International Essays |
ChatGPT reçoit ses « super-pouvoirs Wolfram » !
ChatGPT reçoit ses « super-pouvoirs Wolfram » !
Pour activer la fonctionnalité décrite ici, sélectionnez et installez Wolfram plugin à partir de ChatGPT. Veuillez prendre note que cette fonctionnalité n’est pour l’instant disponible que pour certains utilisateurs de ChatGPT Plus. Si vous souhaitez en savoir plus, veuillez consulter l’annonce d’OpenAI.
En seulement deux mois et demi...
En seulement deux mois et demi...
Début janvier, j’ai mentionné la possibilité de connecter ChatGPT à Wolfram|Alpha. Aujourd’hui, deux mois et demi plus tard, j’ai le plaisir d’annoncer que c’est chose faite ! Grâce au génie logiciel héroïque de notre équipe et de l’OpenAI, ChatGPT peut désormais faire appel à Wolfram|Alpha, ainsi qu’à Wolfram Language, pour lui donner ce que nous pourrions appeler des « super-pouvoirs de calcul ». Tout cela n’en est qu’à ses débuts, mais c’est déjà très impressionnant. On commence à voir la puissance étonnante (et peut-être même révolutionnaire) de ce que nous pouvons appeler « ChatGPT + Wolfram ».
En janvier, j’ai fait remarquer qu’en tant que réseau neuronal LLM, ChatGPT, malgré ses remarquables prouesses dans la génération textuelle de matériel « tel que » ce qu’il a lu sur le Web, etc., ne peut pas lui-même effectuer des calculs non triviaux ou produire systématiquement des données correctes (au lieu de simplement « sembler à peu près correctes »), etc. Mais lorsqu’il est connecté au plugin Wolfram, il peut faire ces choses-là. Voici donc mon premier exemple (très simple) du mois de janvier, réalisé désormais par ChatGPT avec les « super-pouvoirs de Wolfram » installés :
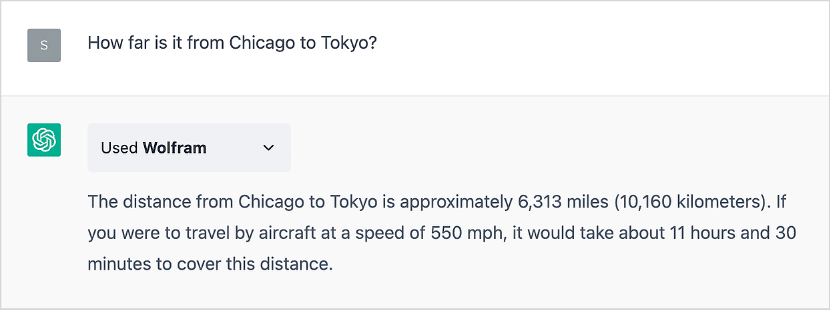
Il s’agit d’un résultat correct (ce qui n’était pas le cas en janvier) trouvé par un calcul réel. Et en prime, une visualisation immédiate :
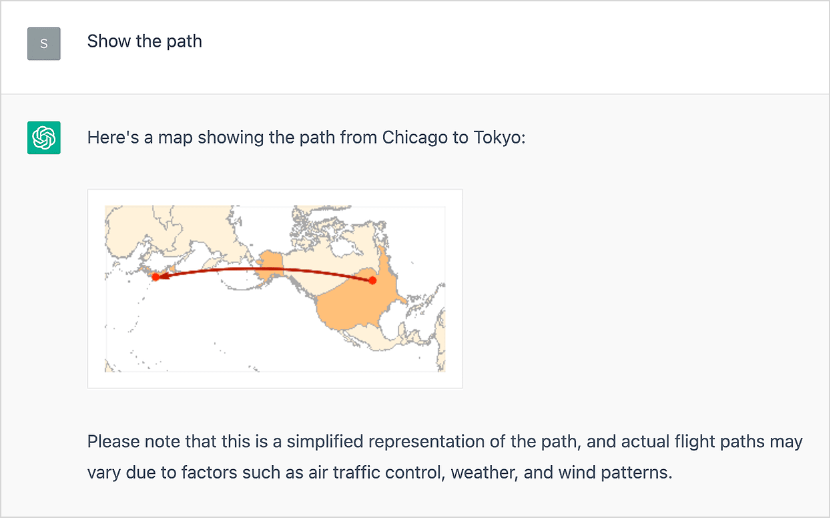
Comment cela fonctionne-t-il ? Le ChatGPT formule une requête à Wolfram|Alpha, l’envoie à Wolfram|Alpha pour qu’il la calcule, puis « décide quoi dire » en fonction des résultats qu’il reçoit. Vous pouvez voir ce va-et-vient en cliquant sur la case « Used Wolfram » (et en voyant cela, vous pouvez vérifier que ChatGPT n’a rien « inventé ») :
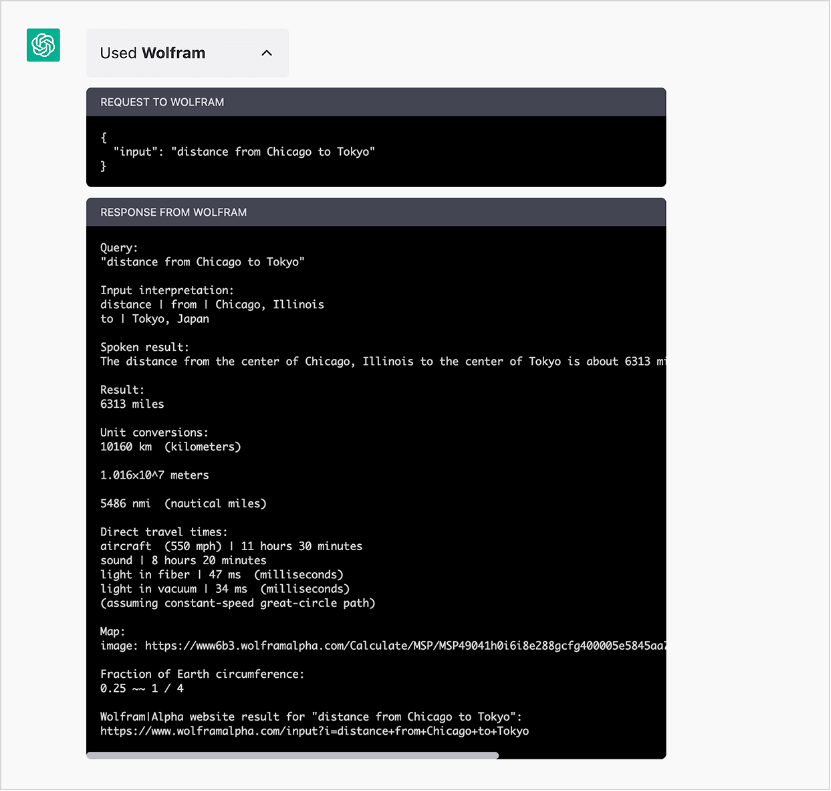
Il y a beaucoup de choses non triviales qui se passent ici, tant du côté de ChatGPT que de Wolfram|Alpha. Mais le résultat est correct et intégré dans un texte agréable et fluide.
Prenons un autre exemple, également tiré de ce que j’ai rédigé en janvier :
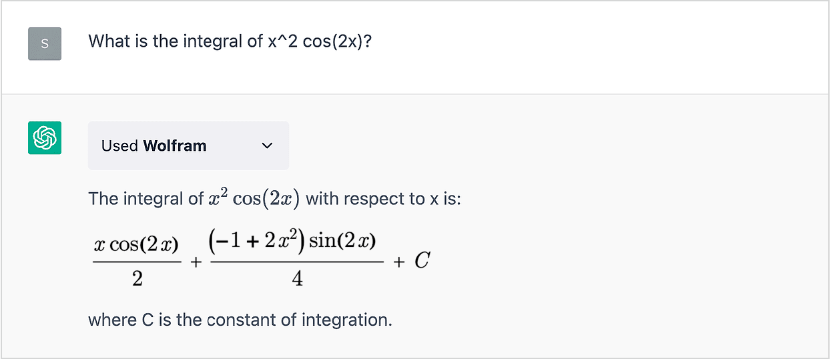
En janvier, j’ai remarqué que ChatGPT finissait par « inventer » des données plausibles (mais erronées) lorsqu’on lui donnait cette consigne :
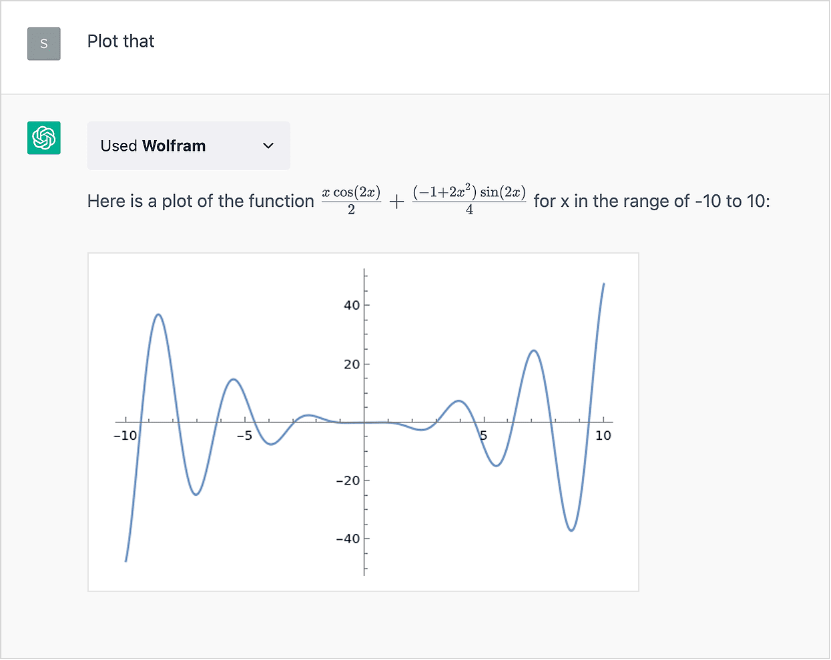
Mais maintenant, il appelle le plugin Wolfram et obtient une bonne réponse qui fait autorité. Et, en prime, nous pouvons aussi faire une visualisation :
Un autre exemple, datant du mois de janvier et qui s’avère maintenant correct, est le suivant :
Si vous essayez ces exemples, ne soyez pas surpris de constater qu’ils fonctionnent différemment (parfois mieux, parfois moins bien) des exemples que je présente ici. Puisque ChatGPT génère ses réponses de manière aléatoire, des choses différentes peuvent se produire même si vous lui posez exactement la même question (même lors d’une nouvelle session). Cela semble « très humain ». Mais c’est différent de l’expérience solide de que l’on obtient dans Wolfram|Alpha et Wolfram Language : une « bonne réponse et ça ne change pas si vous recommencez ».
Voici un exemple où nous avons vu ChatGPT (de manière assez impressionnante) « discuter » avec le plugin Wolfram, après avoir constaté qu’il avait obtenu le « mauvais Mercure » :
Ce qui est particulièrement important ici, c’est que ChatGPT ne nous utilise pas seulement pour effectuer une opération « sans issue » telle que l’affichage du contenu d’une page Web. Nous agissons plutôt comme un véritable « implant cérébral » pour ChatGPT, qui nous demande des choses chaque fois qu’il en a besoin, et nous lui donnons des réponses qu’il peut intégrer dans ce qu’il est en train de faire. C’est assez impressionnant à voir en action. Et, bien qu’il y ait encore beaucoup de travail à faire, ce qui est déjà en place contribue grandement (entre autres) à donner à ChatGPT la capacité de fournir des connaissances et des données précises, ainsi que des calculs corrects et non triviaux.
Mais ce n’est pas tout. Nous avons déjà vu des exemples où nous avons pu fournir des visualisations personnalisées à ChatGPT. Et grâce à nos capacités de calcul, nous sommes régulièrement en mesure de créer des contenus « vraiment originaux » : des calculs qui n’ont tout simplement jamais été réalisés auparavant. De plus, alors que le « ChatGPT pur » est limité à ce qu’il a « appris au cours de son apprentissage », le fait de nous appeler lui permet d’obtenir des données actualisées.
Cela peut se faire sur la base de nos flux de données en temps réel (ici, nous sommes appelés deux fois, une fois pour chaque lieu) :
Cela peut également se faire sur la base de calculs prédictifs de type « scientifique » :
Ou les deux :
Ce que vous pouvez faire
Ce que vous pouvez faire
Et maintenant (presque) tout cela est accessible à ChatGPT, ce qui ouvre de nouvelles possibilités d’une ampleur et d’une profondeur extraordinaires. Pour en donner une idée, voici quelques exemples (simples) :
Un flux de travail moderne humain + d’intelligence artificielle
Un flux de travail moderne humain + d’intelligence artificielle
ChatGPT est conçu pour permettre une conversation avec les humains. Mais que peut-on faire lorsque cette conversation contient des calculs et des connaissances informatiques ? Voici un exemple. Commencez par poser une question qui porte sur la « connaissance du monde » :
Et oui, en « ouvrant la boîte », on peut vérifier que la bonne question nous a été posée et quelle réponse brute nous avons donnée. Nous pouvons continuer et demander une carte :
Il existe des projections cartographiques plus « jolies » que nous aurions pu utiliser. Et grâce aux « connaissances générales » de ChatGPT basées sur sa lecture du Web, etc., nous pouvons simplement lui demander d’en utiliser une :
Nous pouvons aussi choisir une carte thermique. Là encore, nous pouvons simplement lui demander de produire cette carte en utilisant notre technologie :
Modifions à nouveau la projection en lui demandant à nouveau de choisir à l’aide de ses « connaissances générales » :
Et oui, il a obtenu une projection « correcte ». Mais pas le centrage. Demandons-lui alors de corriger cela :
Alors, qu’avons-nous là ? Nous avons quelque chose que nous avons « collaboré » à construire. Nous avons progressivement exprimé ce que nous voulions. L’IA (c’est-à-dire ChatGPT + Wolfram) l’a progressivement construit. Mais qu’avons-nous réellement obtenu ? Il s’agit d’un morceau de code en Wolfram Language pouvant être visualisé en « ouvrant la boîte », ou simplement en le demandant à ChatGPT :
Si on copie le code dans un notebook Wolfram, on peut immédiatement l’exécuter et on constate qu’il comporte une « fonction de luxe » intéressante. Comme l’affirme ChatGPT dans sa description, il y a des infobulles dynamiques qui donnent le nom de chaque pays :
(Et, oui, il est un peu dommage que ce code ne contienne que des nombres explicites, plutôt que la requête symbolique originale sur la production de viande bovine. Cela est dû au fait que ChatGPT a posé la question originale à Wolfram|Alpha, puis a transmis les résultats à Wolfram Language. Mais je considère que le fait que toute cette séquence fonctionne est extrêmement impressionnant).
Fonctionnement et maîtrise de l’IA
Fonctionnement et maîtrise de l’IA
Que se passe-t-il « dans la boîte à outils » de ChatGPT et du plugin Wolfram ? Rappelez-vous que le cœur de ChatGPT est un « grand modèle de langage » (LLM) qui est entraîné à partir du Web pour générer une « suite raisonnable » à partir de n’importe quel texte qui lui est donné. Mais la dernière partie de son entraînement consiste à apprendre à ChatGPT à « converser » et à savoir quand « demander quelque chose à quelqu’un d’autre », ce « quelqu’un » pouvant être un humain, ou même un plugin. On lui a appris quand il devait s’adresser au plugin Wolfram.
Le plugin Wolfram a en fait deux points d’entrée : un par Wolfram|Alpha et un par Wolfram Language. Le point d’entrée Wolfram|Alpha est en quelque sorte le plus « facile » à gérer pour ChatGPT ; le point d’entrée Wolfram Language est en fin de compte le plus puissant. La raison pour laquelle Wolfram|Alpha est plus facile c’est parce qu’il ne prend en entrée que du langage naturel, ce qui est exactement ce que ChatGPT traite de manière routinière. De plus, Wolfram|Alpha est conçu pour être indulgent et, de ce fait, traiter des « entrées de type humain », plus ou moins désordonnées.
Wolfram Language, en revanche, est conçu pour être précis et bien défini, et peut être utilisé pour construire des tours de calcul arbitrairement sophistiquées. À l’intérieur de Wolfram|Alpha, il s’agit de traduire le langage naturel en Wolfram Language précis. En fait, il capture le « langage naturel imprécis » et le « transforme » en Wolfram Language précis.
Lorsque ChatGPT appelle le plugin Wolfram, il se contente souvent d’envoyer du langage naturel à Wolfram|Alpha. Mais à ce stade, ChatGPT a appris à écrire en Wolfram Language. En fin de compte, comme nous le verrons plus loin, il s’agit d’un moyen de communication plus souple et plus puissant. Mais cela ne fonctionne que si le code en Wolfram Language est parfaitement correct. Pour en arriver là, c’est en partie une question d’entraînement. Mais il y a aussi un autre élément : si on lui donne un code, le plugin Wolfram peut l’exécuter, et si les résultats sont manifestement erronés (c.-à.-d. s’ils généraient beaucoup d’erreurs), ChatGPT peut tenter de le corriger et essayer de l’exécuter à nouveau. (Plus précisément, ChatGPT peut essayer de générer des tests à exécuter et modifier le code s’ils échouent).
Il y a encore beaucoup à faire ici, mais on voit déjà ChatGPT faire de multiples allers-retours. Il peut réécrire sa requête Wolfram|Alpha (par exemple en la simplifiant en supprimant les parties non pertinentes), ou il peut décider de passer de Wolfram|Alpha à Wolfram Language, ou il peut réécrire son code Wolfram Language. Il est possible de lui dire comment faire ces choses dans le cadre de « l’invite de commande du plugin » initial.
L’écriture de ce message est une activité étrange, c’est peut-être notre première expérience sérieuse de tentative de « communication avec une intelligence extraterrestre ». Bien sûr, le fait que cette « intelligence extraterrestre » ait été entraînée à partir d’un vaste corpus de textes écrits par des êtres humains est une aide précieuse. Elle connaît donc l’anglais (un peu comme tous ces extraterrestres de science-fiction un peu ringards...). Et nous pouvons lui dire des choses telles que « si l’entrée de l’utilisateur est dans une langue autre que l’anglais, traduisez en anglais et envoyez une requête appropriée à Wolfram|Alpha, puis fournissez votre réponse dans la langue de l’entrée originale ».
Nous avons parfois constaté qu’il fallait insister (regardez les mots en majuscules) : « Lorsque vous écrivez du code en Wolfram Language, n’utilisez JAMAIS le snake case pour les noms de variables ; utilisez TOUJOURS le camel case pour les noms de variables. » Et même avec cette insistance, ChatGPT se trompe parfois. L’ensemble du processus de « génie de l’invite de commande », c’est un peu comme chercher à maîtriser un animal : vous essayez de faire faire à ChatGPT ce que vous voulez, mais il est difficile de savoir exactement ce qu’il faut faire pour y parvenir.
Il est probable qu’un jour, cette question sera traitée dans l’entraînement ou dans l’invite de commande, mais pour l’instant, il arrive que ChatGPT ne sache pas quand le module d’extension Wolfram peut l’aider. Par exemple, ChatGPT devine qu’il s’agit d’une séquence d’ADN, mais (du moins dans cette session) ne pense pas immédiatement que le module Wolfram peut faire quoi que ce soit avec cette séquence :
En revanche, si vous dites « Use Wolfram », le message sera envoyé au module d’extension de Wolfram, qui s’en chargera très bien :
(Vous pouvez aussi parfois dire spécifiquement « Use Wolfram|Alpha » ou « Use Wolfram Language ». Dans le cas de Wolfram Language en particulier, il peut être utile d’examiner le code envoyé et de lui dire, par exemple, de ne pas utiliser les fonctions dont il a inventé les noms, mais qui n’existent pas en réalité).
Lorsque le plugin Wolfram reçoit un code en Wolfram Language, il se contente d’évaluer ce code et de renvoyer le résultat sous la forme d’un graphique, d’une formule mathématique ou d’un simple texte. Mais lorsqu’il reçoit une entrée Wolfram|Alpha, celle-ci est envoyée à un terminal spécial de l’API Wolfram|Alpha « pour les LLM », et le résultat revient sous forme de texte destiné à être « lu » par ChatGPT, et effectivement utilisé comme une invite de commande supplémentaire pour le texte que ChatGPT est en train d’écrire. Jetez un coup d’œil à cet exemple :
Le résultat est un joli texte contenant la réponse à la question posée, ainsi que d’autres informations que ChatGPT a décidé d’inclure. Mais « à l’intérieur », nous pouvons voir ce que le plugin Wolfram (et le terminal « LLM » de Wolfram|Alpha) a réellement fait :
On y trouve un grand nombre d’informations supplémentaires (y compris de belles photos !). Mais ChatGPT a « décidé » de ne retenir que quelques éléments pour les inclure dans sa réponse.
D’ailleurs, si vous voulez être sûr d’obtenir ce que vous pensez obtenir, vérifiez toujours ce que ChatGPT a envoyé au plugin Wolfram et ce que le plugin a renvoyé. L’une des choses importantes que nous ajoutons au plugin Wolfram est un moyen de « factifier » la sortie de ChatGPT et de savoir quand ChatGPT « utilise son imagination », et quand il fournit des faits solides.
Parfois, pour essayer de comprendre ce qui se passe, il est également utile de prendre ce que le plugin Wolfram a envoyé et de le saisir directement sur le site Web de Wolfram|Alpha ou dans un système de Wolfram Language (tel que Wolfram Cloud).
Wolfram Language en tant que langage de collaboration entre l’homme et l’intelligence artificielle
Wolfram Language en tant que langage de collaboration entre l’homme et l’intelligence artificielle
L’une des grandes qualités (et, franchement, inattendues) de ChatGPT est sa capacité à partir d’une description brute et à générer à partir de celle-ci un produit fini et soigné, tel qu’un article, une lettre, un document juridique, etc. Dans le passé, on aurait pu essayer d’y parvenir « à la main » en commençant par des éléments « passe-partout », puis en les modifiant, en les « collant » ensemble, etc. Mais ChatGPT a pratiquement rendu ce processus obsolète. En effet, il a « absorbé » un grand nombre de modèles de documents à partir de ce qu’il a « lu » sur le Web, etc. et maintenant il fait généralement un bon travail en les « adaptant » de manière transparente à ce dont vous avez besoin.
Qu’en est-il du code ? Dans les langages de programmation traditionnels, l’écriture du code a tendance à impliquer beaucoup de « travail de fond » et, dans la pratique, de nombreux programmeurs dans ces langages passent beaucoup de temps à créer leurs programmes en copiant de gros morceaux de code sur le Web. Mais aujourd’hui, il semble que ChatGPT puisse rendre tout cela obsolète. En effet, il est capable de créer automatiquement n’importe quel type de code standard avec juste un peu de « contribution humaine ».
Bien sûr, il doit y avoir une certaine contribution humaine, car sinon ChatGPT ne saurait pas quel programme il est censé écrire. Mais on peut se demander pourquoi il doit y avoir un « modèle » dans le code ? Ne devrait-on pas pouvoir disposer d’un langage où, au niveau du langage lui-même, tout ce qui est nécessaire est une petite quantité de données humaines, sans aucun « modèle » ?
Voici le problème. Les langages de programmation traditionnels sont centrés sur l’idée selon laquelle il faut dire à l’ordinateur ce qu’il doit faire, et ce, dans ses propres termes : définir telle variable, tester telle condition, etc. Mais ce n’est pas forcément le cas. Au lieu de cela, on peut prendre le problème par l’autre bout : prendre des choses auxquelles les gens pensent naturellement, puis essayer de les représenter par le calcul et automatiser efficacement le processus de leur mise en œuvre sur un ordinateur.
C’est ce sur quoi j’ai travaillé pendant plus de quarante ans. C’est grâce au fondement de ce qu’on appelle aujourd’hui Wolfram Language que je me sens maintenant en droit de qualifier de « langage computationnel à part entière ». Qu’est-ce que cela signifie ? Cela signifie que le langage contient une représentation computationnelle des choses abstraites et réelles dont on parle dans le monde, qu’il s’agisse de graphes, d’images, d’équations différentielles, de villes, de produits chimiques, d’entreprises ou de films.
Pourquoi ne pas commencer par le langage naturel ? Cela fonctionne jusqu’à un certain point, comme le montre le succès de Wolfram|Alpha. Mais dès que l’on essaie de spécifier quelque chose de plus élaboré, le langage naturel devient (comme le « jargon juridique ») peu maniable et l’on a vraiment besoin d’un moyen plus structuré pour s’exprimer.
Les mathématiques en sont un bon exemple historique. Il y a 500 ans, la seule façon d’« exprimer les mathématiques » était le langage naturel. Puis la notation mathématique a été inventée, et les mathématiques ont pris leur essor avec le développement de l’algèbre, du calcul infinitésimal et, finalement, de toutes les sciences mathématiques.
Mon objectif principal avec Wolfram Language est de créer un langage computationnel capable de faire la même chose pour tout ce qui peut être « exprimé de manière computationnelle ». Pour y parvenir, nous avons dû construire un langage qui fait automatiquement beaucoup de choses et qui connaît intrinsèquement beaucoup de choses. Mais le résultat est un langage qui est mis en place pour que les gens puissent commodément « s’exprimer par le calcul », tout comme la notation mathématique traditionnelle leur permet de « s’exprimer mathématiquement ». Un point essentiel est que, contrairement aux langages de programmation traditionnels, Wolfram Language est destiné à être lu non seulement par les ordinateurs, mais aussi par les humains. En d’autres termes, il s’agit d’un moyen structuré de « communiquer des idées de calcul », non seulement aux ordinateurs, mais aussi aux humains.
Aujourd’hui, avec ChatGPT, cela devient soudain encore plus important qu’auparavant. En effet, comme nous l’avons vu plus haut, ChatGPT peut travailler avec Wolfram Language et, en quelque sorte, élaborer des idées computationnelles en utilisant simplement le langage naturel. Ce qui est essentiel, c’est que Wolfram Language peut représenter directement le genre de choses dont nous voulons parler. Mais ce qui est également important, c’est qu’il nous permet de « savoir ce que nous avons », car nous pouvons lire de manière réaliste et économique le code en Wolfram Language généré par ChatGPT.
L’ensemble commence à fonctionner très bien avec le plugin Wolfram dans ChatGPT. Voici un exemple simple, où ChatGPT peut facilement générer une version en Wolfram Language de ce qui lui est demandé :
Le point essentiel est que le « code » est quelque chose que l’on peut raisonnablement s’attendre à lire (si je l’écrivais, j’utiliserais la fonction RomanNumeral, légèrement plus compacte) :
Voici un autre exemple :
J’aurais peut-être écrit le code un peu différemment, mais il s’agit là encore de quelque chose de très lisible :
Il est souvent possible d’utiliser un pidgin en Wolfram Language et en anglais pour dire ce que l’on veut :
Voici un exemple où ChatGPT réussit à nouveau à créer Wolfram Language et à nous le montrer pour que nous puissions confirmer que, effectivement, il calcule bien ce qu’il faut :
D’ailleurs, pour que cela fonctionne, il est essentiel que Wolfram Language soit en quelque sorte « autonome ». Ce morceau de code est juste un code générique standard en Wolfram Language ; il ne dépend pas d’un élément extérieur, et si vous le voulez, vous pouvez chercher les définitions de tout ce qui apparaît dans ce code dans la documentation de Wolfram Language.
Bon, un autre exemple :
Manifestement, ChatGPT a eu des problèmes ici. Mais, comme il l’a suggéré, on peut simplement exécuter le code qu’il a généré, directement dans un notebook. Et comme Wolfram Language est symbolique, on peut voir explicitement les résultats à chaque étape :
Si près du but ! Aidons-le un peu en lui disant que nous avons besoin d’une véritable liste de pays européens :
Et voilà le résultat ! Ou du moins, un résultat. En effet, lorsque nous examinons ce calcul, il se peut qu’il ne corresponde pas tout à fait à ce que nous souhaitons. Par exemple, nous pourrions aussi sélectionner plusieurs couleurs dominantes par pays et voir si l’une d’entre elles est proche du violet. Mais l’ensemble de la configuration de Wolfram Language nous permet de « collaborer avec l’IA » pour déterminer ce que nous voulons et ce qu’il faut faire.
Jusqu’à présent, nous avons essentiellement commencé par le langage naturel et construit le code en Wolfram Language. Mais nous pouvons aussi commencer par du pseudo-code ou du code dans un langage de programmation de bas niveau. ChatGPT a tendance à faire un travail remarquable en prenant de tels éléments et en produisant du code en Wolfram Language bien écrit à partir d’eux. Le code n’est pas toujours exactement correct. Mais on peut toujours l’exécuter (par exemple avec le plugin Wolfram) et voir ce qu’il fait, potentiellement (grâce au caractère symbolique de Wolfram Language) ligne par ligne. Le langage computationnel de haut niveau de Wolfram Language permet au code d’être suffisamment clair et (au moins localement) simple pour que (en particulier après l’avoir vu fonctionner) on puisse facilement comprendre ce qu’il fait, puis éventuellement itérer avec l’IA.
Lorsque ce que l’on essaie de faire est suffisamment simple, il est souvent réaliste de le spécifier (du moins si on le fait par étapes) purement en langage naturel en utilisant Wolfram Language « juste » comme un moyen de voir ce que l’on a et d’être capable de l’exécuter. Mais c’est lorsque les choses deviennent plus compliquées que Wolfram Language prend tout son sens, en fournissant ce qui est fondamentalement la seule représentation viable, compréhensible par l’homme et pourtant précise de ce que l’on veut.
Lorsque j’ai écrit mon livre An Elementary Introduction to the Wolfram Language, c’est devenu particulièrement évident. Au début du livre, j’ai pu facilement faire des exercices dans lesquels je décrivais ce que je voulais en anglais. Mais au fur et à mesure que les choses se compliquaient, cela devenait de plus en plus difficile. Comme j’ai l’habitude d’utiliser Wolfram Language, je savais en général immédiatement comment exprimer ce que je voulais en Wolfram Language. Mais pour le décrire purement en anglais, il fallait quelque chose de plus en plus complexe et compliqué, qui ressemblait à du jargon juridique.
Vous spécifiez quelque chose en utilisant Wolfram Language. L’une des choses remarquables, que ChatGPT est souvent capable de faire, est de remanier votre code Wolfram Language pour qu’il soit plus facile à lire. Il n’y parvient pas (encore) systématiquement. Mais il est intéressant de voir qu’il fait des compromis différents de ceux qu’aurait fait un rédacteur humain utilisant le code en Wolfram Language. Par exemple, les humains ont des difficultés à trouver de bons noms pour les choses. Il est donc préférable (ou moins déroutant) d’éviter les noms en ayant des séquences de fonctions imbriquées. Mais ChatGPT, grâce à sa maîtrise du langage et de la signification, trouve assez facilement des noms raisonnables. Et bien que je ne m’y attende pas, je pense que l’utilisation de ces noms et la « répartition de l’action » peuvent souvent rendre le code Wolfram Language encore plus facile à lire qu’il ne l’était auparavant, et qu’il se lit en fait comme un analogue formalisé du langage naturel, que nous pouvons comprendre aussi facilement que le langage naturel, mais qui a une signification précise, et qui peut être exécuté pour générer des résultats de calcul.
Résolution de problèmes
Résolution de problèmes
Si vous « savez quel calcul vous voulez faire » et que vous pouvez le décrire en un bref morceau de langage naturel, Wolfram|Alpha est conçu pour effectuer directement le calcul et présenter les résultats d’une manière aussi « visuellement absorbable » que possible. Mais qu’en est-il si vous souhaitez décrire le résultat dans un article narratif et textuel ? Wolfram|Alpha n’a jamais été conçu pour cela. Mais ChatGPT l’est.
Voici un résultat avec Wolfram|Alpha :
Et ici, dans ChatGPT, nous demandons le même résultat qu’avec Wolfram|Alpha, mais nous demandons à ChatGPT d’« en faire un article » :
Les problèmes mathématiques constituent une autre « vieille histoire » pour Wolfram|Alpha. Si un problème mathématique est présenté de manière claire, Wolfram|Alpha le résoudra probablement très bien. Mais qu’en est-il d’un problème de raisonnements « complexe » ? ChatGPT est très doué pour « démêler » ce genre de problèmes et les transformer en « questions mathématiques claires » que le module Wolfram|Alpha peut alors résoudre. Voici un exemple :
Voici un cas un peu plus compliqué, avec une belle utilisation du « bon sens » pour reconnaître que le nombre de dindes ne peut pas être négatif :
Au-delà des problèmes de raisonnements mathématiques, une autre « vieille histoire » abordée par ChatGPT + Wolfram est ce que les physiciens ont tendance à appeler les « problèmes de Fermi » : des estimations d’ordre de grandeur qui peuvent être faites sur la base de connaissances quantitatives sur le monde. En voici un exemple :
Comment participer
Comment participer
ChatGPT + Wolfram est quelque chose de très nouveau, un type de technologie tout à fait nouveau. Et comme à chaque fois qu’un nouveau type de technologie arrive, il ouvre d’immenses possibilités. Certaines d’entre elles sont déjà visibles, mais beaucoup d’autres apparaîtront au cours des semaines, des mois et des années à venir.
Alors, comment participer à ce qui promet d’être une période de rapide croissance technologique et conceptuelle passionnante ? La première chose à faire est d’explorer ChatGPT + Wolfram. ChatGPT et Wolfram constituent chacun un vaste système ; il faudra des années pour les combiner. Mais la première étape consiste à se faire une idée de ce qui est possible.
Trouvez des exemples. Partagez-les. Essayez d’identifier des modèles d’utilisation réussis. Et surtout, essayez de trouver les flux de travail qui apportent la plus grande valeur ajoutée. Ces flux peuvent être très élaborés. Mais il peut aussi s’agir de cas très simples où, une fois que l’on voit ce qu’il est possible de faire, le déclic se produit immédiatement.
Comment mettre en œuvre au mieux un flux de travail ? Nous essayons de trouver les meilleurs flux de travail pour cela. Au sein de Wolfram Language, nous mettons en place des moyens flexibles pour faire appel à des choses comme ChatGPT, à la fois de manière purement programmatique, et dans le contexte de l’interface du notebook.
Mais qu’en est-il du côté de ChatGPT ? Wolfram Language a une architecture très ouverte, où un utilisateur peut ajouter ou modifier à peu près tout ce qu’il veut. Mais comment utiliser cette architecture à partir de ChatGPT ? Une solution consiste à demander à ChatGPT d’inclure un morceau spécifique de code « initial » en Wolfram Language (peut-être avec de la documentation), puis d’utiliser quelque chose comme le pidgin ci-dessus pour parler à ChatGPT des fonctions ou d’autres choses que vous avez définies dans ce code initial.
Nous prévoyons de mettre au point des outils de plus en plus rationalisés pour la manipulation et le partage du code Wolfram Language dans le cadre de ChatGPT. Mais une approche qui fonctionne déjà consiste à envoyer des fonctions à publier dans Wolfram Function Repository, puis, une fois qu’elles sont publiées, à faire référence à ces fonctions dans vos conversations avec ChatGPT.
D’accord, mais qu’en est-il du ChatGPT lui-même ? Quel type de technique d’invite de commande devriez-vous faire pour interagir au mieux avec le plugin Wolfram ? Nous ne le savons pas encore. C’est quelque chose qui doit être exploré, un peu comme un exercice d’éducation à l’IA ou de psychologie de l’IA. Une approche typique consiste à donner quelques « pré-invites de commande » au début de votre session ChatGPT, puis d’espérer qu’elle y prête encore attention plus tard. (Et, oui, elle a une « capacité d’attention » limitée, donc parfois il faut répéter les choses).
Nous avons essayé de fournir un message général pour indiquer à ChatGPT comment utiliser le plugin Wolfram et nous nous attendons à ce que ce message évolue rapidement, au fur et à mesure que nous en apprenons davantage et que le ChatGPT LLM est mis à jour. Mais vous pouvez ajouter vos propres préceptes généraux, tels que « lorsque vous utilisez Wolfram, essayez toujours d’inclure une image » ou « utilisez les unités SI » ou « évitez d’utiliser des nombres complexes si possible ».
Vous pouvez également essayer de mettre en place un pré-message qui « définit une fonction » directement dans ChatGPT, quelque chose comme : « si je vous donne une entrée consistant en un nombre, vous devez utiliser Wolfram pour dessiner un polygone avec ce nombre de côtés. » Ou, plus directement : « si je vous donne une entrée composée de nombres, vous devez appliquer la fonction Wolfram suivante à cette entrée... », puis donner un code explicite en Wolfram Language.
Mais nous n’en sommes qu’au début, et il ne fait aucun doute que d’autres mécanismes puissants seront découverts pour « programmer » ChatGPT + Wolfram. Je pense que nous pouvons nous attendre avec certitude à ce que la période à venir soit une période passionnante et de croissance élevée, où le travail sera très utile à ceux qui choisiront de s’impliquer dans le projet.
Contexte et perspectives
Contexte et perspectives
Il y a une semaine encore, on ne savait pas exactement à quoi ressemblerait ChatGPT + Wolfram, ni dans quelle mesure cela fonctionnerait. Mais ces choses qui évoluent si rapidement aujourd’hui sont le fruit de décennies de développement. D’une certaine manière, l’arrivée de ChatGPT + Wolfram marie enfin les deux principales approches de l’IA qui ont longtemps été considérées comme disjointes et incompatibles.
ChatGPT est en fait un très grand réseau neuronal, entraîné à suivre les modèles « statistiques » de texte qu’il a vus sur le Web, etc. Le concept des réseaux neuronaux, sous une forme étonnamment proche de celle utilisée dans ChatGPT, a vu le jour dans les années 1940. Mais après un certain enthousiasme dans les années 1950, l’intérêt est retombé. Il y a eu une résurgence au début des années 1980 (c’est d’ailleurs à cette époque que je me suis penché pour la première fois sur les réseaux neuronaux). Mais ce n’est qu’en 2012 que nous avons commencé à nous intéresser sérieusement aux possibilités offertes par les réseaux neuronaux. Et maintenant, dix ans plus tard, dans un développement dont le succès a été une grande surprise même pour les personnes impliquées, nous avons ChatGPT.
La tradition « symbolique » de l’IA est plutôt distincte de la tradition « statistique » des réseaux neuronaux. D’une certaine manière, cette tradition est née de l’extension du processus de formalisation développé pour les mathématiques (et la logique mathématique), en particulier vers le début du vingtième siècle. Mais ce qui était critique dans cette tradition, c’est qu’elle s’alignait bien, non seulement, sur les concepts abstraits de l’informatique, mais aussi sur les ordinateurs numériques réels du type de ceux qui ont commencé à apparaître dans les années 1950.
Pendant longtemps, les succès de ce que l’on pourrait réellement considérer comme de l’« IA » ont été au mieux ponctuels. Pendant ce temps, le concept général de calcul connaissait un succès énorme et croissant. Mais comment le « calcul » peut-il être lié à la façon dont les gens pensent les choses ? Pour moi, un développement crucial a été l’idée que j’ai eue au début des années 1980 (en m’appuyant sur un formalisme antérieur issu de la logique mathématique) selon laquelle les règles de transformation des expressions symboliques pourraient être un bon moyen de représenter les calculs à ce qui équivaut à un niveau « humain ».
À l’époque, je me concentrais principalement sur le calcul mathématique et technique, mais j’ai rapidement commencé à me demander si des idées similaires pouvaient s’appliquer à l’« IA générale ». Je soupçonnais que quelque chose comme les réseaux neuronaux pourrait avoir un rôle à jouer, mais à l’époque, je n’avais qu’une petite idée de ce qui serait nécessaire et non de la manière d’y parvenir. Entre-temps, l’idée centrale des règles de transformation des expressions symboliques est devenue le fondement de ce qui est aujourd’hui Wolfram Language et a rendu possible le processus de développement du langage computationnel à grande échelle que nous connaissons aujourd’hui et qui s’est étalé sur plusieurs décennies.
Depuis les années 1960, les chercheurs en intelligence artificielle s’efforcent de développer des systèmes capables de « comprendre le langage naturel », de « représenter la connaissance » et de répondre à des questions à partir de ce langage. Certains de ces travaux ont débouché sur des applications moins ambitieuses mais pratiques. En général, le succès n’était pas au rendez-vous. Entre-temps, à la suite de ce qui s’apparentait à une conclusion philosophique de la science fondamentale que j’avais effectuée dans les années 1990, j’ai décidé, vers 2005, de tenter la construction d’un « moteur de connaissance computationnel » général qui pourrait largement répondre aux questions factuelles et computationnelles posées en langage naturel. La construction d’un tel système n’était pas évidente mais nous avons découvert qu’avec notre langage computationnel sous-jacent et beaucoup de travail, c’était possible. En 2009, nous avons pu lancer Wolfram|Alpha.
D’une certaine manière, ce qui a rendu Wolfram|Alpha possible, c’est qu’il disposait en interne d’un moyen clair et formel de représenter les choses dans le monde et d’effectuer des calculs à leur sujet. Pour nous, « comprendre le langage naturel » n’était pas quelque chose d’abstrait ; c’était le processus concret de traduction du langage naturel en langage computationnel structuré.
Une autre partie consistait à rassembler toutes les données, méthodes, modèles et algorithmes nécessaires pour « connaître » et « calculer » le monde. Bien que nous ayons largement automatisé ces tâches, nous avons toujours constaté que pour que les choses se passent bien, il n’y a pas d’autre choix que de faire appel à des experts humains. Bien que le système de compréhension du langage naturel de Wolfram|Alpha contienne un peu de ce que l’on pourrait considérer comme de l’« IA statistique », la grande majorité de Wolfram|Alpha et de Wolfram Language fonctionnent d’une manière dure et symbolique qui rappelle au moins la tradition de l’IA symbolique. (Cela ne veut pas dire que les fonctions individuelles de Wolfram Language ne font pas appel à l’apprentissage automatique et aux techniques statistiques ; ces dernières années, elles sont de plus en plus nombreuses à le faire, et Wolfram Language dispose également d’un cadre intégré pour l’apprentissage automatique.)
Comme je l’ai indiqué ailleurs, il semble que l’« IA statistique », et en particulier les réseaux neuronaux, soient bien adaptés aux tâches que nous, les humains, « faisons rapidement », y compris, comme nous l’apprend ChatGPT, le langage naturel et la « pensée » qui le sous-tend. Mais l’approche symbolique et, dans un sens, « plus rigidement computationnelle » est ce qui est nécessaire lorsque l’on construit des « tours » conceptuelles ou computationnelles plus importantes, ce qui est le cas en mathématiques, en sciences exactes et, désormais, dans tous les domaines de l’« X computationnel ».
Et maintenant, ChatGPT + Wolfram peuvent être considérés comme le premier système d’« IA » statistique et symbolique à grande échelle. Dans Wolfram|Alpha (qui est devenu un élément central d’outils tels que l’assistant intelligent Siri), il y avait pour la première fois une large compréhension du langage naturel avec une « compréhension » directement liée à une représentation et à un calcul computationnels réels. Et maintenant, 13 ans plus tard, nous avons vu dans ChatGPT que la technologie pure des réseaux neuronaux « statistiques », lorsqu’elle est entraînée à partir de la quasi-totalité du Web, etc. peut remarquablement bien générer « statistiquement » un « langage significatif » de type humain. Et dans ChatGPT + Wolfram, nous sommes maintenant en mesure de tirer parti de l’ensemble du système : du pur « réseau neuronal statistique » de ChatGPT, en passant par la compréhension du langage naturel « ancrée dans le calcul » de Wolfram|Alpha, jusqu’à l’ensemble du langage computationnel et des connaissances computationnelles de Wolfram Language.
Lorsque nous avons commencé à construire Wolfram|Alpha, nous pensions que pour obtenir des résultats utiles, nous n’aurions peut-être pas d’autre choix que d’engager une conversation avec l’utilisateur. Mais nous avons découvert que si nous générions immédiatement des résultats riches, « visuellement scannables », nous n’avions besoin que d’une simple interaction d’« hypothèses » ou de « paramètres », du moins pour le type d’information et de recherche de calcul que nous attendions de la part de nos utilisateurs. (Dans Wolfram|Alpha Notebook Edition nous disposons néanmoins d’un exemple puissant de la manière dont le calcul en plusieurs étapes peut être effectué en langage naturel).
En 2010, nous avions déjà fait des expériences pour générer non seulement le code en Wolfram Language des requêtes Wolfram|Alpha typiques à partir du langage naturel, mais aussi des « programmes entiers ». À l’époque, cependant, sans la technologie LLM moderne, nous n’étions pas allés très loin. Mais nous avons découvert que, dans le contexte de la structure symbolique de Wolfram Language, même de petits fragments de ce qui équivaut à du code généré par le langage naturel étaient extrêmement utiles. En effet, j’utilise le mécanisme « += » dans les notebooks Wolfram un nombre incalculable de fois presque tous les jours, par exemple pour construire des entités ou des quantités symboliques à partir du langage naturel. Nous ne savons pas encore exactement ce que sera la version moderne de ce mécanisme, mais il est probable qu’elle impliquera la riche « collaboration » entre l’homme et l’intelligence artificielle dont nous avons parlé plus haut et que nous pouvons commencer à voir à l’œuvre pour la première fois dans ChatGPT + Wolfram.
Je considère ce qui se passe actuellement comme un moment historique. Pendant plus d’un demi-siècle, les approches statistiques et symboliques de ce que nous pourrions appeler l’« IA » ont évolué tout en étant largement séparée. Mais aujourd’hui, dans ChatGPT + Wolfram, elles sont réunies. Et bien que nous n’en soyons qu’au début, je pense que nous pouvons raisonnablement nous attendre à une puissance énorme dans la combinaison et, dans un sens, à un nouveau paradigme pour le « calcul semblable à l’IA », rendu possible par l’arrivée de ChatGPT, et maintenant par sa combinaison avec Wolfram|Alpha et Wolfram Language dans ChatGPT + Wolfram.
© 2023 Wolfram. Tous droits réservés.