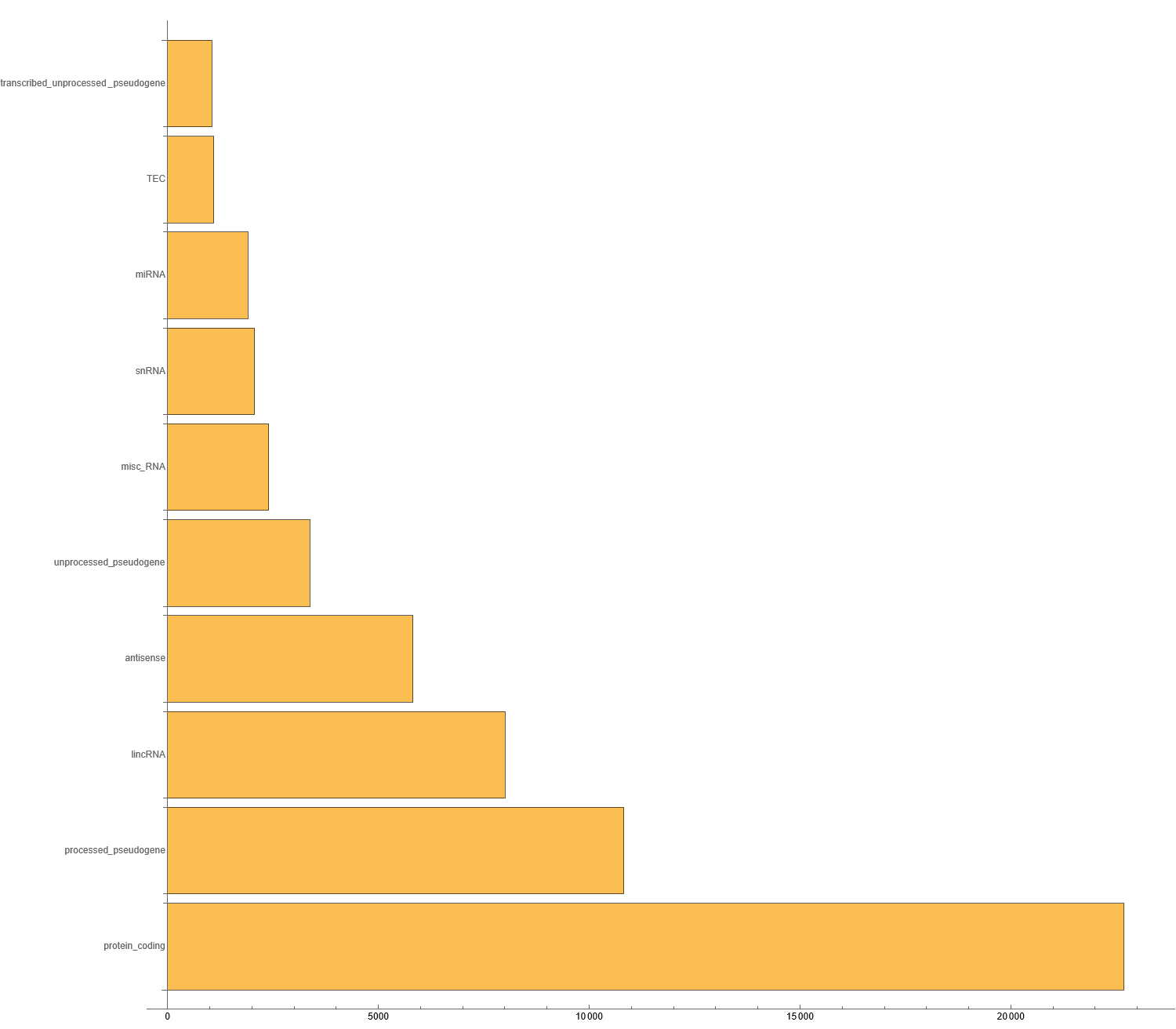
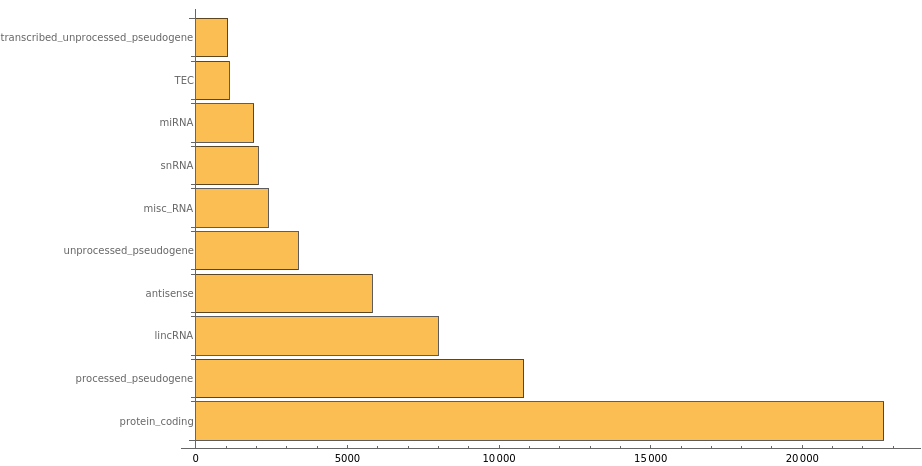
In bioinformatics, there are a number of public SQL endpoints that contain very large datasets. This example shows how easy it is to connect to one and to quickly extract information that would be very difficult to process in memory.
In order to see some data, you have to connect to the public endpoint provided by the ensembl project and extract the schema information for two tables: