This paper aims to explore the relationship between the activity of large language models (LLMs) using the GPT2 transformer and the activation maps of functional MRI (fMRI) voxels. We manipulate the embedding layers of the LLM to adjust the activity of the model based on single-word text input and examined slices of the activity array. We visualize the density plots of fMRI voxels across nine participants tested on the same set of word inputs. Taking the average of the mean-difference for the image lists for the model and fMRI plots, we determine that variance in the activation of the right putamen is associated with lower-level language processing. Furthermore, we connect this finding with our observations of the LLM, as the activity of first hidden layer, responsible for generating the first probabilities after language passing, varied significantly. We also discuss areas for further exploration, including vector analysis of input sets, numerical prompts, and sentence comprehension.
Introduction
Introduction
While the number of applications of machine learning and artificial intelligence tools — spearheaded by Open AI’s Chat-GPT platform — has grown significantly in popularity over the past decade, further work exploring the internal systems that guide the outcomes of these applications is necessary (Furman & Seamans, 2019). Although fundamental research on the creation of principal node-based machine learning algorithms like convolutional neural networks (CNNs), multilayer perceptrons (MLPs), and large language models (LLMs) is established, stigma exists towards the in-field applications of machine learning models because of their perception as “black boxes,” unable to be meaningfully interpreted and analyzed (Ivakhnenko & Lapa, 1965; Watson ets al., 2019).
However, recent studies have substantiated many of the basic mechanisms of machine learning models through their ties to brain function found in functional MRI (fMRI) scans. In particular, multiple papers have demonstrated the correlation between computer vision algorithms built on CNNs and activation patterns in the Brodmann regions of the brain (Cox & Dean, 2014; Greer, 2007; Soni & Waoo, 2023). Furthermore, artificial neural networks (ANNs) have shown greater resemblance in the activity of human language processing in Broca’s area and, broadly, the motor cortex than the classical Wernicke-Geschwind model (Cuccio et al., 2022; Nasios et al., 2019).
We can similarly investigate the usage of LLMs, rooted in the probabilistic connection of neural net layers, to connect model structures to language functions in the brain. Within the past year, articles have discussed and corroborated the competency of LLMs in replicating language output based on specific, short dialog tasks (Sejnowski, 2023; Zhao et al., 2023). To further the development of LLMs, it is crucial that connections are drawn to the neurological systems found in nature to refine the accuracy and enable proper scaling of the models.
Thus, in this paper, we evaluate the utilization of the ChatGPT-2 transformer-based LLM to relate the plots of nodal layer activity within the model to variation in density slice images of fMRI voxels. To analyze this relationship, we visualize the activation variance, especially in the right putamen, over a set of nine healthy study participants, each scanned for prompts spanning 360 distinct words. We base our functional analysis on the fMRI voxel dataset from CCBI at Carnegie Mellon University, as implemented in Pereira et al.’s 2011 study at Princeton University (Mitchell et al., 2008; Pereira et al., 2011).
However, recent studies have substantiated many of the basic mechanisms of machine learning models through their ties to brain function found in functional MRI (fMRI) scans. In particular, multiple papers have demonstrated the correlation between computer vision algorithms built on CNNs and activation patterns in the Brodmann regions of the brain (Cox & Dean, 2014; Greer, 2007; Soni & Waoo, 2023). Furthermore, artificial neural networks (ANNs) have shown greater resemblance in the activity of human language processing in Broca’s area and, broadly, the motor cortex than the classical Wernicke-Geschwind model (Cuccio et al., 2022; Nasios et al., 2019).
We can similarly investigate the usage of LLMs, rooted in the probabilistic connection of neural net layers, to connect model structures to language functions in the brain. Within the past year, articles have discussed and corroborated the competency of LLMs in replicating language output based on specific, short dialog tasks (Sejnowski, 2023; Zhao et al., 2023). To further the development of LLMs, it is crucial that connections are drawn to the neurological systems found in nature to refine the accuracy and enable proper scaling of the models.
Thus, in this paper, we evaluate the utilization of the ChatGPT-2 transformer-based LLM to relate the plots of nodal layer activity within the model to variation in density slice images of fMRI voxels. To analyze this relationship, we visualize the activation variance, especially in the right putamen, over a set of nine healthy study participants, each scanned for prompts spanning 360 distinct words. We base our functional analysis on the fMRI voxel dataset from CCBI at Carnegie Mellon University, as implemented in Pereira et al.’s 2011 study at Princeton University (Mitchell et al., 2008; Pereira et al., 2011).
LLM Extraction and Manipulation
LLM Extraction and Manipulation
We start by extracting the transformer-based GPT2 LLM, trained using a causal language modeling (CLM) objective (Radford et al., 2019). The CLM approach facilitates the movement from layer-to-layer in the LLM with a transformer, eventually resulting in word generation output based on highest calculated probabilities.
In[]:=
gpt2=NetModel["GPT2 Transformer Trained on WebText Data"];NetExtract[gpt2,"embedding"]
Out[]=
NetGraph

In essence, the GPT2 LLM is composed of connected layers of neural networks, defined by 1.5 billion parameters and pre-trained on 8 million webpages. The LLM takes input as a vector of n tokens, represented by integer values ranging from 1 to 50,257. Then, all n tokens are converted by a single-layer neural net into an “embedding” vector of a length of 768. Simultaneously, a “secondary pathway” takes the list of integer positions and creates another matching embedding vector. The two token value embedding vectors and token position are combined through a threading layer, producing the final sequence of embedding vectors from the module. An example of this node-level process is visualized below for operation on the repeated binary input happy sad happy sad happy sad happy sad happy sad (Lee et al., 2021):
In[]:=
Module[{matrixPlot},matrixPlot[matrix_?MatrixQ]:=Labeled[MatrixPlot[Take[Transpose@matrix,30],Mesh->True,ImageSize->170,Frame->None],"⋮"];Row[Riffle[matrixPlot/@Values@NetModel["GPT2 Transformer Trained on WebText Data"]["happy sad happy sad happy sad happy sad happy sad happy sad happy sad happy sad happy sad happy sad",{NetPort[{"embedding","embeddingtokens"}],NetPort[{"embedding","embeddingpos"}],NetPort[{"embedding"}]}],Style[#,18,Gray,Bold]&/@{"+",""}],Spacer[5]]]
Out[]=
⋮ |

+
⋮ |

⋮ |
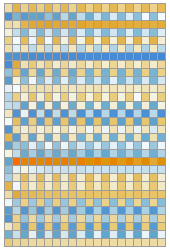
After the embedding module is operated upon as shown, a sequence of 12 “attention blocks” is rippled through. Below is a schematic representation of a singular attention block:
In[]:=
Information[NetFlatten@NetExtract[NetModel["GPT2 Transformer Trained on WebText Data"],{"decoder",1}],"FullSummaryGraphic"]
Out[]=
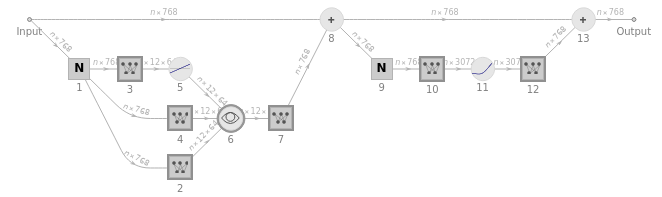
Within each of the 12 attention blocks, there are 12 “attention heads,” distinctly operating on separate segments of the embedding vector. These heads recombine the embedding vectors associated with different tokens and certain weights by looking backward in the LLM, creating patterns of “recombination weights.” The resulting vector is subsequently passed through a fully-connected linear neural layer. We show the average of the 12 recombination layers of the LLM as a 64 by 64 temperature plot of moving averages of predictive probability:
In[]:=
MatrixPlot[Total[Table[MovingAverage[MovingAverage[#,64]&/@Normal@NetExtract[NetModel["GPT2 Transformer Trained on WebText Data"],{"decoder",x,"1","attention",1,"Net","Weights"}],64],{x,1,12}]],ColorFunction->ColorData["SouthwestColors"],PlotLegends->Automatic,ColorFunctionScaling->True,ImageSize->1->0.55]
Out[]=
Although the matrix of moving averages in the model helps us envision differences in adjacent weights by color, it is effectively randomized because of temperature preset of 0.8. Furthermore, the weights shown do not vary by the text input of the model, failing to capture variations in neuron layer activity. As a result, we manipulate the LLM embedding and decoding layers to accurately create images of input-dependent model activity. We start this manipulation by extracting the 12 individual decoding layers of the LLM:
In[]:=
decoderLayers=Table[NetExtract[gpt2,{"decoder",idx}],{idx,12}]
Out[]=
NetChain
,NetChain
,NetChain
,NetChain
,NetChain
,NetChain
,NetChain
,NetChain
,NetChain
,NetChain
,NetChain
,NetChain
We expand upon this by modifying the embeddings of the LLM based on text input, shown below using the word “Castle” from the information set of the data. Next, we take the last element of each of the 756 possible matrix slices we can take of the model’s activity, represented by hiddenProcessed and combining them as an interactive plot:
In[]:=
tokenizer=NetExtract[gpt2,"Input"];embedding=NetExtract[gpt2,"embedding"];embedded=embedding[tokenizer["Castle"]];current=embedded;hidden=Table[current=List[Last[layer[current]]];current,{layer,decoderLayers}];Dimensions[hidden];Dimensions[hidden[[;;,1,;;]]];hiddenProcessed=hidden[[;;,1,;;]];ArrayPlot[hiddenProcessed,ImageSize->1->1.15]Manipulate[hiddenSliced=hiddenProcessed[[;;,idx;;idx+12]];ArrayPlot[hiddenSliced],{idx,1,768-12},SaveDefinitions->True]
Out[]=

Out[]=



Of the 756 slices created of the modified decoder layers, we take the last slice as a benchmark for the node activity given an input string (Hurley et al., 2021). We plot the 12 by 13 array for each of the 360 word prompts and average the greyscale colors across all the images, corresponding with the neuron activation of fMRI scans found in each participant. An array plot for the first 10 words, followed by the mean activity plot for all words, are shown:
In[]:=
listOfWords=ToString/@Flatten[CloudImport["https://www.wolframcloud.com/obj/5c6f845c-bd6b-4662-8f2c-889448939421"]];tokenizedList=tokenizer/@listOfWords;embeddedList=embedding/@tokenizedList;Row[Table[ArrayPlot[Table[current=embedding[tokenizer[listOfWords[[indexval]]]];current=List[Last[layer[current]]];current,{layer,decoderLayers}][[;;,1,;;]][[;;,756;;768]],ImageSize->1->10],{indexval,1,5}],Spacer[10]]ArrayPlot[Mean[Table[Table[current=embedding[tokenizer[listOfWords[[indexval]]]];current=List[Last[layer[current]]];current,{layer,decoderLayers}][[;;,1,;;]][[;;,756;;768]],{indexval,1,360}]],ImageSize->1->28]
Out[]=





Out[]=

Moreover, we can explore the output caused by these probability mechanisms based on word prompt inputs. For example, we can ask the model to determine “a castle is a,” replicating the questions posed to the human participants of the study in the dataset. The LLM outputs the following unorganized association for the first 20 words:
In[]:=
NetModel[{"GPT2 Transformer Trained on WebText Data","Task"->"LanguageModeling"}]["A castle has the properties of",{"TopProbabilities",20}]
Out[]=
{:0.00242843, three0.00245123, such0.00252136, several0.0025817, all0.00261872, most0.00293549, "0.00397043, its0.00404791, any0.00425024, some0.00439668, castles0.00487895, many0.0055314, both0.00648421, one0.00670368, two0.00773144, having0.011109, the0.044703, being0.0679423, an0.0832382, a0.483881}
We can reorganize this association by reversed sorted order based on probability and clean it by removing duplicates and filtering for only noun synonyms.
In[]:=
Drop[Flatten[TextCases[Keys[Reverse[Sort[NetModel[{"GPT2 Transformer Trained on WebText Data","Task"->"LanguageModeling"}]["A castle has the properties of",{"TopProbabilities",200}],Values]]],"Noun"]],1]
Out[]=
{houses,castle,land,building,something,buildings,home,heaven,fort,rooms,space,magic,anything,homes,meeting,luxury,stone,house,cities,residence,housing,water,standing,power,life,property,fortress,temples,room,place,nobility,everything,royal,capital,nothing,apartments,towers,places,dwelling,paradise,mountains,farmland,city,lots,walls,towns,islands,fire,nature,complex,architecture,kings,king,dungeons,war,earth,half,hills,public,sanct}
This output mimics the human examples given in Pereira et al., as three human generated responses mentioned for “castle” were “cold, knights, and stone” (Pereira et al., 2011). Repeating this process for all 360 words, we find that mean regulation causes the model activity to generate outputs similar to humans for single-word inputs.
fMRI Voxel Data and Visualization
fMRI Voxel Data and Visualization
We begin by loading in the individual voxel data for the 9 participants, with a discrete plot of the points and voxel visualization for first participant:
In[]:=
VoxelData1=CloudImport["https://www.wolframcloud.com/obj/29f8f781-706c-4019-9dfc-e3dac59d67e8"];ListPointPlot3D[VoxelData1,ColorFunction->ColorData["SouthwestColors"],Axes->False]ListPlot3D[VoxelData1,ColorFunction->ColorData["SouthwestColors"],Axes->False]VoxelData2=CloudImport["https://www.wolframcloud.com/obj/1edbf7d6-13b6-4db5-a450-f6904fb45729"];VoxelData3=CloudImport["https://www.wolframcloud.com/obj/385009f7-2a28-4a41-be7e-a9e7ec74cf9b"];VoxelData4=CloudImport["https://www.wolframcloud.com/obj/1ce2a817-168d-4d0e-9d08-8cda7eeb4f1c"];VoxelData5=CloudImport["https://www.wolframcloud.com/obj/634b8283-7a7e-490b-8a8e-bc14facaf1ba"];VoxelData6=CloudImport["https://www.wolframcloud.com/obj/8a72681c-6441-49f3-aa1b-2a63d3e1c638"];VoxelData7=CloudImport["https://www.wolframcloud.com/obj/deb8610c-2397-4797-a345-e25b87e75d30"];VoxelData8=CloudImport["https://www.wolframcloud.com/obj/6d196cd9-164d-4fc1-9e62-2b9d98c0e7e1"];VoxelData9=CloudImport["https://www.wolframcloud.com/obj/d4e1a0ee-b0b8-4f82-8159-6a8ad14c95a0"];combinedVoxelData={VoxelData1,VoxelData2,VoxelData3,VoxelData4,VoxelData5,VoxelData6,VoxelData7,VoxelData8,VoxelData9};
Out[]=

Out[]=

We can create a list of the voxel visualizations for all 9 participants by repeating the plot function:
In[]:=
Map[ListPlot3D[#,ColorFunction->ColorData["SouthwestColors"],Axes->False]&,combinedVoxelData]
Out[]=
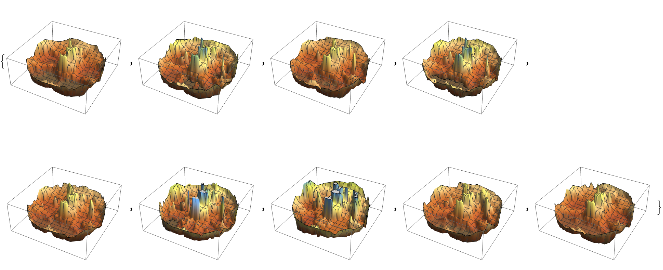
From this list of 3D plots, we can take the image of the corresponding 2D fMRI density cross-section plot:
In[]:=
imagesOfScans=Image/@ListDensityPlot/@combinedVoxelData
Out[]=

Iterating across these 9 density plots, we create a mean image of the activation for the participants in the study:
In[]:=
meanScan=Image[Mean[Rasterize/@Map[ImageResize[#,{256,256}]&,imagesOfScans]]];ImageResize[meanScan,550]
Out[]=
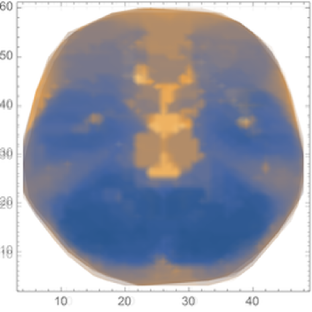
To simplify image comparison, we convert the previous images for each participant and the mean to greyscale colors:
In[]:=
grayImagesOfScans=ColorConvert[#,"Grayscale"]&/@imagesOfScansgrayMeanScan=ColorConvert[meanScan,"Grayscale"];ImageResize[grayMeanScan,550]
Out[]=

Out[]=

Intra-Comparative Analyses of LLM and fMRI Voxels
Intra-Comparative Analyses of LLM and fMRI Voxels
Intra-Comparative Analysis of LLM By Word
Intra-Comparative Analysis of LLM By Word
We start by comparing the activity plot for the first word (“refrigerator”) against the mean activity plot across all 360 words:
In[]:=
firstWordLLMActivity=Image[ArrayPlot[Table[current=embedding[tokenizer[listOfWords[[1]]]];current=List[Last[layer[current]]];current,{layer,decoderLayers}][[;;,1,;;]][[;;,756;;768]]]];meanLLMActivity=Image[ArrayPlot[Mean[Table[Table[current=embedding[tokenizer[listOfWords[[indexval]]]];current=List[Last[layer[current]]];current,{layer,decoderLayers}][[;;,1,;;]][[;;,756;;768]],{indexval,1,360}]]]];ImageDifference[ImageResize[firstWordLLMActivity,{550,500}],ImageResize[meanLLMActivity,{550,500}]]
Out[]=

Next, we can find the image difference between the mean and the activity plot for each of the 360 words:
In[]:=
averageDifferenceLLM=Table[ImageDifference[ImageResize[Image[ArrayPlot[Table[current=embedding[tokenizer[listOfWords[[x]]]];current=List[Last[layer[current]]];current,{layer,decoderLayers}][[;;,1,;;]][[;;,756;;768]]]],{550,550}],ImageResize[meanLLMActivity,{550,550}]],{x,1,360}];
A section for these results of the first 5 words against the mean is shown.
In[]:=
Table[ImageDifference[ImageResize[Image[ArrayPlot[Table[current=embedding[tokenizer[listOfWords[[x]]]];current=List[Last[layer[current]]];current,{layer,decoderLayers}][[;;,1,;;]][[;;,756;;768]]]],{550,550}],ImageResize[meanLLMActivity,{550,550}]],{x,1,5}]
Out[]=

Then, we take the average of these mean-difference plots across all words input in the model, plotted as 1000 by 1000 pixel image (with its color reverse adjacent):
In[]:=
IntraLLM=Image[Mean[Rasterize/@Map[ImageResize[#,{256,256}]&,averageDifferenceLLM]]];{ImageResize[IntraLLM,{1000,1000}],ImageResize[ColorNegate[IntraLLM],{1000,1000}]}
Out[]=

With the color-reversed image of the averaged mean-difference plot, we can perform image clustering to estimate areas of variance:
clusteredLLM=ColorizeImageClusteringComponents
,3

Out[]=

After cleaning the array image by trimming the last row (randomized direct output layer) and first rows (inactive layer), we are left with the following plot:
finalIntrafMRI=ImageCrop[clusteredLLM,{1000,810}];finalIntrafMRI=ImageCrop[finalIntrafMRI,980,Right];finalIntrafMRI=ImageCrop[finalIntrafMRI,960,Left]
Out[]=

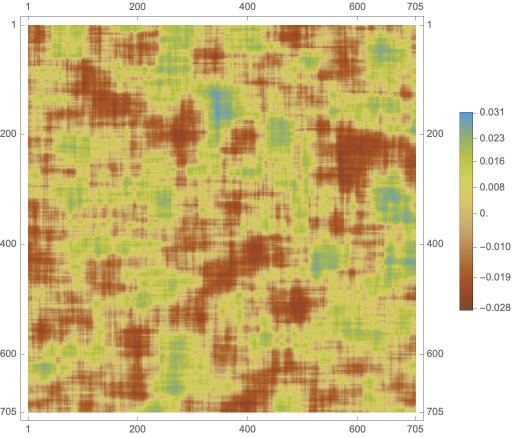
Finally, we plot modified axes, matching those of the fMRI plots, on the cleaned average mean-difference image.
In[]:=
Graphics[Inset[finalIntrafMRI,Scaled[{.5,.5}],Automatic,Scaled[1]],Frame->True,PlotRange->{{0,50},{0,60}},AspectRatio->ImageAspectRatio@finalIntrafMRI]
Out[]=
We find that the major variance in the average mean-difference plot for the model is generally between (4, 48) and (8, 54). We can interpret this as the first hidden layer within the LLM, primarily responsible for the initial stage of language processing from the information passed through first layer, according to previous work (Antholzer et al., 2018; Han et al., 2018).
Intra-Comparative Analysis of fMRI Voxels By Participant and Word
Intra-Comparative Analysis of fMRI Voxels By Participant and Word
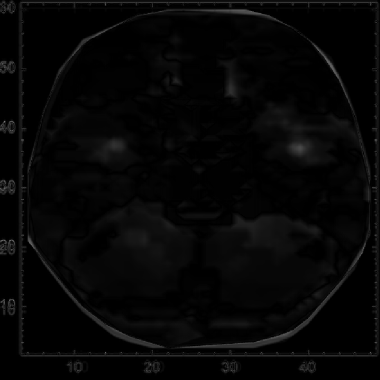
If we take the first fMRI image and compare it to the previous mean image, we find that the difference is:
In[]:=
ImageDifference[ImageResize[grayImagesOfScans[[1]],{550,550}],ImageResize[grayMeanScan,{550,550}]]
Out[]=
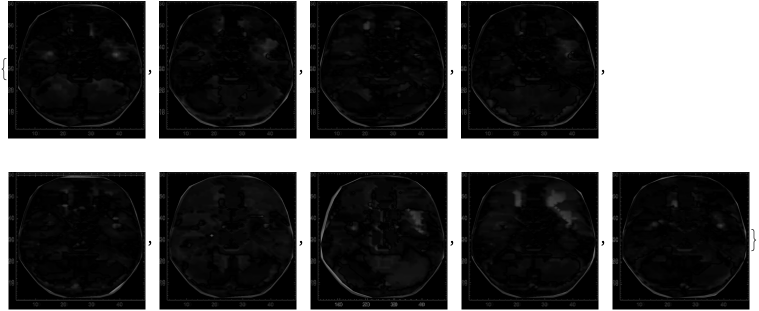
We can then plot the image difference between the mean and each participant:
In[]:=
averageDifferencefMRI=Table[ImageDifference[ImageResize[grayImagesOfScans[[x]],{550,550}],ImageResize[grayMeanScan,{550,550}]],{x,1,9}]
Out[]=
Next, we take the average of these mean-difference plots across all participants, plotted as 1000 by 1000 pixel image (with its color reverse adjacent):
In[]:=
finalIntrafMRI=Image[Mean[Rasterize/@Map[ImageResize[#,{256,256}]&,averageDifferencefMRI]]];{ImageResize[finalIntrafMRI,{1000,1000}],ImageResize[ColorNegate[finalIntrafMRI],{1000,1000}]}
Out[]=
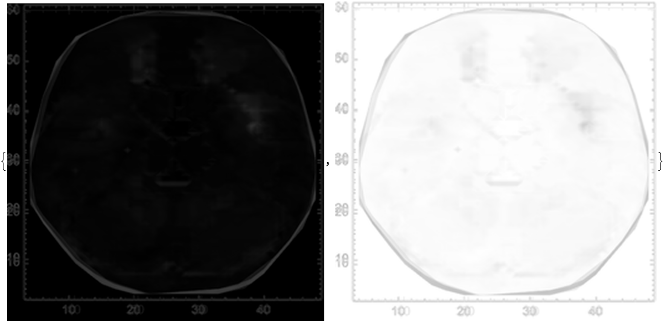
With the color-reversed image of the averaged mean-difference plot, we can perform image clustering to estimate areas of variance between the scans:
In[]:=
ImageResizeColorizeClusteringComponents
,3,{1000,1000}

Out[]=
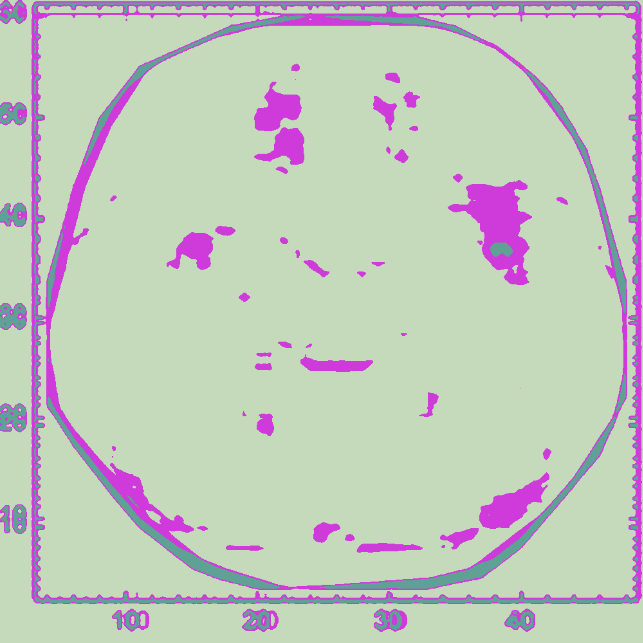
The center of principal variance within the average mean-difference plot is located at approximately (38, 37) on the plot, corresponding with the location of the right putamen within the brain.
Conclusions
Conclusions
Overall, the average mean-difference plots across the set of 360 words for the LLM and fMRI voxels indicates that the right putamen is associated with language processing. Furthermore, although several studies have identified the connections between the left putamen and language processing in production and semantic analysis, this is the first paper to propose that the right putamen is correlated with the lower-order initial phases of language processing (Abutalebi et al., 2013; Robles, 2005; Viñas-guasch & Wu, 2017). Building upon this finding by juxtaposing respective averaged plots, we determined that the activation variance found within the right putamen of the fMRI sections directly mirrors the activity variance of the GPT2 LLM framework.
Future Directions
Future Directions
While we found clear correlates between the right putamen activation and LLM activity variance, an exploration of different types of prompts for the LLM and fMRI participants is critical. For example, we could take sets of similar words (synonyms), opposing words (antonyms), and unrelated words and plot the sets as vectors in model and signaling space to visualize inter-spatial adjacency. Also, the difference of model activity and fMRI activations between numerical and word prompts should also be explored. Beyond singular tokens, analyses can be expanded to sentence comprehension, investigating the effects caused by variations in complexity of structure, fragmentation, and types of elements.
Acknowledgements
Acknowledgements
I would like to thank my mentor, Daniele Ceravolo, for helping me navigate the Wolfram language, streamline the aims of my project, and condense my final work. I would also like to thank Nicolò Monti for proposing the idea of manipulating the embedding layers of the LLM and his willingness to discuss future work on vector with me.
References
References
Abutalebi, J., Rosa, P. A. D., Castro gonzaga, A. K., Keim, R., Costa, A., & Perani, D. (2013). The role of the left putamen in multilingual language production. Brain and Language, 125(3), 307-315. https://doi.org/10.1016/j.bandl.2012.03.009
Antholzer, S., Haltmeier, M., & Schwab, J. (2018). Deep learning for photoacoustic tomography from sparse data. Inverse Problems in Science and Engineering, 27(7), 987-1005. https://doi.org/10.1080/17415977.2018.1518444
Cox, D., & Dean, T. (2014). Neural networks and neuroscience-inspired computer vision. Current Biology, 24(18), R921-R929. https://doi.org/10.1016/j.cub.2014.08.026
Cuccio, V., Perconti, P., Steen, G., Shtyrov, Y., & Huang, Y. (2022). Editorial: Experimental approaches to pragmatics. Frontiers in Psychology, 13. https://doi.org/10.3389/fpsyg.2022.865737
Furman, J., & Seamans, R. (2019). AI and the economy. Innovation Policy and the Economy, 19, 161-191. https://doi.org/10.1086/699936
Furman, J., & Seamans, R. (2019). AI and the economy. Innovation Policy and the Economy, 19, 161-191. https://doi.org/10.1086/699936
Greer, D. S. (2007). An image association model of the brodmann areas. 6th IEEE International Conference on Cognitive Informatics, 538-547. https://doi.org/10.1109/coginf.2007.4341934
Han, S.-H., Kim, K. W., Kim, S., & Youn, Y. C. (2018). Artificial neural network: Understanding the basic concepts without mathematics. Dementia and Neurocognitive Disorders, 17(3), 83. https://doi.org/10.12779/dnd.2018.17.3.83
Han, S.-H., Kim, K. W., Kim, S., & Youn, Y. C. (2018). Artificial neural network: Understanding the basic concepts without mathematics. Dementia and Neurocognitive Disorders, 17(3), 83. https://doi.org/10.12779/dnd.2018.17.3.83
Hurley, C. B., O’connell, M., & Domijan, K. (2021). Interactive slice visualization for exploring machine learning models. Journal of Computational and Graphical Statistics, 31(1), 1-13. https://doi.org/10.1080/10618600.2021.1983439
Ivakhnenko, A. G., & Lapa, V. G. (1965). Cybernetic predicting devices. CCM Information Corporation. https://www.worldcat.org/title/cybernetic-predicting-devices/oclc/23815433
Lee, K., Ippolito, D., Nystrom, A., Zhang, C., Eck, D., Callison-burch, C., & Carlini, N. (2021). Deduplicating training data makes language models better. arXiv. https://doi.org/10.48550/ARXIV.2107.06499
Mitchell, T. M., Shinkareva, S. V., Carlson, A., Chang, K.-M., Malave, V. L., Mason, R. A., & Just, M. A. (2008). Predicting human brain activity associated with the meanings of nouns. Science, 320(5880), 1191-1195. https://doi.org/10.1126/science.1152876
Nasios, G., Dardiotis, E., & Messinis, L. (2019). From broca and wernicke to the neuromodulation era: Insights of brain language networks for neurorehabilitation. Behavioural Neurology, 2019, 1-10. https://doi.org/10.1155/2019/9894571
Pereira, F., Detre, G., & Botvinick, M. (2011). Generating text from functional brain images. Frontiers in Human Neuroscience, 5. https://doi.org/10.3389/fnhum.2011.00072
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
Robles, S. G. (2005). The role of dominant striatum in language: A study using intraoperative electrical stimulations. Journal of Neurology, Neurosurgery & Psychiatry, 76(7), 940-946. https://doi.org/10.1136/jnnp.2004.045948
Sejnowski, T. J. (2023). Large language models and the reverse turing test. Neural Computation, 35(3), 309-342. https://doi.org/10.1162/neco_a_01563
Soni, B. K., & Waoo, A. A. (2023). Convolutional neural network model for identifying neurological visual disorder. Artificial Intelligence for Neurological Disorders, 61-75. https://doi.org/10.1016/b978-0-323-90277-9.00003-1
Viñas-guasch, N., & Wu, Y. J. (2017). The role of the putamen in language: A meta-analytic connectivity modeling study. Brain Structure and Function, 222(9), 3991-4004. https://doi.org/10.1007/s00429-017-1450-y
Watson, D. S., Krutzinna, J., Bruce, I. N., Griffiths, C. E., Mcinnes, I. B., Barnes, M. R., & Floridi, L. (2019). Clinical applications of machine learning algorithms: Beyond the black box. BMJ. https://doi.org/10.1136/bmj.l886
Zhao, L., Zhang, L., Wu, Z., Chen, Y., Dai, H., Yu, X., Liu, Z., Zhang, T., Hu, X., Jiang, X., Li, X., Zhu, D., Shen, D., & Liu, T. (2023). When brain-inspired AI meets AGI. Meta-Radiology, 100005. https://doi.org/10.1016/j.metrad.2023.100005
CITE THIS NOTEBOOK
CITE THIS NOTEBOOK
Deconstructing GPT2 to relate LLM activity to fMRI activation voxels
by Avi Verma
Wolfram Community, STAFF PICKS, July 13, 2023
https://community.wolfram.com/groups/-/m/t/2963788
by Avi Verma
Wolfram Community, STAFF PICKS, July 13, 2023
https://community.wolfram.com/groups/-/m/t/2963788