In the English language adjectives can be assigned to specific categories that represent the individual words as a whole. These categories are: opinion, size, age, shape, colour, origin, material and purpose. This is also the order that adjectives go in. In my project I am looking at how to classify words from texts into these categories and how adjectives stand in relation to each other in sequences.
Introduction
Introduction
In my project I am sorting adjectives from texts into certain categories and trying to figure out to what extent adjectives correlate in sequences of adjectives. Being able to classify adjectives to their correspondent categories simplifies work, if you only want to work with a certain set of adjectives and will also make it possible to put adjectives in the right order, according to their classifications.
Data Scraping
Data Scraping
First, I am importing data, from which I can extract adjectives from. For my data I am using books that are from https://www.gutenberg.org/, details in references.
ResourceData["A Little Princess"];
In[]:=
ResourceData["A Portrait of the Artist as a Young Man"];
In[]:=
ResourceData["A Princess of Mars"];
In[]:=
ResourceData["Hamlet"];
In[]:=
books=ResourceData["A Little Princess"]<>ResourceData["A Portrait of the Artist as a Young Man"]<>ResourceData["A Princess of Mars"]<>ResourceData["Hamlet"];
Creating the categories for the adjectives
Creating the categories for the adjectives
In this section I am creating the categories that I can assign the adjectives from my texts to.
Here, I am filtering all the adjectives from WordData out of my list:
In[]:=
adjectives=WordData[All,"Adjective"];
This function returns me all antonyms and synonyms of a word and is intersecting them with the list of adjectives from above, so that I only have adjectives in my final list:
In[]:=
antsynadj[word_]:=Intersection[adjectives,Union[Flatten[WordData[word,#,"List"]&/@{"Antonyms","Synonyms"}]]]
In order for me to have a collection of adjectives that belong to the same classification, I am grouping an adjective with its synonyms and antonyms and then doing this step all over again, so taking the synonyms and antonyms of each the synonym and antonym of a word, until we have a range of adjectives that belong to the same category:
Here is an example of doing this with the word "difficult":
In[]:=
Nest[Union[Flatten[antsynadj/@#]]&,{"difficult"},2]
Out[]=
{"arduous", "backbreaking", "comfortable", "concentrated", "difficult", "easygoing", "gentle", "grueling", "gruelling", "heavy", "intemperate", "knockout", "laborious", "leisurely", "light", "loose", "manageable", "operose", "promiscuous", "prosperous", "punishing", "severe", "slow", "sluttish", "soft", "strong", "surd", "toilsome", "tough", "uncontrollable", "uncorrectable", "uneasy", "unvoiced", "unwieldy", "voiceless", "wanton", "well-fixed", "well-heeled", "well-off", "well-situated", "well-to-do"}
Using this, I am able to specifically make the classifications: opinion, size, age, shape, colour, origin, material and purpose
I am using a certain set of words (known examples from each of these categories) that the synonyms and antonyms can follow, in order to obtain a list of words that are similar among themselves.
I am using a certain set of words (known examples from each of these categories) that the synonyms and antonyms can follow, in order to obtain a list of words that are similar among themselves.
In[]:=
opinion=Flatten[{Nest[Union[Flatten[antsynadj/@#]]&,{"difficult","beautiful","ugly","delicious","important","funny"},2],"difficult","beautiful","ugly","delicious","important","funny"}];
In[]:=
size=Flatten[{Nest[Union[Flatten[antsynadj/@#]]&,{"big","huge","tall","small","short"},2],"big","huge","tall","small","short"}];
In[]:=
age=Flatten[{Nest[Union[Flatten[antsynadj/@#]]&,{"old","ancient","new","young"},2],"old","ancient","new","young"}];
In[]:=
shape=Flatten[{Nest[Union[Flatten[antsynadj/@#]]&,{"round","square","triangular","rectangular","flat"},2],"round","square","triangular","rectangular","flat"}];
In[]:=
colour=Flatten[{Nest[Union[Flatten[antsynadj/@#]]&,{"red","green","yellow","orange","blue","pink","purple","black","white","brown"},2],"red","green","yellow","orange","blue","pink","purple","black","white","brown"}];
In[]:=
origin=Flatten[{Nest[Union[Flatten[antsynadj/@#]]&,{"English","Irish","African-American","Italian","French","Mexican"},3],"English","Irish","African-American","Italian","French","Mexican"}];
In[]:=
material=Flatten[{Nest[Union[Flatten[antsynadj/@#]]&,{"gold","silver","copper","cotton","leather","polyester","wool","silk","velvet","wooden","stone","diamond","plastic"},2],"gold","silver","copper","cotton","leather","polyester","wool","silk","velvet","wooden","stone","diamond","plastic"}];
In[]:=
purpose=Flatten[{Nest[Union[Flatten[antsynadj/@#]]&,{"running","sleeping","frying","flower","tennis"},2],"running","sleeping","frying","flower","tennis"}];
Assigning of adjectives from data to categories
Assigning of adjectives from data to categories
Subsequently, I am creating a function that lets you enter an adjective that you have extracted from your text and will return all the adjective categories and will show you whether that word is included in them.
In[]:=
categorycheck[category_List,word_]:=Which[ContainsAny[category,{word}],True,ContainsAny[category,Synonyms[word]],True,ContainsAny[category,Antonyms[word]],True,True,False]
In[]:=
check[word_]:=First@#->categorycheck[Values@#,word]&/@{"Opinion"->opinion,"Colour"->colour,"Shape"->shape,"Size"->size,"Age"->age,"Origin"->origin,"Material"->material,"Purpose"->purpose}
In[]:=
check["red"]
Out[]=
{"Opinion" -> False, "Colour" -> True, "Shape" -> False, "Size" -> False, "Age" -> False, "Origin" -> False, "Material" -> False, "Purpose" -> False}
Relationships between adjectives
Relationships between adjectives
In[]:=
books=ResourceData["A Little Princess"]<>ResourceData["A Portrait of the Artist as a Young Man"]<>ResourceData["A Princess of Mars"]<>ResourceData["Hamlet"];
Here, I am breaking the books down into sentences:
In[]:=
sentences=TextCases[books,"Sentence"];
adjnouns does 2 operations: Firstly, it filters the adjectives and nouns out from the sentences and sorts them by position (in the order that they are found in the sentences), secondly it breaks the sentences into words.
In[]:=
adjnouns= First/@SortBy[ Flatten[Values@ TextCases[#,{"Adjective","Noun"}->{"String", "Position"}],1],Last]->StringSplit[#,{" ",","}]&/@ sentences;
In[]:=
sequences=Union[LongestCommonSubsequence[First@#,Last@#]&/@adjnouns];
Then, we are extracting the sequences that are being followed by a noun:
In[]:=
adjsequences= Most/@Select[sequences, Length@#>2&&Length@TextCases[Last@#,"Noun"]>0&];
Thereafter, we need to filter the adjectives out:
In[]:=
adjectives= Select[adjsequences,Length@#==Length@Flatten[TextCases[#,"Adjective"],1]&];
By using a directed graph we can also visualise how the adjectives and the different sequences of adjectives stand in relation to each other:
HighlightGraph[g,ConnectedComponents[g]]
Out[]=
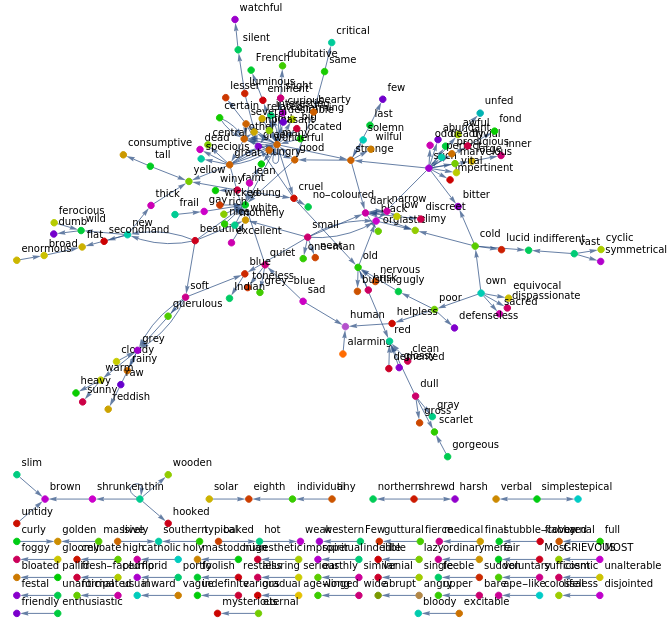
g=DirectedGraph[Flatten[Thread[Most@#->Rest@#]&/@adjectives], VertexLabels->Automatic]
Out[]=
Conclusion and Future work
Conclusion and Future work
Now that categories have been created, one can experiment with them and use these classifications further for also putting the adjectives into the right order. Determining that all the adjectives that belong to the category x stand in position y for instance. One can also continue working with the directed graph, thus it can also be read from the graph, in which order adjectives were put in texts. In the way that I have created the categories opinion, size, age, shape, colour, origin, material and purpose, while it is possible that some adjectives will not fit ideally into a category, classifications still allow us to filter and identify adjectives and sequences of adjectives as a whole more accurately.
References
References
Project gutenberg. Project Gutenberg. (n.d.). Retrieved July 21, 2022, from https://www.gutenberg.org/