Second order point statistics are homogeneity measures of how uniformly the points are distributed within the observation window. They are used to study data locations in relation to other data points.
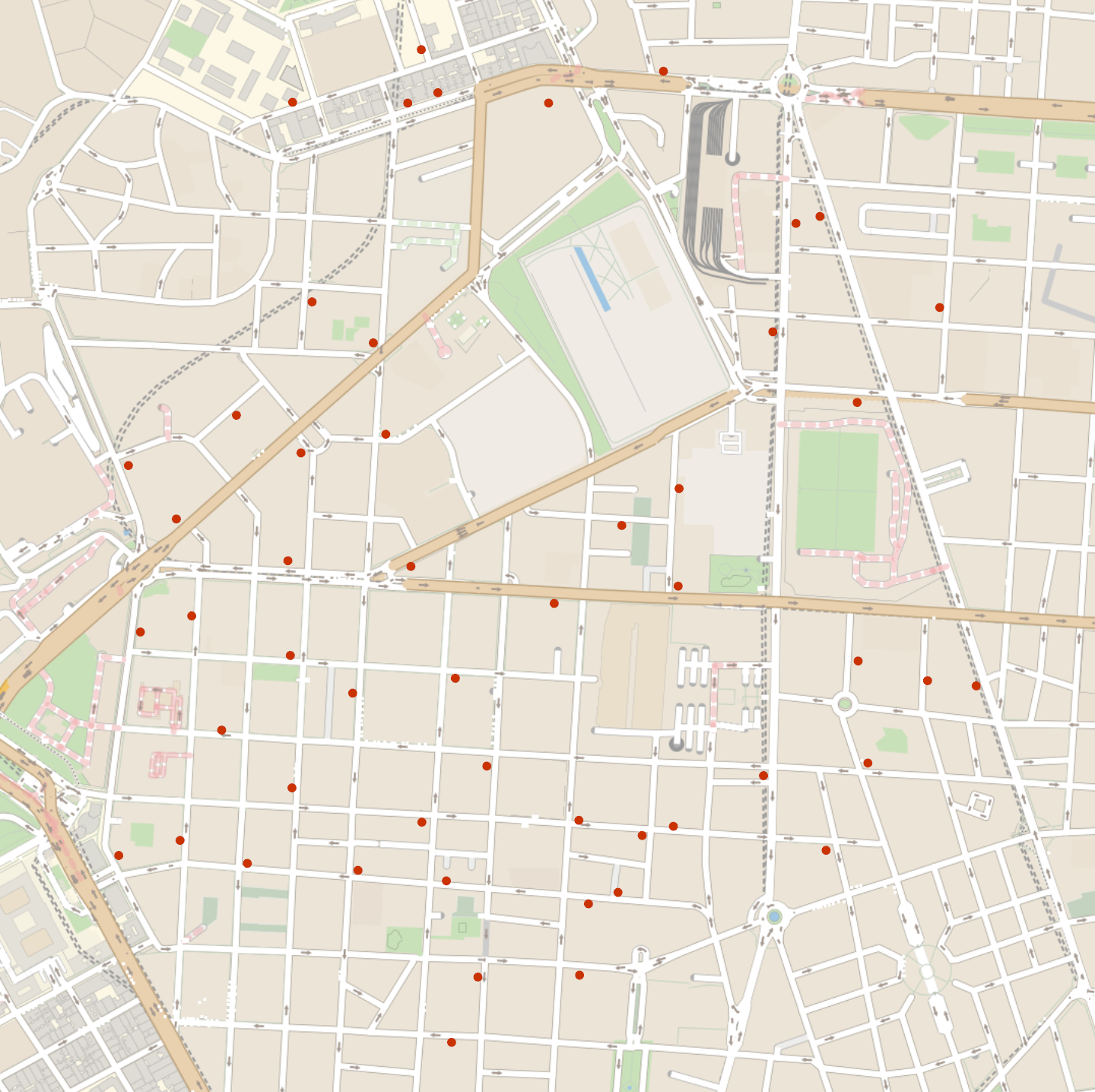
Location of pharmacies in a part of Madrid city:
Create SpatialPointData with the observation region inferred from the data points:
Visualize the data:
Test if the locations are random:
So it looks like the locations are random, but are they arbitrarily close to each other? For the answer we compute NearestNeighborG:
Compute maximum radius for the point statistics function:
Maximum radius magnitude in meters:
Visualize:
So the plot of the NearestNeighborG of the data indicates that pharmacies cannot be arbitrarily close to each other. The limiting distance is called hardcore radius and such data can be modelled by a HardcorePointProcess:
Estimated hardcore radius is:
Since the pharmacies cannot be arbitrarily close to each other we can ask what is the expected number of pharmacies within given distance from a given pharmacy - that is how big is the competition within the given radius. This can be answered using another point statistics function - RipleyK:
The product of the value of RipleyK at r and the mean point density gives the expected number of points within distance r of a typical point, not counting the point itself:
What is the radius within which the expected number of pharmacies is at least 1?
The expected number of pharmacies is at least 1 within the radius of at least 149 meters.
Now let’s compute the probability of encountering a pharmacy within given distance starting from a random location in the observation region which is not a point of the data. The point statistics to do so is EmptySpaceF:
Value of EmptySpaceF at r gives exactly the probability of finding a point within distance r of an arbitrary location which is typically not a point of data set:
The probability of encountering a pharmacy within 100 meters of a random location in the observation region is:
![locs = GeoPosition[CompressedData["
1:eJwVknswlFEYxjdMpq0ziUKJMqgkkmltaJey1E5X0qQLItWUa0OhEjVqXULt
MuyQFivkfsndzjFtaciEmRqXwiQlWTMUoWw9+8c33/zmOc/7vO97jrFfiPtF
NQaDsRuf6j9eYZTPZfOcZk+n53MrCbXPrKvNB49tcMpYLSH0X89lzW6w1+bH
fxrKCe1saRImg7+vyE4kxYT6V7jmmu3hOTFFJ5nvSgiVxo8EzkFvvZE7GFdL
6PjS+TNt0DvOxsq3ZBFq/JKtPA89MNmo2aCC0H3WOeZi8IW51F4+zq8NlHEW
wWqsbR1CMaHFGk+dp+HXXTP26AT6MS919LKx4zmp+zK/fkC/H6RnH9ZC73kZ
YuCVR6gzb2j+M/wZzFMcqyZCU+eXHlSDLw+HcgVVhCbqcqNrwB4BWQGy54RG
CsS92WCJRsMZ7UZCE/RMJ3egfs3gt/cm1YQWzcTmiaBP35txiERe2IImo1N1
XqedL0feChsLrhK8LPhi21roGTrR+T1gsbZv2L4cQiOksugS8GHDJyK1Iujs
Rgcm+lWueuFjW0/o7P4qz0pVP9yP9sXPCNUTsAs5yBckDBK9QkIlB0qUEui/
ckzfSGSE1u1KStOF3yvq/vaqVkJt333ZuBfMULC83VAv1JCt7Q5mhd88aNJC
qNYllyQB/O1ShYkH5h06zukPh/57szKI1hEaF9e7zg88p2/Au4r81z5u+nbg
Y2mXBhmY32zatN5Ktd9lr1nh0GPMI6+kgm8Pt2fWY777Gc5COeovbf3kb4r8
muSdRXegt32VB+rWEGqVN6q1CdzlXDYa1Uzo4dIjJzTB/ikFh8rgV678kaMA
vwryeXsul9DbbxcaysEWE0JvCfzXJ4S7g8FGEdviWZjf87m48CjY0fqPbBT7
DP3Spe6H/MRrkz/qMB/Z47Gcj/3tEhhopOC+FYv8pb/QFesLV5Xh/XWns6ZU
9xvT1ddHSgntt7l1VI56Plq5Iy7Yx8AFYzdL6KIp1xhDzDPA/zlVBD9HK8py
Ef27qT8oiMf5qrm79Yl4L/8Bpi50/Q==
"]];](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAApgAAACKCAYAAAAOsDpwAAAAz3pUWHRSYXcgcHJvZmlsZSB0eXBlIGV4aWYAAHjabU/bDQMhDPtnio4QEnBgHK4HUjfo+A0QqaKqJWLjPCChv18jPCY4UkhZCypAhlRT5Wai0MbmSHXFhVqI3T38UNoWsZmVvwl096/TV2zm8jPI55PMF0xL8gYfJLz96A9eXs+tlGPQuMaCL7Ny/vW/9yTKyIiaLCYmVVTTJZg0QmbKioEnYIURN1N6GneoWht0VkibjRPc9azuAWLGPVeQeViaxBVtWWvdmqW6c1vMS891PrfkXGj4S5nYAAAACXBIWXMAABYlAAAWJQFJUiTwAAAAPHRFWHRTb2Z0d2FyZQBDcmVhdGVkIHdpdGggdGhlIFdvbGZyYW0gTGFuZ3VhZ2UgOiB3d3cud29sZnJhbS5jb21coqaFAAAAIXRFWHRDcmVhdGlvbiBUaW1lADIwMjI6MTI6MDEgMTI6Mjk6MDHb1A0uAAAgAElEQVR4nO3df1TU953o/ycqtlANZFA4IesdgRocKfp1gkFIbsLdiD821GyU1N5N9eipyzeb7zexm/M1uXfdrM1p3W9r7/U0zfm2d1l7khvWmxCsuWvcVTuQi7QFxk6GI8lkUFYHap1cSeSHRaiQZL5/fPx8mN+/mGGY4fU4hxPm8/P9ec/EefH+8XqDEEIIIYQQMeJyuZiX6EIIIYQQQojUsiDRBRBCxIfD4fjy4sWLV6elpT3mcrnWpqWl3ZXoMgkhhEiYzwCny+U6B5xdsmTJ7+N5s7R4XlwIMfOuXbu2JD09/Z9cLtfGtLQ0+X9cCCGEj7S0tFsul+uvc3Nz/zHW13a5XBJgCpFKrl+/vn3evHn/3eVyfQVg3rx5zJ8/H4kzhRBCAHzxxRd8/vnnuFwuddNvXC5XbV5e3v+O1T0kwBQihVy/fv3/AN5PS0ubt2DBAr785S9LYCmEEMKvzz77jD/+8Y9qoNmRm5tbGatryyQfIVKEy+VakJaW9k5aWtq89PR0MjIyJLgUQggR0IIFC/jKV76ifldUfPLJJ/9nLK8vAaYQKeDTTz/dByyfN28eX/rSlxJdHCGEEEkgLS2NL3/5ywC4XK5XXC5XzCZ/S4ApRAqYP3/+nwOkp6dLy6UQQoiwLViwgHnz5gF86dNPP10Tq+tKgClECvj888+LQfmHQgghhIiE+t0xb968rbG6pgSYQqQAl8uVA0jrpRBCiKi5XK61sbqWBJhCpIZ5IAGmEEKI6MVyQQ4JMIUQQgghRExJgCmEEEIIIWJKAkwhhBBCCBFTEmAKIYQQQoiYkgBTCCGEEELElASYQgghhBAipiTAFEIIIYQQMSUBphBCCCGEiCkJMIUQQgghREzJwsVCiFkjI+Nd7ffx8a8nsCRiJrS2tjI6OkppaSl6vT7RxYm5wcFBuru7GR0dJScnh4qKikQXSTM4OIjFYmHJkiUYjcZEF0ekIAkwhRAiiVitVpxOJwCVlZXodLqAx/b39/PBBx+Qn58/K4MIh8PBwMAA+fn5KRdg2u12Tp8+zeTkJAC5ubmzKsDs7u6mq6sLYFZ+NsLV1NTE1atX/e5btmwZTz75pM/2wcFBWlpatPNWrVrF5s2b41rOuUgCTCHEnJPMLaVOpxObzQbA0NAQO3fuDHjsjRs3tGOTOYhIRmpw+fDDD1NRUYHdbk90kTysXr2aiYkJlixZErNrdnR0zPgfCw0NDZhMJr/7qqurfQLMM2fOsGfPHoaHhz22FxYW8uabb7J69eq4lXWukQBTCDFrJFuwl2hOp5OOjo5Z1TImlNbLyclJj1ZLg8GQ4FJ50ul0bNy4MWbXO3XqFDabjerq6hkNME0mE0ajkR/96Ec++xYtWuTxuru7myeeeAKj0chLL73E5s2bcTgcvPPOOxw4cIBNmzZhs9mC9gqI8EmAKYSIuWhaCN3PcRfq/GRujZyO3NxcBgYG6OjooLi4WL4UZ5Hx8fFEF2FOycnJobKyMuRxo6Oj1NXVcfDgQe3/l4KCAp5//nn6+/upr6/nxIkT7N27N95FnhMkwBRCzDmpEIguXbqUrKwsent7aW1tZdu2bWGfq47jDDQ2M9Dkm1OnTgFQU1PjMYFl0aJFrF69WvvSdt+3cOFCiouLw2rVstvtXL58GcDnmv5432fZsmV+Wwq9n0d9XVRUFHbLovvY10D3Use83rp1C1ACGrXOwhkH613OaOrj4sWL3LhxQzunoKDAb92rZV20aBFVVVU+z6mWt7+/n4sXLzIxMeFzrPvxn3zyCQC9vb1aPXl/ftyfx9/noqOjAyBuLfL33HOPR3DpbsuWLdTX13Pz5s243HsukgBTCCGSVFVVFdeuXaO3txer1Rr2OEv3cZz+zgk0+UY9p6ioyGMCC8AHH3zA1q1bGRsbo7m5mbGxMW1fV1cX5eXlPsGJu8bGRvr6+jy2Wa1WtmzZEjBotFqtHmXo6urCbrf7BNvuz/Pee+8xMDCg7QsVYNrtdp/nUe/V2dnJ448/rgUs7mNeAcbGxjxeh3p/3MvZ2dk57foAMJvNrFixwqdO1LLm5uZ6vC/un42+vj56e3s9zuvp6eEb3/iG9szux6vnqNTPz+DgIP/8z//sUe+g1OGLL74IKPXc1tYGQHZ2dliBv8PhACArKyvksaC0VoqZIwGmECLmomkhjLZVMRVaI6Ol0+l48MEHMZlM/OY3v2H58uUz0lXe3NzM1772NTZu3Eh/fz9tbW04nU7ee+89RkdHyc3NZf369SxevBiLxUJXVxdWqzVgC9z58+cBtAkxauuazWbj9OnT5OXleZzX2tqK2WwmKyuLBx54AKPRiN1ux2Kx0Nvby6lTp6ipqfG5T29vL0NDQ6xYsYKFCxeSn58f9DnVmeAAa9eu1Vrc1Hs5nU7efvttnn76aUAJII1GI1arFZPJRG5uLnv27Im4fqOtj8zMTCoqKrQhEx0dHVy4cIHe3l5OnDgRUSv373//e48y2O12zp07x8jICCaTiR07dgBKa3ZNTY3HGEzvQFoNLteuXUtZWZlWtp6enojrxt3HH38MwMjICEeOHAGUmeNlZWURB5Pq+7xq1applUlMkQBTCCGSmNFo1Fqa2tvb/QZWsVZQUKBNENHr9Tz22GO8/vrrDAwMkJWVpQUfABs3buT69es4nU76+vr8BpiTk5M89dRT2j69Xo9er2diYoLe3l4sFot2v8HBQaxWK5mZmR4taQaDgby8PI4dO8alS5f8lvvatWsBWwD96ezsZHJy0idoMhgMGAwGGhoacDqdtLa2Bm2djVQ09ZGenu5xDqAFm8eOHaO3t5f+/v6wJ+CMjY2xfft27XiDwUBmZiZvvfUW165di+h51M+F+6SiiooKj65wg8GgzeyOdEKUyWTymUn+wgsv8PLLL4d1fnd3N/X19RQWFkq6ohiSlXyEECLJVVVVkZmZic1mm5F0OKWlpR6vdTodd999NwArV670OV7dp47N8xZoktL9998P4BHQWCwWJicn/Z6j0+m49957mZycxGq1+lxv+fLlYQcvdrudgYEBcnNzA3Ztl5WVAQTMwxitaOrjvvvu83uOTqejuLgYgIsXL4ZdhnvvvdcnGNXr9eTm5jI5OUl/f3/Y1wIlYB0cHAx6jHfQGcrKlStpaWnBbDYzPj5OS0sLr776KtnZ2Rw+fJh9+/aFvEZ3dzebNm0iOzubN998M+x7i9AkwBRCiCSn0+m0YOfcuXNxv1+wVrC77ror4usFysWo3md0dFTbNjQ0pP331KlTPj8jIyMB77N8+fKwy3T9+nVAmUwViBqsqpN6YiWa+gjW3a9ez/28UL7yla8E3a9OJArHihUrmJyc5PXXX+fUqVMRB6eB6HQ6KisrtdyVlZWV7N27F5vNRnZ2NvX19do4TX+amprYtGkTAGfPnpUcmDEmAaYQQqSAiooK8vPzGRkZ0WYupwr3CTbq7319fdhsNp8f74kk0YokGAsW1MaDv/oIx0yXU7Vt2zbWrl1Leno6NpuNt956i8bGxpgFmt50Oh11dXWA0sLrbXBwkH379rFr1y42bNiAzWaT4DIOZAymEEKkCHUs5KVLl4J+eXsnoJ7tcnNztd8XLFC+tvxNJomlhQsXhn1suLOYY8VffYRjpsvpbuPGjWzcuJHW1lYcDgd9fX1cu3aN3bt3x2Vimvqs3sMXBgcH+frXv86VK1d44403/C4lKWJDWjCFECIKGRnvaj+zhU6no6KigsnJSd57772Ax6nd2BMTE3733759Oy7lCyTQ/dS8iJmZmdo2dTxnvPMVLlu2DJjqgvZHHe+qlilWIqmPvLw8AD799NOA11P3zYZk/FVVVezZs4f8/HwmJyf9tjDGgtpa6z0rXA0uz549K8FlnEmAKYQQEZhtQaU3tat8YGDAJ4ehKiMjA8DvbGCr1TrjXamB0tWo21esWKFtKyoq0vYFmjQSi65Xdda00+n0O2EIprpf3csXC5HUhzqB58MPP/RbH2ry9fT09BnpBg73j5OvfvWrgOcfOR0dHVoQHY7u7u6A2+vr68nOzuaBBx7Qtjc1NWG1WvnJT34iXeIzQLrIhRAixahd5d6JulUGg0HLadjY2Mj69eu1FW7UlDfeCbvjaWhoiIaGBsrKyjAYDFqeSTXpuHeKILvdTm9vL2+//TZr1qyhoqJCC6R6enpYunRpTNbDVnOMtra24nQ6PVbYUfNgLl++POZd9ZHUh16vp6SkBJvNxrFjxygtLdXyjap5MMfGxigvL49rC6Y67OLf/u3fKC4u5g9/+INWvtdee42VK1dqs+PtdjsXLlwApiYnRZNo/W//9m8BeOaZZ7R1xS0WC8899xzDw8O88cYbHs988uRJQGndbG9vD3jdlStXzorW3mQnAaYQQkRptiZ51+l0fO1rX6OrqyvgMY888ginT5+mr6/PIxAtLy/XVpSZKUajkZ6eHk6ePKkFAaAEH4899pjP8du2bePEiRP09vbS1tamBSYA6enpflMlRVuu27dvY7FYtElE7vytkBMLFRUVXLhwIez6UHOfXrp0CbPZjNls1valp6eHXEUpFlavXk1PTw9Op5N//Md/BJRxsnq9noGBAQYGBnzep/Ly8mkF51lZWRw/ftwnB2Z2drbf8ZVqy/yzzz4b9LotLS1hrW0ugpMAUwghIpDooFJt8Qm1Co2a1HpiYsLvsWpi8kBrhi9dupScnByPc0pKSgLer6CgwO85wcqsnlNQUEBVVZW2FjcQcp3wbdu2eayTrV7fX8ASrGyhqLkZOzo6wlrjGyAnJ4eSkpKoJ1N96Utf4umnn46oPrzXh1fLESinZqAyhvp8BapLnU7HN77xDY/16dW0UN/85jdxOBxByxVNovWGhgb2799Pc3Oztm3VqlUBk6Xv3LkzrED7nnvuCev+Iri0RBdACDF9AwMDLoDFixcnuihCiCi99tprDAwMxH2GvBDebt++zcTEBPPnzz+Xk5NTNd3ruVwumeQjhBBCCCFiS7rIhRBx5T7jOtHdy0IIIWaGBJhCCDFDJNgWQswVEmAKIYQQs8B0JiMJMdtIgCnE7PdN4N8F2Hd4JgsSjWRvqZNWRzFT4p1KSIgwPQQEytN0HLgSzkUkwBRi9tsNbAqwb9YHmIHMxcBtrjynECKpVQI/DLCvnTADTJlFLoQQQgghYkpaMIUQIghpdRRCiMhJC6YQyeVFlAUS1J+kNT7+de1HCCHErHGYGHzPSAumEELEwFwcUyqEEIFIgCmEmBYJrIQQQniTAFMIkTASnAohRGqSAFMIIWJAAmQhhJjiPsnnIeAFtx8hkkEhymd3uktf5Ny5TuG0SzTHBJqsk5HxrvYjhJi+wcFBtm7dSkZGBlu3bk10cYSXjIwMMjIyOHjwYKKLMiu4t2B6J9ZM2gTOYs74JvDmnd+HgBXAjSiuswb4X8Ddd17/e+DX0y5dkprJbmtp9UsNra2tjI6OUlpail6vT3RxZsxMP/eJEycwmUzU1tZKgDkLHTp0iK6uLg4fPsymTZuorAy0GM7cIF3k8bMGWA9k3Xn9O+A8YWbAT4BgyxGCkr3fyewq/2633+8GDPgGhu5LXgVa4moTU8Eld46fswGmmN2sVitOp5P8/HyMRmOiiwOAw+FgYGCA/Pz8ORVgzvRznzx5EqPRSENDQ1jHHzlyBIAnnniCgoICv8c4HA5aWlq4efMmd911F48++mjAY8PV1NTE1atXWb9+fVyDrNn2fM8//zwAx48fp7OzUwLMRBcgBb0A1AFFAfb/DHiJ6Fra4mk3gZcjdHcWJRfjhbiWJjzv4Vlmp59j/m9gx53fAy1x1e71+nfTL5pIhtbJZJxk5HQ6sdlsAHEJMPv7+3E6nVRUVMT82mL6cnLCGw3U1NTEgQMHAFi/fr3foOrgwYMcPuzbWfnGG2/w5JNPRlU+h8PBrl27AKVFL15B1mx/vtbWVi3gnKsk0Xrs5AC/RRlmECi4BPgroBelhTMZbULpTp4N5T8M/EeUgLcI/8FjdhjX+TVKt/iLd/77VqwKmIwkAfrc9tZbb9HT05PoYgg/TCZT2Md+97vfDbr/yJEjHD58mNraWsxmM+Pj47zxxhtkZ2eza9cu2tu9/+4Oz49//OOozotUqj9fKpAAMzZygDNAmdf2RpSg5cU7v6vuBhbPTNGiorZSqj8/Ay677b8b+EUCyuXPWyiB5nS77n995zrSNS6ESGpHjhzhypUrFBb6n7PocDg4cOAAhYWFvPLKK6xevRqAJ598kl/8Qvmn/Qc/+EHE921vb6e+vj7gfWMl1Z8vVUgXeWx8D8/gshH4v/DtBv9/gaPAf2V2BzLv4X+S1wtMTQQrQhnfOJufA+CBRBcgVSRjd7IqUNmT7TmipY7bBFi4cCHFxcU+YwZPnTql/T46Oqq9XrRoEVVVVRHdz263c/nyZe381atXo9PpAh4/ODjIxYsXuXHjhnZOQUGB33GNocagBpp4oz5PTU0NAB0dHdr9Qk3S8S5fUVERBoMhaB0MDg7S3d3N6OgooHRtew876OjoAIjpcASHw8GPfvQj6urqcDgcXLni+7d3S0sLoLQCer8vlZWVFBYWYjKZGBwcDPq+edu/fz+FhYV8+9vf1rqvYy3Vny9JqXMd2nGLCaYTYK5havzbCNBJZOPyClG+/NWJJR4FC3E/UFrZZsM4wEKUbm9VI8qEGX8uAJsJb/yld/18CPxrBGWqZmqCUai6Dddh4D8xNSEm2GSYnDtlcC+/mfCePdz32n0Cj1o+73u7T975C7fjf8dUV3ghUOt2XKDJQP7KF85n372c7u+F93VMIe4rRESsViu/+c1vGBsb89je1dVFeXm5R+CojusEGBsb017n5uZGFGA2NjbS19fnU44tW7b4DcpaW1uxWq1MTk56bDebzaxYsYJt27Z5bA81BjXQxBv1nKKiIpqbmz3qxGaz+dSHqqOjg46ODo/y2Ww2uru7A9RA4Ge6ceOGFuDa7Xba2toAyM7ODhmwhuvv/u7vAGX84e7du/0ec+7cOQDKyrw73RQbNmygvr6enp6esMdQHj16FKvVSktLC52dnZEXPEyp/nxJ6CHgV26vtSws0QSYDwGv43+cYTgTQNagtIL5m1BiAfZ6nb8GpdXP+5PywzDvF2/f9nr9NyGODxVg5QDPB7jOZeA5AgeahcBP8V+3oc4N1/kA11cFK/8Q8AMCp8CK9L0OlFrLwFT6InfufwicZSrAzPe6TqDJQNF+9t3L+SLwBwL/P/AfmeNjQEXsqK2W5eXlWoug1WqltbUVs9ns0Ur44osvAvDDH/6Q3Nxc9uzZE/H9zp8/D8DDDz9MRUUF/f39fPDBB9hsNk6fPk1eXp5Hi5FajszMTCoqKiguLkan09HR0cGFCxfo7e3lxIkTPkHmdJw7d46CggJKS0tZvHgxFouFrq4un/oAJTBua2sjPT2d8vJyrau1u7vbbwCpnmM2m8nKyuKRRx7BYDBo9bBw4cKYPYc/TU1NHD9+nFdffTVoy5zVagUIOJtarYOPPvoorACsu7ubl156idraWiorK+MWgCXL82VnhzP0P2X8hdfrLUQZYLrnHfRn052fQF+Soc4vQ/ni3XzndQ6e+Qn93e+BO+clquVno9vvjdMsR6CxnKoi4F+Ax/ANFL1zOQY692fAM9Mon3tQ5D3bOlT570Z5f5/EtyV3tr/X0/3sq+rwDGa9vcksTWcVSXfybOtOnw1lSISioiKtxUxlNBq5efMmZrOZDz74IKbpdSYnJ3nqqae0L3+9Xo9er2diYoLe3l4sFgsbNyr/ZA4ODmK1WklPT/c4B9CCzWPHjtHb20t/f3/Mypmbm+tRJxs3bmRoaIi+vj4uXrzocZ8LF5S/F6uqqjxaS6uqqsjLy+PkyZM+11eD+jVr1mitkmo9uDMYDAwPD2u/hysrK8vvdofDwXPPPUd1dTV79+4Neg1/3cr+3Lx5M6zj/uqvlL/dX3nllbCOj0YyPd+6deu04RRzWSQB5ho8v2CHUL5I+4DleLYO/RTfL0nv80FpsWxC6crdAehQWnhUtXgGHD+7c7+sO/e7G/glob+MvZtwwxVOwm33YMrqZ3+w/JLeLXn/n9f1zqKMhwTP1Ec/wTPAzEGZdONeV413yuNeV9z5/RTRtWR+z+v1ea/X3uVX31/wLH8ZSiun+yCWWL3XoKQrehHfz6V6TYgsFdF0P/vu1DoYulOeEXzTWlUD/xBB+VLCbAtKU4F34GK32xkfH+f69etxuZ/aAunt/vvvp7e3l2vXrmnbLBYLk5OTlJSU+D1Hp9NRXFxMV1eXT+A3Hffff7/PthUrVtDX18fQ0JC2zW63MzAwQG5urt+ueIPBQGdnJwMDA37vE06AEcnYS7VLfu3atX73f+tb3wLiG+T5c/DgQaxWK++8805E4xkjlUzPV1BQENGM/yT3P/D8Djyt/hJJgOne6jIE/Ac8uwP/gakWqLuB/wfPlrL/7HU975aeIyhdm+7XdP9Tzbvl7QhK9/TPw36CxNhN4C5l9wDzIabyNYJv/fycqdbBIuDPmAoSv41ngOKvbt1bFr0DVG9/6vV6OUqg7B3AugdR3uX3fr8OowRf6gfxb+48k3qNWL7XV+7c7yE8P/j/g+jGok73s+/NgmcL7s9Rxqeq7+F/YA4GmIkwF4LaU6dO8fvf/56RkZG432vJkiV+t6vBoTrhBdCCufz8/JDXcz9vuoIFqu7jMtXWxaVLl0Z0/dLSUi5duoTNZuOTTz5h5cqVMZnEo85+XrVqlc++ffv2aUHQdJOIR6KpqYnDhw/zwgsvsHnz5tAnRCnZnm/Lli3U19dz9OjRkK2tKUBN8xf1JB/vrtEf4DvW7AJKYKCOvfsrpr5kc/AMPl7EtxvxBr5f/u7/In4TaHM77waptZzlFrffG/FfP/+VqZa0rzEVJLpnjHUfW+h+7kGULnIIPQNc7e4NxIIyS96de/mHUJLJe3sJz4Cvlqn3cLa+19P97PvjPTzgBkrrrFo3ST+AJ1WDtWTz2muvMTAwQFZWFiUlJeTn55ORkcH4+HhCWljcAzjviUfBzERw7C3aLk69Xs/27dtpa2vD6XQyMDCAxWKhtLQ04tn4qgcffBCr1UpdXZ1PoNPU1ER9fX1cgrxly5YF3Nfd3c1zzz2H0Wjk5Zdfjul93SXj823evJm6ujqeffZZrl69Gtf6mSV+jZ94ItwA03uASKAMpafxnNyxBuXLN9zzvf0DyqSfMpSWoTdRWsF+CfxPwp8MoXaZRsrfyjCRep2pbm4IPP7Ovd8mGyUlkLflAc5175Z+L8Ax3i2WJUTXmvf3KC2K3v/6upf/vJ/93Nl2lqmAzb3fKVbvdaxN97Pvj7+66YusWIkRzxa/6V5vLrRGRqKjo0ObTb1z506PfeokiJmWm5ur/b5gQfgdaO7jDhctWhTTMgUynQk5er2enTt30t/fz/vvv09fXx9ms5nR0VGfMbHhsFqtZGdns2PHDo/t3d3d7Nq1i+zsbLKysrSlE1VqqqjGxkY6Ozu1JRWrq6uDpunp7+8H4N577w1Ypk2bNjE8PMyGDRt87tva2urx32iXjEzm53vooYeor6+nq6sromdOJdGmKQo3MAmUTDySwGYzyng9dRze3SitoTuA7wPbCT2LXO0yjYfLTHVt+lu3zTswCjbBQxWqBRE8u5TdhRu8BzofPMd+ul/XTnhphgIFud68W+pi8V7H23Q/+0lhrgRrqfxsagvcV7/6VZ99n376aVzuefv2bb/b1XyPmZmZ2ra8vDycTmfQsqj73IOEu+66C4CJiYmIyhAptXv+1q1bAY8J1XWvTu6x2+2cPHmSS5cuRVWWa9eusXv3brZv347NZtPqQ73/8PBw0LyM9fX1wNSSimvXrsVkMtHS0uJ3ycTm5mays7ODBoXqEAJ/SzGqTCYTJpMp6iUjk/X51OUk6+rqZnzM6GwSbYA53QTbkZx/A2UyyBGUyQ9/zlR3exHK2LdQM4tz8G2JCkc4AZV71+YO/CdYj5S/AM9boEAyWG7KcAVKtB6uP43y/Fi81/GWDMnlhdD84Q9/8HitJg0PJtograenx+94Q3XpyRUrVmjb1Ak8H374IWVlZT4tTWo509PTtfRAABkZGQAeE4ZUVqs1Zt3pRqOR1tZW+vr6sNvtPhOmWltbw+7mNxgMnDt3zqds4SZa1+l0PPPMMzzxxBMeQdPKlSu1pOL+7N+/H6vVyquvvsqqVatYuXIlANu3b+fw4cM0NDT4BGBnzpzhypUr1NXVeWzv7u7m/Pnz2pjCYPdtbGykvr6euro6duzYwT333KPta2pq4urVq2Gt052MzwfwzjvvAPCd73wn5DOmsnADTLvX60BBzBav1+ox4Z4fzA2U1sC3ULoiG5nqTnUfy+ePgfjNIveeQfU9oksD9D6erZaRBGgWprrJAwV3f+b1OrqFWANzL/8DKEG9d6DtPZ4xUBA9nfc61qb72U8p4bb4JaIFNJVbI/25detWwK5uo9FIUVERNpuNDz/8kMWLF1NRUYHdbg+Zwy8zM5ORkRGsVitGo1H7bziGhoZoaGigrKwMg8GA3W7HYrFoXfXu19Hr9ZSUlGCz2Th27BilpaXaij9qHsyxsTHKy8s9gk/3YK2xsZH169ej1+u15Obp6el+81NG47777tNyeA4PD1NRUcHg4KCWOzMzM9MnyPzlL3/JxMSEttqPevzIyIjHEIFIE62r4w+vXr2qbdPpdEFb4XJycgBlYpD7catXr6a2tpbjx4+zc+dO9u/fz5/8yZ/Q0tLCc889R3Z2NgcPHvS4ltplDLB3796g91U/Y3q93ue4Xbt2UV1dHVaAmYzPB8ofH4WFhTM6IWk2CjfA9B4795/wXV1lDb4pYQKd/0M8V1JRvYAyo1YNTNagpN/ZjecX9hXgt0wFVcG6e+Pt13g+m1oHL+EbYHOfZpAAABS+SURBVAVbwNR9DN8m4BCeaXxUD+HbstrEVF1sQpkk4163OYD7KOPLxD4Aci//3fgPtL3THB13+z0e77V3cBjNuNPpfvaT0lwL1mJhpoPqvr4+nxVzVEajEYPBQHd3N319fbS1tWnBTFZWFmVlZdprb6WlpZjNZq37L1CankD37enp4eTJkx45IvPz83nsscd8jlfHI166dAmz2YzZbNb2qcnN/U2MeeSRRzh9+rRPHZSXl2sr+cRCTU2NlsPTvQ7VsjkcDp8Ac2JiApvNhs1m86iD3NxcHn/88WmXqbW1NazgLBS16/b48eMcPz71T3FhYSFvvvlmXFIOqamWtm7dGvNre0vE87krKvK3HkfKUler84jr3ANM7xatQ3imkfk+U1+yd6N0VwbKBTgE/Bev67mfD8okjt0orVhqHsyiO7+rgdXRO9t+hWdORSOes9IjyWkYD8+glM891+Q3UbrP1SYGI55J2b15B6p/g/KMjSgzrLPunF+GMmHJvRXv53gu4fgmSveyvzyYoKzoE2v+Au11+M+DCcpkIfeu7ni81zdQPovqs/83lJykan2Gu5jsdD/7IkqpMhY0ls8RLK2Ptx07dnisC66uh93f36/NKvemJhFXzwnni7KgoIClS5dSUFBAVVWVth64en6w1rmamhq/63YHyqkJSitmXl6edo73+upLly7VWrdUJSUlAcuQk5NDSUmJ3wlE27Zto7+/n4sXLzIxMeGztrr3vWpqasjPz/dY+33ZsmU+dRBtovVI7Ny5k6qqKp8uXFBaBxsaGti/fz/Nzc2A0hIYaKb22bNnPbqQg1m/fj2HDh1i/fr1HtvVlZ4effTRSB/Fr9n2fCqTyUR1dXUET5LU/oypDDWgfMceBkhz21iI0rLlzjufYqjVTAKdp3qB0JNchgB1oE6wVWFUl4Fygo97jOcYTJXaAhfuny1/j2+AE2olHNVlwHvkfqiVfFSBVvI5w1QQ5R3Ahivc8nvngYzkud3fa+/PU5rPGcofSoGW71SPD7iWqpvpfPbDKaf7MWeZWs0KwnhvBgYGXACLF8/+uUWRBFvJFGAGK6u/fcn0bGJ2yMjIoLq62u8KQslg3759NDc3e6x7n4qS8X26ffs2ExMTzJ8//1xOTk6V126X2+/e34/e329DgM7lcjHPbeMVlKDHnfcKNG+hLFPoHYiqLt+5eaCUModDnH8WJcn0jTs/61C+UIeCHL+R0EGgmmMz0p9IJutcQAl+gpVXLfO/x3/r2Q2UwML7fXD3M/y3hF5AqbuzAc4bAp4m+mUiw6GWP1gX8d/jPw9krN5rb0cIXCdrIrjOdD/7IsWNj39d+xFC+LJYLNTW1ia6GCK2PvR6rTVyeY/BPAD8BiWJN/j/Yv7XOz9rmGpVGQE6CS+FjHq+2mcf6vzDd37+zK1cI4CJ2bdes5oQXF1FpoSpMYO/I7w1pt1nUpcz9czhnH8BJXgrRJmFrd7bI7t+AK8zNelmOhOAbqAEsS/dKYP6R8qHKKvVBAsQI32v2wmd31QNeoN9Xr3zpAbKfxrtZz+ccrofk+ghH7NGqgRrqfIcQkzH9u3beeKJJxJdDBFb/4rSuPIXeA4X89tVJ4SYXWZlF7l08Qoxsx588EFycnKSqut1LppjXeQqdRjZZeCr3l3kQgghhJilvCcuidlrjqUoykGZDAtQr26UAFMIIYRIAuoKNU1NTVrKHzF7tLe3c/ToUUBZKnKOeAhl+FsRSuvlz9Ud0a7kI4SY42a6WzwZuuSToYwiee3evZv6+notWXkydcHOBWr6JaPRGLNUTLNcDnASZWKPBdiL2zwLCTCFECIACRjFbFJQUIDNZqOnp8dvzk6RWOryktGsu56kbgD/GWVCsfsiOYAEmEKIOJDATIj4CLV8okicOfq+/EOgHRJgCiGSQjIEqslQRiGEmAkSYAohRAASMAohRHQkwBRCxFy0gVksutale14IIRJPAkwhxJzhHXxKMCqEEPEhAaYQIiwSjAkhhAiXBJhCCE20QWSk5wU6PhaB60wGvxJ0CyGEfxJgCpFc6oA/dXu9OVEFibd4BG/e15GgUAghfHwT2D3di8hSkUIklyJgk9vPjBkf/7r2k0wyMt7VfoRIVYODg2zdupWMjAy2bt2a6OKIGMrIyCAjI4ODBw/O1C3/HTH4npEWTCGEJtrgMdLz4h2kzlQwmWzBdiK0trYyOjpKaWkper0+0cWZMTP93CdOnMBkMlFbWysBZoo5dOgQXV1dHD58mE2bNiVNQncJMIWY/d5PdAESQYI3/6xWK06nk/z8fIxGY6KLE5LD4WBgYID8/Pw5FWDO9HOfPHkSo9FIQ0NDzK45ODjI+fPn+eijjwBYtmwZjz76KDqdLqzzm5qauHr1asjjli1bxpNPPumxzeFw0NLSws2bNwHYsGEDq1evjvAJ4mOm6+X5558H4Pjx43R2ds5EgPk74GyAfX8I9yISYAox+x1IdAGSWaoFqk6nE5vNBpAUAaaYOTk5OTG71pkzZ9izZw/Dw8Me27Ozs/nJT37iExD609DQgMlkCnlcXV2dx/WOHDnCgQOe/+wdOHCA6upqXn/99bADuXhIZL2A0jKuBpxx9Nadn2mRMZhCiJSTrONFhYhWOAFLJD766CPWrVvHO++8w/j4OB999BFvvPEGALt27aK9vT3kNb7//e/T0tIS8KewsJDs7Gy+853vaOccPXqUAwcOUFtbi9lsZnx8HLPZTG1tLSaTid27d8f0OSOVqHpJRtKCKYQQQggPGzZs8GgpKygooKCgAFACqcbGxpBdtcG6tNvb27ly5QqHDh3Srgtw8+ZNXn31Vfbu3etxnYaGBqxWKyaTie7u7oR1lyeqXpKRBJhCCDEHqGM3ARYuXMiyZcswGAx+jz116hQANTU1AHR0dHDjxg2AaU9asdvtXL58GYBFixaxevXqoF2eg4ODXLx4Ubv/okWLKCgo8FuGUONTA028mc7zepevqKgoYL26n9Pd3c3o6CigdG1XVFR4HNPR0QHgs32mBAqC7r33XkAZIzkdf/mXf0l2drZPi2SwsZa1tbUcPnxYq7dESFS9JCMJMIUQs14kOTEl+bknu91Oc3MzY2NjHtu7urro7Ozk8ccf9wnw1DGeRUVFPufabDbKy8upqqqKuCyNjY309fV5bLNarWzZssVvUNba2orVamVyctJju9lsZsWKFWzbts1je6jxqYEm3kT7vB0dHXR0dHiUz2az0d3dHaAGAj/TjRs3tADXbrfT1tYGKGP7QgWsM0mddBPN+69qamrSWum8P3uzZSJPpOJdL8lIAkwhhEhRdrud06dPA7B27VqKi4vR6/XY7XYsFgtOp5O3336bp59+2u/5586do6CggNLSUhYvXozFYqGrqwuz2RywFTGQ8+fPA/Dwww9TUVFBf38/H3zwATabjdOnT5OXl+fxpdra2orZbCYzM5OKigqKi4vR6XR0dHRw4cIFent7OXHihE+QOR2RPK/VaqWtrY309HTKy8u1wKi7u9tvAKmeYzabycrK4pFHHsFgMGj1sHDhwpg9R7wMDg7yve99j+zsbJ544omor/Pd7343qla648ePA7By5cqo7x0PM1Uv2dnZUV87ESTAFEKIFNXZ2cnk5CTV1dUeLXoGgwGDwUBDQwNOp5PW1la/LS+5ublaqxrAxo0bGRoaoq+vj4sXL0YUYE5OTvLUU09pQaRer0ev1zMxMUFvby8Wi4WNGzcCyhe21WolPT3d4xxACzaPHTtGb28v/f39MUsDFMnzXrhwAVBarNzrtqqqiry8PE6ePOlzfXWIwpo1a7RWSbUe3BkMBm2WciStl1lZWWEfG4729nY6OzsBpcW7ubmZdevW8bOf/Szq8YFnzpyJqpXu6NGjXLlyhbq6uoS37iWqXtatW6cNxUgGEmAKIWa9SLq6pVtcYbfbGRgYIDc3N2A6o7KyMk6ePBkwJ9/999/vs23FihX09fUxNDQUUXnUFkh/9+jt7eXatWvaNovFwuTkJCUlJX7P0el0FBcX09XVFXGgG0y4zxuqbg0GA52dnQwMDPi9TzhBQiRjL9Uu+bVr14Z9Tjg6Ozs90gUVFhZSUFDA4sWLo77mT3/6U4CIWvqampp49tlnMRqNM7maTUCJqpeCgoKYZwuIJ0lTJIQQKej69esALF26NOAxauvYrVu3/O4PFrh5j+kMZcmSJUHv4T5xQw3m8vPzQ14vlhM+wn1etXUxWN36U1paSnp6Ojabjddee02byDNdv/jFLwBYtWpVTK6nev755xkfH2d8fJyWlhb++q//mrfffptVq1Zx5syZiK/ncDgwmUzU1dWF3dJ38OBBdu3ahdFo5N1330146yUkrl62bNkCKK25yUBaMIUQIgVFEniNjIzEsSThcQ/gIgleE1H2aLsp9Xo927dvp62tDafTycDAABaLhdLS0qgnhzz44INYrVbq6urYvHmzx76mpqawVvbx153vrbKyksrKSh599FEqKyvZs2cPH3/8cURlff3114GpQCkYh8PBt771LaxWK4cOHYppcvFkrZfNmzdTV1fHs88+y9WrV3n55Zcjus9MkwBTCDFryYzw6EUyaSTWY/eikZubq/2+YEH4X03uZV+0aFFMyxTIdCbk6PV6du7cSX9/P++//z59fX2YzWZGR0c9xn+Gy2q1kp2dzY4dO3z2Xb16NeZdqgUFBaxbtw6TyUR7e3tEyxYeP36cwsJCn0DYW3d3N5s2bUKn02E2m2M+szxZ6wXgoYceor6+nq6urukUd0ZIF7kQQqSgZcuWAQQdK2m32wG4++67416e27dv+92udhNnZmZq2/Ly8gD49NNPA15P3efeZXrXXXcBMDExEVEZIqV2zwcaWgChW5D1ej3btm3TWq0uXboUVVmuXbvGunXr2L59O4ODgx773Ltyg/3MhO7ubq5cucKGDRuCHudwONi0aROFhYX86le/ikvaomSsF1DqZteuXdTV1YXVuppoEmAKIUQKMhgMZGZm4nQ6sVqtfo+xWCyAMpEl3np6eoJudy9DcXExAB9++KFP0ARTyc3T09M9ApCMjAwAjwlDKqvVGrPudKPRSHp6On19fVqQ7q61tTXsbn6DwUBWVpZPWiM1x2YoOp2OZ555huHhYVpaWsJ7gBAcDoffelf3/fa3vyU7O9ujlW5wcJAjR44EPE8dJxqqG/jHP/4xw8PD/NM//VPY4y2bmpo4cuRIWMdORyLrBeCdd94BSJolJKWLXAgxa0m3eGC3bt0KGDiqM5sffPBBTCYTra2tOJ1ObVUa9zyYy5cvDzjLPJaGhoZoaGigrKwMg8GglUFNfO5eBr1eT0lJCTabjWPHjlFaWqqt+KPmwRwbG6O8vNwjCDEYDJw7d46RkREaGxtZv349er1eS26enp7uNz9lNO677z4th+fw8DAVFRUMDg5quTMzMzN9gsxf/vKXTExMaKv9qMePjIx4DBGINNG62rUaKBtApD7++GMqKyvZv38/69evp7KyEofDgcVi4bnnnmN4eFhbf1u1b98+jh8/TldXl9/xjc3NzQA88MADQe/99ttva2UINpbRPYjbtWsX1dXVMR2n6U8i6wWUP1zUGevJQAJMIYRIQn19fT6r4qjUYM1oNHL79m0sFgs2m01bsUblbzWceDEajfT09HDy5EmP7r38/Hwee+wxn+PV8YiXLl3CbDZjNpu1fWpyc38TYx555BFOnz7tUz/l5eXaSj6xUFNTo+XwbGtr0wJCtWwOh8MnwJyYmNDeB/c6yM3N5fHHH592mVpbW2MSZN1zzz3odDqPVDyqwsJCXnvttbDGC7qzWq0YjcaQrZLqDP1HH3006HFqF7aaomnr1q0RlScaiawXVVFRUUTXTyQJMIUQIokES93jT0VFBRUVFR7rawdbzxugpKQk4PVycnIoKSkJe0JNQUEBS5cupaCggKqqKm09cAi9bndNTY3fdbsD5dQEpRUzLy9PO2fhwoXaCkagpBbKycmJyfNu27aN/v5+Ll68yMTEhM/a6t73qqmpIT8/P+Sa8NEmWo+VgoICbDabR0JxQGu18+eVV15h7dq1flehcTgcHDp0SBsXHMyhQ4ciKqu6QlSogDQWElkvACaTierq6qjKnghpiS6AEGL6BgYGXMC0Ev0KIZJXRkYG1dXVSTH5I5b27dtHc3OzT+t8Korne3z79m0mJiaYP3/+uZycnKrpXs/lcskkHyGEEEIkJ4vFQm1tbaKLIfyQLnIhhBBCJKXt27dHtOykmDkSYAohhBBJbiYyAcxG8Z45LqInXeRCCCFEkvOeuCRSU7KkKAIJMIUQQoikt3btWkwmE01NTVrqHpEa2tvbOXr0KKAsFZksZBa5EClAZpELMbc5HA4qKysZHh6ek7PJU5m6QpXRaOTdd98NO2dmJOIxi1zGYAohhBBJTs3R2NPTE3aOUpEc1CVAA+XanK2kBVOIFCAtmEIIIaIleTCFEEIIIcSsJwGmEEIIIYSIKQkwhRBCCCFETEmAKYQQQgghYkoCTCGEEEIIEVMSYAohhBBCiJiSAFMIIYQQQsSUBJhCCCGEECKmJMAUQgghhBAxJQGmEEIIIYSIKQkwhRBCCCFETEmAKYQQQgghAL6I1YUkwBQiBaSlpU0AuFyuRBdFCCFEkkpLS/s4VteSAFOIFJCWlvY7gM8//zzRRRFCCJFkvvjiC/W/78XqmhJgCpEa3gcJMIUQQkTG5XJp3x2ff/75v8TquhJgCpECXC7Xf3G5XK6JiQntL1EhhBAilImJCVwuF2lpaR/k5eX971hdVwJMIVLA0qVLLWlpafUA4+PjEmQKIYQIaXJykomJCYDPPvvss62xvLYEmEKkiFu3bn0HcHzxxReMjY0hrZlCCCG8uVwuPvvsM8bHx/njH/8IwLx58/bfc889fbG8T1osLyaESCyHw/HlRYsW/eSLL77Ym5aWJv9/CyGECCgtLW0IeHLp0qUtsbyuy+WSAFOIVHT9+vWH5s+f/7cul2uty+VagvRWCCGEQElrl5aW1g+8+/nnnx/My8sbjfU9JGWeEEIIIYSIKZfLJa0aQgghhBAitv5/TXt0zOnE2o4AAAAASUVORK5CYII=)







