String Substitution Systems
String Substitution Systems
Stephen Wolfram
(Unfinished draft as of March 28, 2006; with small updates October 2019)
(Unfinished draft as of March 28, 2006; with small updates October 2019)
Introduction
Introduction
Substitution Systems
Substitution Systems
A great many systems can be thought of as consisting at some level of strings of elements that are successively updated by making substitutions for particular blocks of these elements. The purpose of this [paper] is to carry out a systematic study of a large number of simple such string substitution systems, in the tradition of A New Kind of Science.
Substitution systems consist of strings of elements that are successively updated by performing substitutions for blocks of these elements. Specific classes of examples of such systems have been considered under a variety of different names for over a century. Our purpose here is for the first time to carry out a fully systematic study of substitution systems with the property of causal invariance, in the tradition of A New Kind of Science.
String substitution systems seem to capture important underlying mechanisms in many diverse areas, including computer science, foundations of mathematics, molecular biology, chemistry, linguistics and physics. The results in this [paper] should be relevant to almost any potential application of string substitution systems.
The picture below shows an example of a string substitution system.
SREvolutionGraphics[SRXEvolveList[{"AB""ABBA"},"AB",4]]
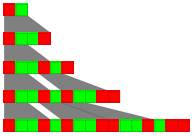
[ This particular system is defined by the rules . ]
{"A""CAB","BBC""CB"}
Grid[{{Labeled[SREvolutionGraphics[SRXEvolveList[#,"AA",7]],SRRuleGraphic[#]]&[{"A""CAB","BBC""CB"}],SRGraphicsChopped[SREvolveList[{"A""CAB","BBC""CB"},"AA",100],100]}}]
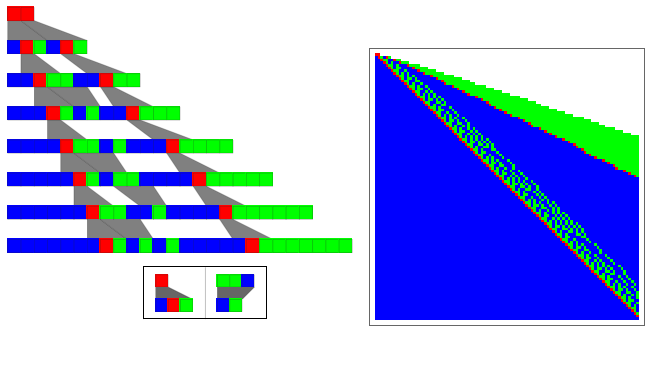
A key issue in string substitution systems is the order in which rules are applied. In general, different orders may lead to different results, as in the picture below. [[[In this picture only one update is done at each step]]]
Grid[{{Labeled[SREvolutionGraphics[RandomSRXEvolveList[#,"AA",7],ImageSize130],SRRuleGraphic[#]]&[{"A""CAB","BBC""CB"}],SRGraphicsChopped[RandomSREvolveList[{"A""CAB","BBC""CB"},"AA",100],100]}}]
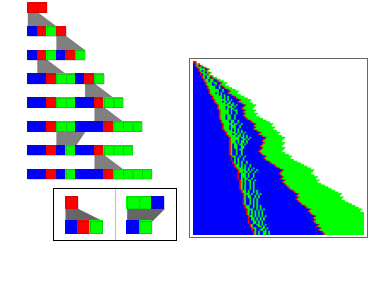
One can represent all the different possible orders using a multiway system.
Causal Invariance
Causal Invariance
In a system like a cellular automaton, there is a definite notion of time: at every step, each cell gets updated in parallel according to a fixed rule. In a substitution system, however, the situation can be more complicated.
As an example, consider the very simple rule . At each step there is an ambiguity in how to apply the rule.
"AA""AAA"
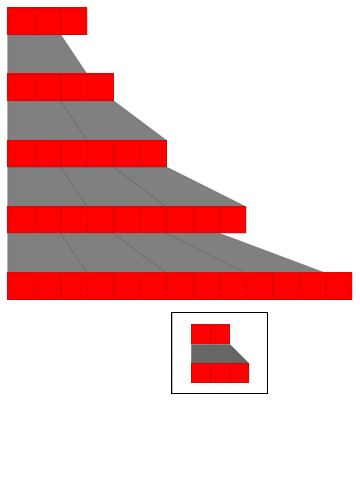
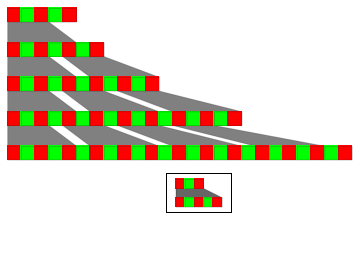
The remarkable fact, however, is that there exist what we will call causal invariant substitution systems where no such ambiguity is possible. The condition for this turns out simply to be that the strings which appear on the left-hand side of each rewrite allow no overlaps, either with themselves or with each other.
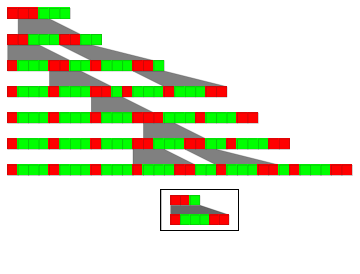
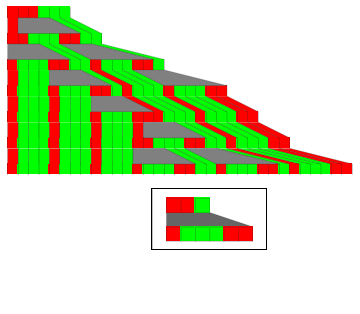
[[XXXX use a case with 2 rewrites]]]
When the rules for a substitution system have the property of causal invariance, it means that there is, in a sense, a unique standard evolution for the system—in which the maximum number of rewrites get done at each step.
One can always choose to consider other evolutions, in which fewer rewrites get done at each step. But the point is that in all cases the system in a sense maintains the same causal structure—so that a given rewrite must be preceded by the same sequence of other rewrites.
The pictures below indicate how a causal network can be constructed that shows the causal relationships between rewriting events. The causal network can conveniently be shown like a "light cone", in which events reached by successively more steps from a given event are shown on successive lines down the page.
Given a causal network, possible evolutions for the system can be obtained by taking different families of slices, or foliations, through the causal network. The standard evolution involving a maximum number of rewrites at each step corresponds to XXXXXXXXXXXXXXXXXXX.
Labeled[SREvolutionGraphicsStreamed[SRXEvolveList[#,"AAABBB",6]],SRRuleGraphic[#]]&[{"AAB""ABBBAA"}]
[[[ Dead elements are ones that will never be updated again... (Here some elements are shown without successors, but in fact would eventually get successors.) ]]]
Overlap-Free Strings
Overlap-Free Strings
With two possible elements, the first few distinct overlap-free strings are (ignoring reversal and renaming):
With three possible elements, the first few overlap-free strings are:
If one considers pairs of strings, it becomes slightly more difficult to find overlap-free cases. Nevertheless, with two possible elements, the first few examples are:
With three elements, the first few examples of overlap-free pairs are:
With triples of strings, the first few cases are:
[[Tables of overlap-free strings; counts of them]] [[[ Todd will generate these ]]]
(((((((( Number of overlap free strings vs k, n, p; what fraction of possible strings are overlap free ))))))))
Note: Single Overlap-Free Strings
Note: Single Overlap-Free Strings
It is straightforward to derive the recurrence
Consider an overlap-free string s of length n-1 with first element e. Adding any element other than e to the end of s will give an overlap-free string of length n. In addition, adding e to the beginning will also give an overlap-free string. There is, however, one case where strings produced by this procedure will not be unique: the case where the resulting string is a "doubled" version of a length-n/2 overlap-free string. Thus, for example, AABB can be produced both by adding B to the end of AAB, and by adding A to the beginning of ABB.
An alternative form of the recurrence is:
There does not appear to be a solution for a[n] in terms of ordinary special functions.
One can enumerate strings in the order corresponding to digit sequences of successive numbers. The following show the cumulative number of overlap-free strings as a function of string enumeration number for strings of lengths 6 and 10:
The following shows the lengths of overlaps for all strings of length 8. The overlap-free strings are those with overlap length 0.
Overlap-free pairs
Overlap-free pairs
The following show which pairs of strings are overlap-free.
The following show the relative overlap lengths for pairs of strings:
Neighbor-Independent Rules
Neighbor-Independent Rules
The simplest substitution systems have "neighbor-independent" rules, in which the replacement for a particular symbol depends
work by replacing
work by replacing
Growth rates and the relation to matrices
Growth rates and the relation to matrices
It is fairly straightforward to analyse many features of neighbor-independent substitution systems.
For example, the total numbers of each element always satisfy a system of linear recurrence relations. Indeed, each step just corresponds to multiplying the vector of numbers of each element by a fixed matrix.
For the Fibonacci substitution system, the evolution matrix is {{1,1},{1,0}}. This means that the total numbers of As and Bs at step t is given by:
In general, the total lengths of strings at step t must satisfy at most a k-th order linear recurrence relation:
The coefficients c[i] in this recurrence relation can be obtained directly from the characteristic polynomial of the evolution matrix m according to:
In the Fibonacci substitution system case, the coefficient list is just {1, 1}. Such a coefficient list can be thought of as a kernel for the linear recurrence. Given a kernel ker, and a sequence of initial values list, the first t successive terms can be computed from:
Growth rates for all possible matrices
Growth rates for all possible matrices
In general, any matrix of non-negative integers serves as the evolution matrix for some substitution system. With k possible elements, and at most s appearing on the right-hand side of any given rewrite, the complete set of possible evolution matrices is given by:
The distribution of possible leading eigenvalues is as follows: [[[make lines in pictures go vertically]]]
For large k and s, the distribution of leading eigenvalues tends to a XXXXXXXX [Gaussian]. In all cases the leading eigenvalues are algebraic numbers of degree at most k. The largest leadingeigenvalue that can occur is k s—and this occurs only for the single matrix whose entries are all s. The smallest leading eigenvalues that occur are 0 and 1. (Since the matrices contain only integers, there can be no eigenvalues at all between 0 and 1, or -1 and 0.)
A largest eigenvalue of 0 occurs only in the fairly trivial case where the substitution system leads to a zero-length string.
When the largest eigenvalue is 1, it corresponds to a substitution system where the string length grows not exponentially with t, but instead as a polynomial in t. The maximum degree of the polynomial is k-1.
The following gives the multiplicities of different polynomial degrees in several cases: [[include more k and s values, and also the ∞ case: i.e. how many cases there are that are above polynomial]]
[[Each one of these corresponds to a certain kernel for a linear recurrence relation]]
The kernel in this case is {1,-3,3}.
Rules involving a single one-element rewrite
Rules involving a single one-element rewrite
The following tables summarize the distinct classes of rules that exist with two types of elements, but a single rewrite with progressively longer right-hand side:
The rules are classified here by the sequence of string lengths that they generate. For this case of a single rewrite, each class is defined by the number of "active" elements A and inactive elements B that appear on the right-hand side. Different orderings of A and B lead to patterns that are different in detail, but are related by simple transformations.
Adding more elements C, D, etc. has no effect on the classes of rules that can occur in this case. In effect, C, D, etc. act just like B, as "inactive elements".
Rules involving two one-element rewrites
Rules involving two one-element rewrites
With rewrites for both A and B elements, the following table summarizes the classes of rules that occur with right-hand sides of lengths up to 2:
Note the appearance here of the Fibonacci substitution system. Note also the 19 different AAA substitution systems, in which the replacements for B are never used, and so are irrelevant.
[[[[ To what extent are the rules in given class equivalent ?? ]]]]
If one consider right-hand sides up to length 3, many new growth rates can occur. 11 different exponential growth rates. The kernel must still be of length 2 ....
With right-hand sides of length up to 3, [[[[ what growth rates occur ]]]]]
With right-hand sides of length up to 3, [[[[ what growth rates occur ]]]]]
The set of 2-element kernels that occur allowing right-hand sides of progressively greater lengths is:
[[[ What is the analogy between these and the matrices ?? How much does it matter to start with A, rather than all possible strings ? ]]]
With three elements, A, B and C, kernels up to length 3 appear, and many other growth rates occur.
[[http://www.wolframscience.com/nksonline/page-890a-text]]
Detailed patterns of strings
Detailed patterns of strings
In addition to looking at the growth of lengths of strings, one can look at the detailed patterns of each string. (An intermediate case is to look at the numbers of each color. For neighbor-independent substitution systems, these always obey a 1-step "multirecurrence".)
((The following was very slow))
Some rules give strings that are purely repetitive. Others give nested strings...... (What is required for the strings to be nested? Can the polynomial growers be nested?)
XXXX PEncode ....
Consider {"A","B",p[1,1],p[3,5],p[8,13],p[21,34],p[34,34]} creating network....
What about the vertical columns???
Dependence on Initial Conditions
Dependence on Initial Conditions
For neighbor-independent substitution systems, results for initial conditions containing several elements are always just pure concatenations of results for each element on its own. This means that the growth rates are always characterized by polynomials which are products of the polynomials obtained with initial conditions consisting of each element on its own.
Causal Networks
Causal Networks
Layered causal network plots:
Fibonacci rule:
Quadratic growth rule:
Single-Rewrite Neighbor-Dependent Substitution Systems
Single-Rewrite Neighbor-Dependent Substitution Systems
The Case ABX
The Case ABX
The picture below shows an example of such a substitution system:
Here are a sequence of such systems, starting from the simplest possible initial condition:
Causal networks:
de Bruijn sequence initial conditions:
This is a summary of behaviors for rules of the form ABX, where X is a string of length 1 through 7:
Note that with AB as an initial condition, the transients remain short. But with longer initial conditions, there can be long transients, as in the case of ABBAA shown below.
Possible Growth Rates
Possible Growth Rates
With length 4 RHSs, seem to only get 1, 2, GoldenRatio growth rates. With longer RHSes, additional growth rates occur.
The maximum rates of growth for right-hand sides of successively greater length are:
In general, if the length of the right-hand side is n, the maximum growth rate is Quotient[n,2]. For even n, this is achieved by rules of the form ABABABAB... or ABBABABA...
It is possible to prove that any rule of the form ABX must lead to strings whose total size on successive steps satisfies a linear recurrence. The number of terms in the linear recurrence is bounded by the square of the length of the right-hand side of the rule, and the square of the length of the initial condition.
The maximum numbers of terms for all rules with right-hand sides of sizes 1 through 10 is:
[[[ This suggests a linear growth rate ]]]
ABBA
ABBA
This rule simply sorts all Bs in front of As. The function can be thought as "counting in unary".
Random initial condition:
Initial condition with As followed by Bs:
Causal network:
(In the cyclic case, this does more)
Causal network:
Causal step evolution vs. ordinary:
(A single causal step involves every element (which can be rewritten) actually being rewritten exactly once [ in the minimal way; i.e. it involves the minimal set of events necessary to have this happen].)
ABABAB
ABABAB
(The rule is essentially the same as AAA)
ABBAA
ABBAA
Causal network:
The final state will consist of a run Bs followed by a run of As. The number of Bs is conserved from the initial conditions. If the initial condition consists of a As followed by b Bs, then the final state will have a 2^b As.
[[ Can do the more general case; Todd knows how ]]
(The cyclic case)
ABBAAA
ABBAAA
Causal network:
Causal step evolution:
ABABBA
ABABBA
At step t, there are 2 Fibonacci[t] elements.
Drawing the final sequence by going down for an A, and up for a B gives:
In general, the string at step t is given by: s[1]="AB";s[2]="ABBA"; s[t_]:=s[t-1]<>StringDrop[s[t-2],1]<>"A". This form implies that the result must be nested.
Note that the actual operation of the rule does not make it at all obvious that its consequences would have this kind of global representation:
Causal network:
ABBBAA
ABBBAA
For ordinary strings, this rule does not lead to growth from an initial condition AB. (There is growth in this case for cyclic strings.)
Causal step picture vs. ordinary:
[[[The situation is somewhat clearer for the cyclic case]]]
ABBBBAA
ABBBBAA
For ordinary strings, this rule does not lead to growth from an initial condition AB. (There is growth in this case for cyclic strings.)
Looking at the sequence after t steps, and corresponding for the fact that there are more Bs overall than As, one can represent the sequence by:
The Case AABX
The Case AABX
The next possible case involves rewrites for blocks of 3 elements. AAB and its various reversals are all overlap-free, so that they can serve as left-hand sides for causal-invariant rewrites.
(With de Bruijn initial conditions:)
What is the distribution of recurrence lengths??? As they get big, are there any that don't appear......
For a given growth class, is the behavior always the same?
AABBA
AABBA
Starting from a sequence of As followed by a sequence of Bs, the behavior is as follows (in the second picture, all initial sequences of As are removed):
Replacing AAB with X, and AB with A gives:
The following shows the result from runs of n As, followed by Bs, for n running from 1 to 50:
Note that in this picture, A's appear only in AB blocks. (Otherwise, there would be AABs, to which the rule could be applied further.) Replacing every such AB block by A yields immediately:
In effect, the rule is
Sequence of causal networks:
These networks are in effect successively nested: e.g. the networks for 4 and 5 are directly contained in the networks for 6 and 7, and so on.
Two Colors—more complicated initial conditions
Two Colors—more complicated initial conditions
These cases give nontrivial behavior with complicated initial conditions; are there single rewrites that give nontrivial behavior forever?
Behavior of several rules of this type:
The "functions being computed":
Mostly these get "computed" quite fast... just a few steps; these are the "halting times":
[A slightly different set of cases:]
(Time increases like the length of the input; see e.g. what happens with input 2^k+1 )
AAABX
AAABX
AAABBAA
AAABBAA
The final states from initial conditions containing successively more As is:
(The following is perhaps somewhat useful...)
The General Case of Single Substitutions
The General Case of Single Substitutions
[XXX] Many rules effectively reduce to rules like AB___. For the general case LR, the immediate condition is that L overlaps R on the left and on the right just once.
Other rules reduce to ACB___.
With left-hand side AAB, the first few right-hand sides that are not of these simplifying forms are:
With cyclic strings, the following are typical results:
"AAB""BBBBAAA" has a recurrence of length 32:
The sequence of recurrences for right-hand sides of the form BBBBAAA etc. is:
with lengths:
More Colors
More Colors
Allowing more than two colors in a single rewrite does not appear to allow more complex behavior to occur. In fact, adding colors often seems to force the behavior to be simpler: in effect, the additional colors increase the rigidity of the system, by reducing the number of places where rules can apply.
Indeed, in cases like ABX, surprisingly few rules with new forms of growth appear when an additional color is allowed:
Propagation of Changes
Propagation of Changes
[[[[ One really needs a dynamic-programming-based BLAST-like string difference computation system ]]]]
Multiple Substitutions
Multiple Substitutions
The following has a linear recurrence in its overall growth rate, but the recurrence is complicated:
Slow Growth ??
Slow Growth ??
Logarithmic Forms of Growth
Logarithmic Forms of Growth
Three Colors
Three Colors
AX, BCY
AX, BCY
A rule which does not give a linear recurrence is:
The differences between successive sizes here are:
The position of the glitches are:
And these correspond to the recurrence {2,-5,4}.
Causal networks:
A perhaps interesting case is:
Example of a long but finite transient (one can see that the rule must always terminate [and TORPA can prove it]):
No other, more interesting, forms of behavior seem to occur with RHSes up to size 3 and initial conditions up to size 4.
ABX, BCY
ABX, BCY
AX, BBCY
AX, BBCY
ACAB, BBCCB
ACAB, BBCCB
Rearranging this gives:
Here is the width of the "active" region:
And the exponential of this:
Replacing every BBC by X, and every BC by B gives:
(Note that these are successive binary digit sequences, but the sequences for particular integers do not appear on successive horizontal slices; rather they are somehow tipped.)
(more)
(more)
Allowing RHSs of size 4, nothing much else appears. There are simple variants such as {"A""CBAB","BBC""CB"}.
ACABB, BBCCB
ACABB, BBCCB
Rearranging gives:
Here is the width of the "active" region:
Replacing every BBC by X, and every BC by B gives:
AX, BBBCY
AX, BBBCY
ACAB, BBBCCB
ACAB, BBBCCB
With various replacements the patterns become obviously base-3 nested:
ACAB, BBBCCBB
ACAB, BBBCCBB
Width of the active region:
ABX, AACY
ABX, AACY
Examples with Complex Behavior
Examples with Complex Behavior
ACAB, BCCB
ACAB, BCCB
ACABB, BBBCCBB
ACABB, BBBCCBB
Approaches to Analysis
Approaches to Analysis
String Length Recurrences
String Length Recurrences
Uniqueness
Uniqueness
Many rewrites can give the same string-length sequences.
Given a string-length sequence, there can also be many recurrences consistent with it.... The recurrences we normally give are the absolutely shortest ones.
Another potentially useful type of recurrence is the shortest recurrence in which all coefficients are positive....
Notable ones are the shortest (lowest order) recurrence, and the shortest recurrence that contains only positive coefficients......
Another potentially useful type of recurrence is the shortest recurrence in which all coefficients are positive....
Notable ones are the shortest (lowest order) recurrence, and the shortest recurrence that contains only positive coefficients......
Many, but not all, linear recurrences can be recast in a form where all coefficients are positive integers. (Sometimes, if one allows fractional coefficients, slightly smaller examples are possible.)
Effect of Initial Conditions
Effect of Initial Conditions
Whole String Recurrences
Whole String Recurrences
If the total-length recurrence is of order k, there certainly cannot be any whole-string recurrence of order less than k. ((What is the analogous condition with multistring recurrences?))
A total-length recurrence can be deduced from the whole-string recurrence by replacing a string by its length, and concatenation by Plus. (What one gets may not be the minimal total-length recurrence.)
[[Can puff up the linear recurrences so that they contain only positive coefficients...]]
[[Given a total-length recurrence, it can perhaps be derived from split recurrences, as well as a single whole-string recurrence.]]
[[[ What is the relationship between the existence of a whole-string recurrence and neighbor independence ?? ]]
Note that multistring recurrences are like multistep neighbor independent substitution systems.
A total-length recurrence can be deduced from the whole-string recurrence by replacing a string by its length, and concatenation by Plus. (What one gets may not be the minimal total-length recurrence.)
[[Can puff up the linear recurrences so that they contain only positive coefficients...]]
[[Given a total-length recurrence, it can perhaps be derived from split recurrences, as well as a single whole-string recurrence.]]
[[[ What is the relationship between the existence of a whole-string recurrence and neighbor independence ?? ]]
Note that multistring recurrences are like multistep neighbor independent substitution systems.
Whole string recurrences (the last column is the string-length recurrence):
The neighbor-independent case:
Neighbor dependent case:
Cyclic case:
Non-cyclic again:
(Note that the above None's could mostly not have been resolved because the search is for lookbacks not as large as the string-length lookback (and presumably it has to be as long as the positivized string-length recurrence).) (The 7,3 search ran out of memory...)
Note: Could consider "string-based recursive sequences" ... though these never be nestedly recursive, because the string is separate from the integer recursion index.
AX, BCY
AX, BCY
Some of these rules have a sequence of different whole-string recurrences on different steps. An example is {"A""BC","BC""AB"}. On odd steps this gives:
and on even steps
ABX, BCY
ABX, BCY
Whole String Recurrences and "Exact Solutions"
Whole String Recurrences and "Exact Solutions"
Note that with this initial condition, there is a whole-string recurrence that has a direct mapping to the original rule:
Note that for each "whole string piece" there is a string-length recurrence.... To find out the value of a particular element, one can work out its "mixed radix" digit sequence, then feed this into a finite state machine....
Connections between Causal Networks and Whole String Recurrences
Connections between Causal Networks and Whole String Recurrences
Long Initial Conditions
Long Initial Conditions
[[?? Computation universal examples]]
[[Formalism for terminating rewrites etc]]
[Sorting; generating primes; etc.]
[[Formalism for terminating rewrites etc]]
[Sorting; generating primes; etc.]
[[[[ See above... ]]]]
Emulating one system by another
Emulating one system by another
[[Emulating CAs with string systems]]
[[Emulating recursive sequences]]
[[Emulating recursive sequences]]
CA emulation
CA emulation
The following is believed not to be causal invariant:
Localized structures
Localized structures
Reversibility
Reversibility
The RHSs also have to be overlap-free....
Emulation
Emulation
Is it possible to emulate any number of rewrites by a single rewrite with many more colors?
Is it possible to emulate more colors with more rewrites? [[Probably doable with blocks, etc.]]
Is it possible to emulate more colors with more rewrites? [[Probably doable with blocks, etc.]]
Algebraic Representations (& Invariances)
Algebraic Representations (& Invariances)
Causal invariance implies that a lump of string with a particular form will have the same future whenever and wherever it occurs (though there will in general be dangling ends, which seem dead with respect to this lump, but could be live if they have a different environment (e.g. any finite lump of ABBA will behave the same way internally, but might be able to "go on evolving" in an appropriate environment)).
Relation to groups and semigroups
Relation to groups and semigroups
Causal networks
Causal networks
Often the causal network looks very much like the Cayley graph for a group (sometimes a free group, so that it is a tree; sometimes it is hyperbolic).
When is the causal network a homogeneous graph? [What are the automorphisms of the causal network?]
Note that even the Fibonacci system does not give an ordinary Cayley graph as its causal network.
Note that even the Fibonacci system does not give an ordinary Cayley graph as its causal network.
With s rewrites, there are in effect s kinds of nodes in the causal network. The local connectivity around each node of a given type is always the same.
Cyclic (Closed) Strings
Cyclic (Closed) Strings
Strings are not necessarily finite.... [String with its head connected to its tail] [A 1D analog of a closed network]
The overlap-free condition is the same for cyclic strings....
In general (for causal invariant rules) there will be at most one more place to do substitutions in cyclic strings than in ordinary ones, and there will never be any fewer places. (The extra place is at the beginning/end.)
The non-cyclic case can be obtained from the cyclic case by adding a "dead element" that marks the beginning and end of the string.
Neighbor Independent Rules
Neighbor Independent Rules
In the neighbor-independent case, cyclic strings work the same as ordinary ones.
ABX
ABX
The behavior with cyclic strings is similar to the behavior with ordinary strings, but there are some definite differences.
For example ABBA applies only for one step in the ordinary case, but continues to applies forever in the case of cyclic strings. (Note that the particular conventions we use here rotate the string in such a way that it seems that nothing is happening when this particular rule is applied.) [[[Note: there is a convention about where a "poking out" rewrite should go; we will assume it always goes at the right.]]]
With ABBAA there is no growth in the ordinary case, but linear growth in the cyclic case:
With ABBABA, there is linear growth in the ordinary case, and exponential growth in the cyclic case:
Causal networks:
ABBA
ABBA
(Note that the first node is special: it corresponds to the whole initial state.)
ABBBAA
ABBBAA
(In the non-cyclic case, the rule yields no growth if started from AB.)
This is given by the whole-string recurrence: s[t]=s[t-2]<>s[t-1].
At t=12, the 3D version tends to get rendered in a non-planar way:
In this graph, every node asymptotically has in-degree 2 and out-degree 4.
Starting from the node corresponding to the initial conditions, the number of nodes reached by going successively more steps on the network is:
[[There seems perhaps to be several types of nodes:]]
((Giving roughly a growth like 2.5^d ))
ABBBBAA
ABBBBAA
(In the non-cyclic case, the rule yields no growth if started from AB.)
Consider the sequence of symbols at a particular step. About 2/3 of the symbols are Bs. Correcting for this, the sequence of As and Bs at step 10 corresponds to:
Note that the basic evolution is such that runs of As must always be of bounded length, but runs of Bs are unbounded. Indeed, the maximum run of Bs (which in the cyclic case with the conventions here occurs at the beginning of the string), is 2+Floor[t/2].
(((The result seems to be purely nested: applying PEncode, for example, gives results that increase linearly with number of steps.)))
This is given by the whole-string recurrence: s[t]="B"<>s[t-2]<>s[t-1].
AABX
AABX
The following shows different behavior for the first rule that grows in the cyclic case, but remains of fixed length in the ordinary case:
Comparing with the non-cyclic case:
AAABX
AAABX
Two Rewrites
Two Rewrites
With two rewrites, cyclicity can make a significant difference:
(A slightly more complicated network develops with more steps...)
The following has a glitch at exponentially increasing time steps:
The first few glitches occur at the following steps:
The spacing between glitches is:
(These glitches are almost growing by a factor 3/2, but not quite...)
Whole String Recurrences
Whole String Recurrences
(Unordered Strings)
(Unordered Strings)
Analog of "pure networks"
Causal invariance is more difficult to achieve..... Only the neighbor-independent case works......
Conditional Causal Invariance
Conditional Causal Invariance
Appendix: Implementation
Appendix: Implementation
Rule Numbering
Rule Numbering
Evolution
Evolution
String substitution updating:
Causal Networks
Causal Networks
String Overlaps and Causal Invariance
String Overlaps and Causal Invariance
Alternative (draft) forms:
Linear Recurrences
Linear Recurrences
Code Used
Code Used
Initialization
Initialization
Added October 2019:
The following was merged here October 2019:
Evolution
Evolution
Basic Evolution
Basic Evolution
For the annotated graphics
Count total length at each step:
Random choice of updates at each step:
The following are Todd's various visualization functions that "all do something different":
Annotated Evolution
Annotated Evolution
Causal Step Evolution
Causal Step Evolution
This attempts to do enough rewrites to make every element be updated at least once (assuming that it is not "dead").
[[[ These functions are quite slow ]]]
Rules & Strings
Rules & Strings
Rule Numbers
Rule Numbers
Note I would prefer adding {1,0} so that FromSSNumber does not yield rewrites ""rhs.
Old Version (with large gaps)
String Differences
String Differences
Causal Invariance
Causal Invariance
Causal Networks
Causal Networks
Basic Causal Network Graphics
Basic Causal Network Graphics
Todd's version
Todd's version
Cyclic string causal networks
Cyclic string causal networks
Book version
Book version
(The Partition[Flatten[ ]] is a complete hack...)
Analysis
Analysis
Multi-String Recurrences
Multi-String Recurrences
Ordinary Strings
Ordinary Strings
Cyclic Strings
Cyclic Strings
Dictionary Encoding
Dictionary Encoding
Graphics
Graphics
Basic Evolution Graphics
Basic Evolution Graphics
Rule & String Graphics
Rule & String Graphics
Rule Graphics
Rule Graphics
Textual Graphics
Textual Graphics
The following need modernization:
Graphics Utilities
Graphics Utilities
Book Graphics Utilities
Book Graphics Utilities
The following are preliminary versions of V6 forms:
The following uses Inset instead of Rectangle
Summary Tables & Searches
Summary Tables & Searches
External Interfaces
External Interfaces
TORPA
TORPA