This dataset was created for the project under wolfram summer school. We present a comprehensive dataset that benchmarks over 450 large language models (LLMs) across 676 math and logic questions. The dataset captures binary correctness (True/False) for each question, along with token-level cost and release date metadata, making it a powerful resource for evaluating model performance, cost-effectiveness, and reasoning consistency.
Built using the Wolfram Language, the project merges manually curated cost and release information with results from the LLMBenchmarks repository. It supports in-depth visualizations (e.g., accuracy vs cost, PCA clustering) and can be extended for research on question difficulty, vocabulary influence, and cost-performance trade-offs. This post details the methodology, dataset structure, and tools for exploration.
Built using the Wolfram Language, the project merges manually curated cost and release information with results from the LLMBenchmarks repository. It supports in-depth visualizations (e.g., accuracy vs cost, PCA clustering) and can be extended for research on question difficulty, vocabulary influence, and cost-performance trade-offs. This post details the methodology, dataset structure, and tools for exploration.
Overview
Overview
Dataset of 461 LLMs evaluated on 671 math and logic questions, with each model's token usage cost and release date
Details
Details
◼
Each model was given the same set of questions covering topics from basic arithmetic and algebra to general knowledge and reasoning. The models' answers were evaluated as true (correct) or false (incorrect) for each question. he dataset also includes the input cost and inputCost (in USD per 1,000 tokens) for each model, which reflect the pricing of using that model's API, as well as the release date of the model or model version.
◼
The questions range from simple computations (e.g., "Compute 1+2+3.") to more complex problems across mathematics, science, and general knowledge. For arithmetic questions, correctness was determined by comparing the model's answer to the known numerical result. For factual questions, the answers were checked against known facts or expected answers. The correctness data is binary, meaning partial credit is not awarded; an answer is marked true only if it fully meets the expected answer criteria.
◼
Data Definitions
Data Definitions
Tools for Importing and formatting benchmark dataset
Tools for Importing and formatting benchmark dataset
(*Setbasedirectorywherethebenchmarkfilesarestored*)baseDir="FilePath";(*Example:baseDir="C:/Users/Rakesh/OneDrive/Desktop/WSS25/filesForRakesh";*)(*Loadlistofmodels*)modelList=Import@FileNameJoin[{baseDir,"llmbenchmarks-main@034cb527908","Resources","ModelLists","full_model_list.wl"}];(*Helperfunctionstofetchresultsforagivenmodel*)getModelResultsEiwl[model_]:=Module[{path=model["Eiwl"]},If[StringQ[path],Import@FileNameJoin[{baseDir,"TrainingResults",path}],Missing["InvalidPath"]]];getModelResultsEiwlWithVoc[model_]:=Module[{path=model["EiwlWithVoc"]},If[StringQ[path],Import@FileNameJoin[{baseDir,"TrainingResults",path}],Missing["InvalidPath"]]];(*Convertrawresultstoacleanassociationofquestioncorrectness*)resultQuestionsCorrect[results_]:=<||>;resultQuestionsCorrect[results_?(FreeQ[Missing])]:=AssociationThread[results["Data",All,"Input"],TrueQ/@results["Data",All,"ModelOutputs",1,"CodeEquivalentQ"]];(*Builddatasets:modelname→correctnessassociations*)allModelQuestionswithoutVoc=AssociationThread[modelList[[All,"ModelStandardName"]],KeyUnion@resultQuestionsCorrect/@getModelResultsEiwl/@modelList];allModelQuestionswithtVoc=AssociationThread[modelList[[All,"ModelStandardName"]],KeyUnion@resultQuestionsCorrect/@getModelResultsEiwlWithVoc/@modelList];
In[]:=
(*Load additional pre-hosted datasets from Wolfram Cloud*)ResourceData,"allModelQuestionscloudFile" = CloudObject["https://www.wolframcloud.com/obj/23802159-676f-4d2a-8329-5a8a43a9a5f3"];allModelQuestions = ResourceData,"allModelQuestionscloudFile"ResourceData,"allModelQuestionswithtVoccloudFile" = CloudObject["https://www.wolframcloud.com/obj/6f87531d-b116-4185-8d69-ea7af5b0d3ef"];allModelQuestions = ResourceData,"allModelQuestionswithtVoccloudFile"
In[]:=
(*Load manual collected data that's been uploaded to Wolfram Cloud*)ResourceData,"modelCostcloudFile" = CloudObject["https://www.wolframcloud.com/obj/d1453ef5-209b-4455-86bd-0d34fccb7cdd"];modelCost = ResourceData,"modelCostcloudFile"ResourceData,"modelDatescloudFile" = CloudObject["https://www.wolframcloud.com/obj/b5805747-1fc7-400c-b8b4-549fb8bc69ee"];modelDates = ResourceData,"modelDatescloudFile"
Primary Content
Primary Content
ModelName | IdentifieroftheLLM(e.g.,GPT-4,Claude-3.5) |
OutputCost$(per1Ktokens) | APIoutputcost(manuallycompiled) |
InputCost$(per1Ktokens) | APIinputcost(manuallycompiled) |
ReleaseDate | Dateofpublicavailability |
Q1–Q676 | Boolean(True/False)correctnessforeachquestion |
VocabularyCoverage(onlyinwithtVoc)WithoutVocabularyCoverage(onlyinwithouttVoc) | True/False–whethermodeloutputcoversvocabularyofthequestionTrue/False–whethermodeloutputcoverswithoutvocabularyofthequestion |
Additional Data Elements (optional)
Additional Data Elements (optional)
◼
allModelQuestionswithtVoc: Dataset with vocabulary overlap metric
◼
allModelQuestionswithoutVoc: Dataset without vocabulary info
◼
modelCost: Cost metadata (manually collected)
◼
modelDates: Release date metadata (manually collected)
Examples
Examples
Basic Examples
Basic Examples
In[]:=
Dataset[Take[allModelQuestions,3,3]]
Out[]=

(*Dataset[Take[allModelQuestionswithtVoc,3,3]]*)
In[]:=
modelCost//Take[#,5]&//Dataset
Out[]=

In[]:=
modelDates//Take[#,5]&//Dataset
Out[]=
Scope & Additional Elements
Scope & Additional Elements
Clusters often correspond to similar model families or training objectives:
In[]:=
ListPlot@AssociationThread[Keys[allModelQuestions],DimensionReduce[Values@Replace[Values/@allModelQuestions,{True->1,False->0},{2}],2]]
Out[]=
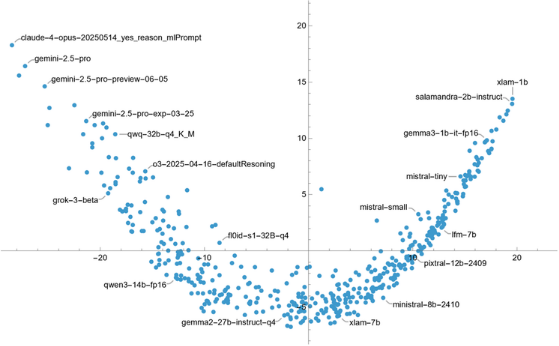
Analysis
Analysis
To provide quantitative view, we apply the Bradley-Terry model, a statistical method for estimating the relative "performance" of entities based on pairwise comparisons.
To provide quantitative view, we apply the Bradley-Terry model, a statistical method for estimating the relative "performance" of entities based on pairwise comparisons.
In[]:=
BradleyTerryModel[allModelQuestions_]:= ;{modelScores, questionScores, allModelQuestionsPossible, models,questions} = BradleyTerryModel[allModelQuestions];
Visualizing Cost vs Performance of LLMs:
In[]:=
scoreData=Dataset[KeyValueMap[<|"Model Name"->#1,"Score"->#2|>&,modelScores]];costData=Normal[modelCost];cleanCostData=Dataset[AssociationThread[{"Model Name","Output Cost","Input Cost"}->#]&/@costData];mergedData=JoinAcross[scoreData,cleanCostData,"Model Name"];mergedData1=mergedData[All,Append[#,"Total Cost"->(#["Input Cost"]+#["Output Cost"])]&];maxRatio=Max[mergedData1[Select[#["Total Cost"]>0&],#["Score"]/(#["Input Cost"]+#["Output Cost"])&]];mergedData2=mergedData1[All,Append[#,"Performance per $1"->If[#["Total Cost"]>0,#["Score"]/#["Total Cost"],1.5maxRatio]]&];Module[{data,tooltippedPoints},data=Normal@mergedData2;tooltippedPoints=Map[Callout[{#["Total Cost"],#["Score"]},#["Model Name"]]&,data];ListLogLogPlot[tooltippedPoints,FrameLabel->{"Total Cost ($)","Score"},PlotLabel->Style["Score vs Total Cost for LLMs",Bold,12],ImageSize->Large,Frame->True]]
Visualizing release dates vs Performance of LLMs:
In[]:=
datesData=Normal[modelDates];cleanDatestData=Dataset[AssociationThread[{"Model Name","Release Date"}->#]&/@datesData];mergedDatesData=JoinAcross[scoreData,cleanDatestData,"Model Name"];Module[{dates,scores,models,tooltippedPoints},dates=Normal[mergedDatesData[[All,3]]];scores=Normal[mergedDatesData[[All,2]]];models=Normal[mergedDatesData[[All,1]]];tooltippedPoints=MapThread[Callout[Style[{#1,#2},Small],#3]&,{dates,scores,models}];DateListPlot[tooltippedPoints,AxesLabel->{"Release Date","Score"},PlotLabel->Style["Score vs Release Date of LLMs",Bold,12],ScalingFunctions->{"Linear","Log"},Joined->False,ImageSize->Large,Frame->True]]
Source & Additional Information
Source & Additional Information
Submitted By
Submitted By
Rakesh Vijay Kumar (Mentor(s): Christopher Wolfram, Piero Sanchez)
Source/Reference Citation
Source/Reference Citation
Benchmark data: Derived from the LLMBenchmarks Dataset - https://www.wolfram.com/llm-benchmarking-project/
Cost & Release Dates: Manually curated by the contributor from official model cards, blogs, and API docs
Detailed Source Information
Detailed Source Information
Links
Links
Keywords
Keywords
◼
LLM
◼
Model Evaluation
◼
Token Cost
◼
Vocabulary Coverage
◼
Benchmark
◼
LLM
Categories
Categories
Content Types
Content Types
Related Resource Objects
Related Resource Objects
Related Symbols
Related Symbols
Author Notes
Author Notes
Cost and release data are manually verified valuable for future LLM cost-benefit analysis
Questions cover multiple levels of complexity allows future research on reasoning vs memorization
Dataset could be extended with newer models or detailed explanation traces in future versions
Submission Notes
Submission Notes
CITE THIS NOTEBOOK
CITE THIS NOTEBOOK
Dataset: LLMBenchmarks detailed data + cost & release date
by Rakesh Vijay Kumar
Wolfram Community, STAFF PICKS, July 10, 2025
https://community.wolfram.com/groups/-/m/t/3497569
by Rakesh Vijay Kumar
Wolfram Community, STAFF PICKS, July 10, 2025
https://community.wolfram.com/groups/-/m/t/3497569