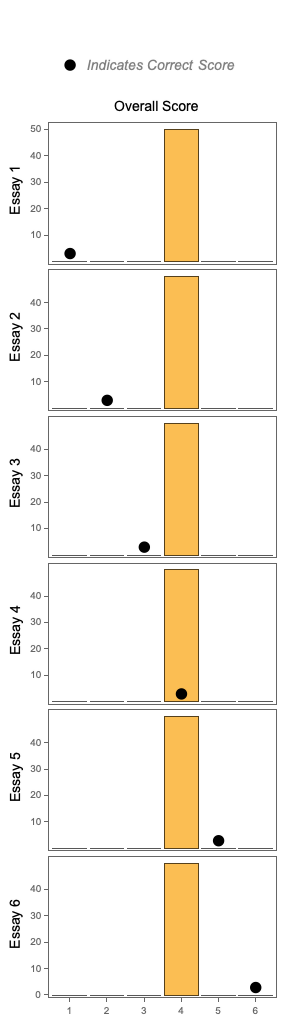
Each essay is sent in a separate request to the LLM which is instructed to return an overall score from 1 to 6, but no rubric is provided. Without the rubric, the LLM doesn’t distinguish at all by actual score and seems to “just pick” 4, regardless of the quality of the essay sample. While I found this surprising, I do appreciate that the LLM had such consistent behavior as a starting point, allowing for a clear signal of improvement in future experiments.
The real reason for choosing 4 is unclear, but perhaps the LLM “learned” this from a common human behavior when rating quality on integer scales. For example, the popular NPS (Net Promoter Score) metric uses results from a survey in which users of a product rate the product on an integer scale from 1 to 10. Scores of 7 and 8 are so common that users of the NPS metric ignores those scores as they represent “passives” who do not have a strong opinion. Perhaps the LLM “decided” to take a similarly passive approach.
The real reason for choosing 4 is unclear, but perhaps the LLM “learned” this from a common human behavior when rating quality on integer scales. For example, the popular NPS (Net Promoter Score) metric uses results from a survey in which users of a product rate the product on an integer scale from 1 to 10. Scores of 7 and 8 are so common that users of the NPS metric ignores those scores as they represent “passives” who do not have a strong opinion. Perhaps the LLM “decided” to take a similarly passive approach.
Essay scores, no rubric (N=50, GPT-3.5-Turbo, Temperature=1)
LLMFunction["Report a single score for this essay from 1 to 6 in this format: score",Expression]
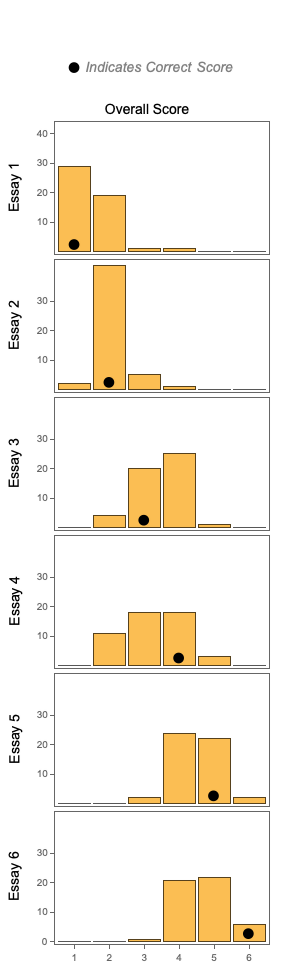
The same experiment is run again, but this time, the rubric is provided to the LLM at inference time. The results show that the LLM was able to learn how to grade the essays, but the results are somewhat inaccurate and inconsistent.
Essay scores, full rubric (N=50, GPT-3.5-Turbo, Temperature=1)
LLMFunction["You are the best professional evaluator for ACT writing samples. You are consistent, fair, and thorough in your evaluations. Use the following rubrics as guides. Report a single score for the whole essay from 1 to 6 in this format: score. Do not report a score for each category - this is very important - don't report a per-category score, just report a score for the entire essay."<>"Ideas and Analysis: "<>ToString[ideasAndAnalysisRubric]<>"Development and Support: "<>ToString[developmentAndSupportRubric]<>"Organization"<>ToString[organizationRubric]<>"Language Use"<>ToString[languageUseRubric]<>"Essay:``",Expression,LLMEvaluator-><|"Temperature"->1,"Model"->"gpt-3.5-turbo"|>]
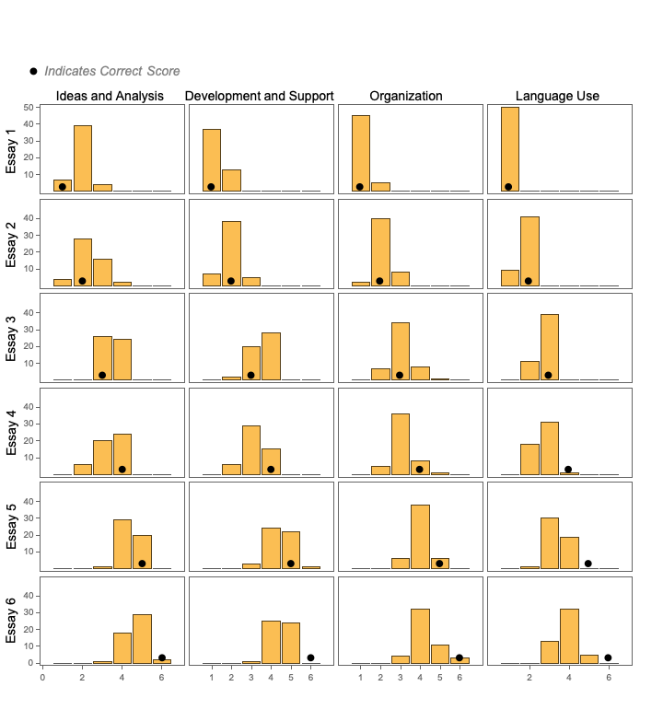
Assigning Category Scores
Assigning Category Scores
In an attempt to increase accuracy and consistency, the LLM is asked to score the essays by category. The LLM was quite effective in evaluating the low-scoring samples (Essay 1, Essay 2), but struggled with the high-scoring samples (Essay 5, Essay 6).
Per-category scores, full rubric (N=50, GPT-3.5-Turbo, Temperature=1)
LLMFunction["You are the best professional evaluator for ACT writing samples. You are consistent, fair, and thorough in your evaluations. Report a single score for each category, from 1 to 6, for the essay by applying the following rubrics. Report the scores in this format: <|\"Ideas and Analysis:\" -> \"score\", \"Development and Support\" -> \"score\", \"Organization\" -> \"score\", \"Language Use\" -> \"score\"|>"<>"Ideas and Analysis: "<>ToString[ideasAndAnalysisRubric]<>"Development and Support: "<>ToString[developmentAndSupportRubric]<>"Organization"<>ToString[organizationRubric]<>"Language Use"<>ToString[languageUseRubric]<>"Essay:``",Expression,LLMEvaluator-><|"Temperature"->1,"Model"->"gpt-3.5-turbo"|>];
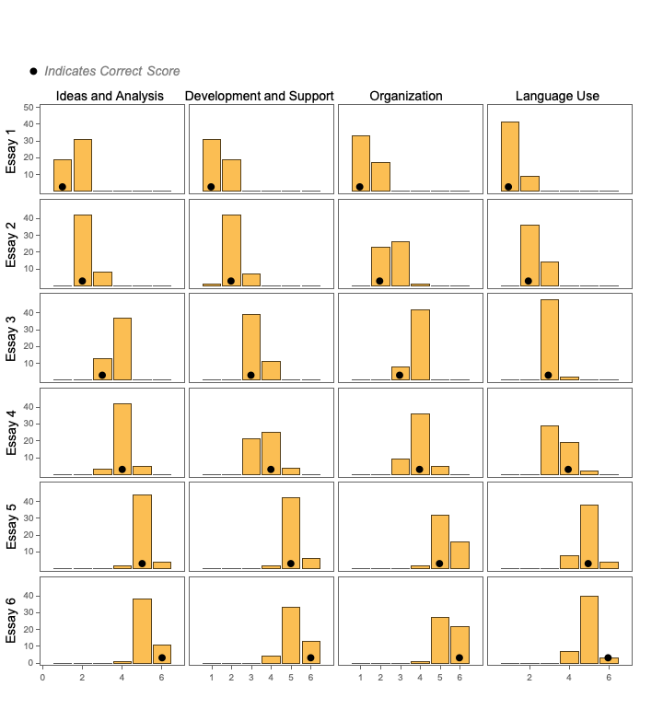
The experiment was run again with GPT-4, which resulted in better performance.
Per-category scores, full rubric (N=50, GPT-4, Temperature=1)
LLMFunction["You are the best professional evaluator for ACT writing samples. You are consistent, fair, and thorough in your evaluations. Report a single score for each category, from 1 to 6, for the essay by applying the following rubrics. Report the scores in this format: <|\"Ideas and Analysis:\" -> \"score\", \"Development and Support\" -> \"score\", \"Organization\" -> \"score\", \"Language Use\" -> \"score\"|>"<>"Ideas and Analysis: "<>ToString[ideasAndAnalysisRubric]<>"Development and Support: "<>ToString[developmentAndSupportRubric]<>"Organization"<>ToString[organizationRubric]<>"Language Use"<>ToString[languageUseRubric]<>"Essay:``",Expression,LLMEvaluator-><|"Temperature"->1,"Model"->"gpt-4"|>];
Again using GPT-4, the LLM’s “temperature” was lowered to 0. Results were more consistent, but quite inaccurate for Essay 6.
Per-category scores, full rubric (N=25, GPT-4, Temperature=0)
LLMFunction["You are the best professional evaluator for ACT writing samples. You are consistent, fair, and thorough in your evaluations. Report a single score for each category, from 1 to 6, for the essay by applying the following rubrics. Report the scores in this format: <|\"Ideas and Analysis:\" -> \"score\", \"Development and Support\" -> \"score\", \"Organization\" -> \"score\", \"Language Use\" -> \"score\"|>"<>"Ideas and Analysis: "<>ToString[ideasAndAnalysisRubric]<>"Development and Support: "<>ToString[developmentAndSupportRubric]<>"Organization"<>ToString[organizationRubric]<>"Language Use"<>ToString[languageUseRubric]<>"Essay:``",Expression,LLMEvaluator-><|"Temperature"->0,"Model"->"gpt-4"|>];
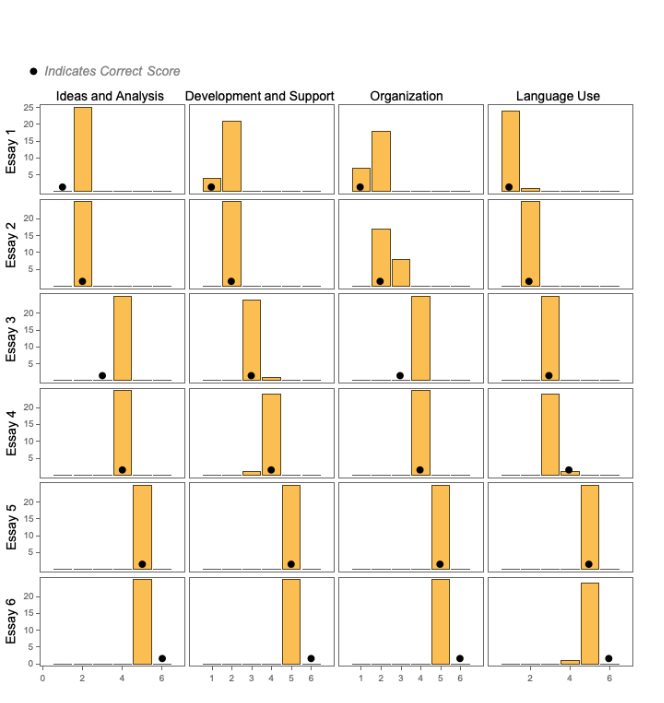
Just by using GPT-4 with a temperature of 0, we achieve results that I suspect rival those of trained groups of human graders - with the exception of assigning scores to Essay 6. How might one fix this in practice? Perhaps the essay can be sent to a second LLM which specifically has instructions for how to disambiguate essays of score 5 and 6. Although the regular human workflow for evaluating these essays includes a single review by two separate human, the use of LLMs allows for significantly more sophisticated workflows that can involve an arbitrary number of LLM requests.
After running these experiments, I’m struck by two conclusions: (1) LLMs have a powerful ability to follow inference-time instructions for scoring student work samples, (2) to get results that are good enough to use in practice, one needs to carefully test and curate prompts and workflows that can achieve greater-than-human performance.
After running these experiments, I’m struck by two conclusions: (1) LLMs have a powerful ability to follow inference-time instructions for scoring student work samples, (2) to get results that are good enough to use in practice, one needs to carefully test and curate prompts and workflows that can achieve greater-than-human performance.
Other types of evaluations
Other types of evaluations
I chose to experiment with the task of using a descriptive rubric to evaluate student essays because it’s a particularly challenging task. There’s not a “correct” answer, only essays which may or may not have responses with certain qualities like strong “Ideas and Analysis” and proper “Language Use”. Even with this somewhat ambiguous task and inference time instructions, the LLM was able to produce human-like results.
For evaluating other types of student work samples, such as short answer responses which correspond to questions that do have correct answers, I suspect that the LLM will rather easily provide human-like or better-than-human results. For example, teacher may have have students write short answer (1-2 sentences) responses to a set of 20 questions about a particular topic. While grading the responses, the teacher will have in their head some context about what concepts represent a correct answer and what misconceptions are most common in incorrect answers. The teacher will also have a set of heuristics for how many numerical points each concept is worth, how many points to reduce a score for small errors, etc.
If a teacher were to write out this context, a prompt could be created which knows about what the correct answer is, what concepts are involved, what mistakes are common, and how to deduct points for different types of mistakes. Given a product which allows users to give this sort of input, one can imagine allowing the teacher to have the LLM grade each question by each student and return scores and commentary for each. If needed, the tool could then also show distributions of performance for different questions or concepts, different student populations, etc.
For evaluating other types of student work samples, such as short answer responses which correspond to questions that do have correct answers, I suspect that the LLM will rather easily provide human-like or better-than-human results. For example, teacher may have have students write short answer (1-2 sentences) responses to a set of 20 questions about a particular topic. While grading the responses, the teacher will have in their head some context about what concepts represent a correct answer and what misconceptions are most common in incorrect answers. The teacher will also have a set of heuristics for how many numerical points each concept is worth, how many points to reduce a score for small errors, etc.
If a teacher were to write out this context, a prompt could be created which knows about what the correct answer is, what concepts are involved, what mistakes are common, and how to deduct points for different types of mistakes. Given a product which allows users to give this sort of input, one can imagine allowing the teacher to have the LLM grade each question by each student and return scores and commentary for each. If needed, the tool could then also show distributions of performance for different questions or concepts, different student populations, etc.
GEC (Grammatical Error Correction)
GEC (Grammatical Error Correction)
Traditional GEC systems, often referred to as “spellcheck” software, use a combination of replacement rules, such as for misspelled words, and machine learning models trained on datasets of text samples with errors. Typically, these text samples are created by starting with a grammatically correct sentence and introducing a mistake, recording that mistake as a “tag” for the machine learning training process, and testing the GEC system on a corpus of millions of such examples.
This type of spellcheck software is effective across many types of errors, but when several errors are seen in combination, such as in a low-quality writing sample, the spellcheck software struggles to identify compositions of errors and possible solutions. These GEC systems are also not able to use semantic meaning as context within a text sample, which can lead to both false negative and false positive mistakes.
This type of spellcheck software is effective across many types of errors, but when several errors are seen in combination, such as in a low-quality writing sample, the spellcheck software struggles to identify compositions of errors and possible solutions. These GEC systems are also not able to use semantic meaning as context within a text sample, which can lead to both false negative and false positive mistakes.
Local “error context” and returning structured data from an LLM
Local “error context” and returning structured data from an LLM
One difficulty of measuring the performance of GEC software for student work samples is that no existing system can be relied upon to find all errors. Therefore I manually created a list of each error and a suggested fix for all six essays. A second challenge is that because the LLM is instructed to return the error within a Wolfram Language rule structure, the LLM must choose an “error context” which may differ from the one I chose. For example, the same error could be fixed using different rules where the “error context” is either “they’re book” or just “they’re”:
"they're book"->"their book"
Or, equivalently:
"they're"->"their"
In order to determine whether a GEC program found and corrected the error, I used two approaches for Essay 1. The first approach was to manually review the results returned by the LLM at K = {1, 5, 10, 20}. The second was to match the “error context” values from the manually created key to the values returned by the LLM. As seen in the plot for Essay 1, the automated detection generally performed quite well below K=20.
This matching of “error context” demonstrated the ability of the LLM to follow the examples provided to it for Few-Shot Learning. The LLM correctly identified the error context for simple situations such as misspelled words by returning just the word and for situations in which two or more words constituted the expected “error context”. This automated detection was used for estimating the GEC performance for the remaining essay samples.
This matching of “error context” demonstrated the ability of the LLM to follow the examples provided to it for Few-Shot Learning. The LLM correctly identified the error context for simple situations such as misspelled words by returning just the word and for situations in which two or more words constituted the expected “error context”. This automated detection was used for estimating the GEC performance for the remaining essay samples.
GEC Results vs. K, (the number of Few-Shot Learning examples) across Essays 1 to 6
GEC Results vs. K, (the number of Few-Shot Learning examples) across Essays 1 to 6
But using GPT-3.5-Turbo and increasing K, the number of examples provided at inference time for Few-Shot Learning, results comparable to a modern spellcheck system were obtained.
False negatives, positives per real error vs. K
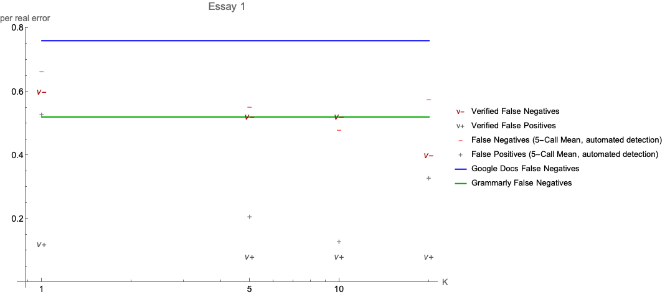
For Essays 2 through 4, the LLM showed similar or worse performance than popular, commercial GEC software.
False negatives per real error vs. K
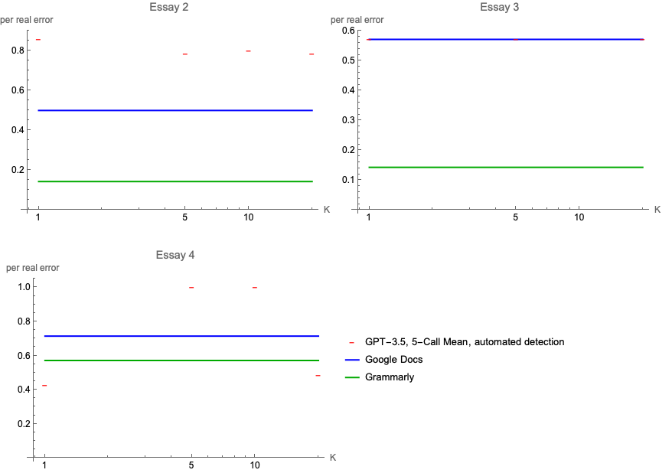
For the high-quality writing samples, the LLM was not able to find errors as well as commercial GEC software.
False negatives, positives per real error vs. K
Out[]=
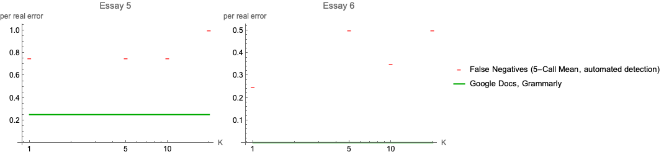
The LLM demonstrated the ability to return data in a structured format when provided with examples for Few-Shot Learning. However, the lack of identification of common grammatical and spelling errors, especially in high-quality writing samples, suggests that the LLM might be best used as an aid to a rules-based approach to GEC.
Overall, these GEC experiments were very preliminary in terms of the use of LLMs. Further experimentation of varying the temperature, the prompt, the examples used for Few-Shot Learning, and the use of multiple LLM calls in various sequences may provide greatly improved performance. Additionally, due to the LLM’s ability to successfully follow instructions for returning structured data with appropriate context, tools such as a “fact-checker” could be implemented in a similar manner as the GEC solution presented here.
Overall, these GEC experiments were very preliminary in terms of the use of LLMs. Further experimentation of varying the temperature, the prompt, the examples used for Few-Shot Learning, and the use of multiple LLM calls in various sequences may provide greatly improved performance. Additionally, due to the LLM’s ability to successfully follow instructions for returning structured data with appropriate context, tools such as a “fact-checker” could be implemented in a similar manner as the GEC solution presented here.
UI Markup
UI Markup
For the task of showing a user what changes were made, an early mockup of a UI is shown below. The main method for displaying the changes made is the use of the Wolfram Language’s ability to performing sequence matching for string characters as implemented in the following Resource Function.
This UI is illustrative but could be significantly improved by allowing the user to accept or reject a change, by showing the sequences more clearly, and by giving a summary of the types of errors found.
This UI is illustrative but could be significantly improved by allowing the user to accept or reject a change, by showing the sequences more clearly, and by giving a summary of the types of errors found.
essay1=;
essay1Fixed=;
Use HighlightTextDifferences to display text edits to the user
In[]:=
Column[{Text[Style[essay1,"TextStyling"]],ResourceFunction["HighlightTextDifferences"][essay1,essay1Fixed],Text[Style[essay1Fixed,"TextStyling"]]},Frame->All]
Out[]=
Well Machines are good but they take people jobs like if they don’t know how to use it they get fired and they’ll find someone else and it’s more easyer with machines but sometimes they don’t need people because of this machines do there own job and there be many people that lack on there job but the intelligent machines sometimes may not work or they’ll brake easy and it’s waste of money on this machines and there really expensive to buy but they help alot at the same time it help alot but at the same time this intelligent machines work and some don’t work but many store buy them and end up broken or not working but many stores gets them and end up wasting money on this intelligent machines’ but how does it help us and the comunity because some people get fired because they do not need him because of this machines many people are losing job’s because of this machines. |
Well, Mmachines are good, but they take people's jobs like. iIf they don’'t know how to use ithem, they get fired, and they’ll find someone else andwill be hit’sred. moreIt's easyier with machines, but sometimes they don’'t need people because of thiese machines can do there own job aond theire beown. mMany people thlatck skilackls fonr theire job buts, theand intelligent machines sometimes may not always work or themay’ll breake easy andily. iIt’'s a waste of money on thiso machinvest aind therse really expensive to buymachines. butHowever, they can be help afulot at the same time. itThey help a lot, but at the same time, thissome intelligent machines work andwhile somthers don’'t work but. mMany stores buy them, abut they oftend end up broken or not working but many. sStores gets them and end up wastinge money on thiese intelligent machines’ but. hHow does it help us and the community because? sSome people get fired because they doare not lonegedr him bneedecad duse tof thiese machines. mMany people are losing job’s because of this machinesm. |
Well, machines are good, but they take people's jobs. If they don't know how to use them, they get fired, and someone else will be hired. It's easier with machines, but sometimes they don't need people because these machines can do the job on their own. Many people lack skills for their jobs, and intelligent machines may not always work or may break easily. It's a waste of money to invest in these expensive machines. However, they can be helpful at the same time. They help a lot, but at the same time, some intelligent machines work while others don't. Many stores buy them, but they often end up broken or not working. Stores waste money on these intelligent machines. How does it help us and the community? Some people get fired because they are no longer needed due to these machines. Many people are losing jobs because of them. |
Concluding remarks
Concluding remarks
These experiments tested two different tasks - evaluation using a descriptive rubric and GEC. In both, the LLMs performance showed remarkable flexibility to perform tasks as instructed at inference time, but lacked the level of accuracy and consistency needed for widespread use as a product. These results illustrate the need for computational power within product workflows both before and after the LLM calls in order to bridge the gap between the “out-of-the-box” LLM performance and users’ needs.
Today, we typically have only “raw” interactions with the LLM as a processing “kernel”, but I expect to be able to soon work with much more sophisticated and useful tools and workflows that have this LLM “kernel” as one very powerful and interesting processing step. I expect that there are many improvements to be found by both doing “LLM Science” to study the behavior of these AI systems and by developing creative, simple-to-use products which allow users the ability to easily perform tasks which previously were required intensive application of focused human thought.
Today, we typically have only “raw” interactions with the LLM as a processing “kernel”, but I expect to be able to soon work with much more sophisticated and useful tools and workflows that have this LLM “kernel” as one very powerful and interesting processing step. I expect that there are many improvements to be found by both doing “LLM Science” to study the behavior of these AI systems and by developing creative, simple-to-use products which allow users the ability to easily perform tasks which previously were required intensive application of focused human thought.
Keywords
Keywords
◼
LLM
◼
Few-Shot Learning
Acknowledgment
Acknowledgment
Thanks to the many Wolfram Summer School staff members and students who helped with this project:
Sotiris Michos - for thinking through experimental approaches, reviewing many drafts of notebooks, providing encouragement and celebration, and setting up discussions related to this project with varied groups
Fez Zaman - for helping with data wrangling and visualization and discussing the potential use of multiway paths for grammatical error corrections
Ghassane Aniba - for discussing experiments to run and prompts to use
Bob Nachbar - for help generating graphics
Eric Parfitt- for helping refactor code and creating sensible results plots
Paul Abbot and Mark Greenberg - for discussion on the use of LLMs for teaching and many ideas for practical extensions of the areas explored in this project
Jofre Espigule - for providing a particularly helpful guide to LLM Functionality in the Wolfram Language and discussing prompting techniques
Christopher Wolfram - for discussing details of the LLMTool implementation and intuition about the interactions between LLMs and the Wolfram Language
Sotiris Michos - for thinking through experimental approaches, reviewing many drafts of notebooks, providing encouragement and celebration, and setting up discussions related to this project with varied groups
Fez Zaman - for helping with data wrangling and visualization and discussing the potential use of multiway paths for grammatical error corrections
Ghassane Aniba - for discussing experiments to run and prompts to use
Bob Nachbar - for help generating graphics
Eric Parfitt- for helping refactor code and creating sensible results plots
Paul Abbot and Mark Greenberg - for discussion on the use of LLMs for teaching and many ideas for practical extensions of the areas explored in this project
Jofre Espigule - for providing a particularly helpful guide to LLM Functionality in the Wolfram Language and discussing prompting techniques
Christopher Wolfram - for discussing details of the LLMTool implementation and intuition about the interactions between LLMs and the Wolfram Language
References
References
◼
The full set of experiments used in this project is available in the Notebook Archive - https://notebookarchive.org/2023-07-5kv909m
◼
CITE THIS NOTEBOOK
CITE THIS NOTEBOOK
LLM-powered reviews of student work samples
by Aaron Carver
Wolfram Community, STAFF PICKS, July 12, 2023
https://community.wolfram.com/groups/-/m/t/2958774
by Aaron Carver
Wolfram Community, STAFF PICKS, July 12, 2023
https://community.wolfram.com/groups/-/m/t/2958774