International Essays |
Uso de IA para análisis temático: Análisis de informes forenses mediante LLM
Uso de IA para análisis temático: Análisis de informes forenses mediante LLM
21 de enero de 2025
Harrison Boon, Ex pasante y autor invitado y Ned Pratt, Ex pasante y autor invitado
Este cuaderno es una traducción al español del artículo de la Comunidad Wolfram “Using AI for Thematic Analysis: Analyzing Coroner Reports with LLMs” producido con ayuda de un LLM y verificado por un traductor profesional
En el Reino Unido, los formularios de Prevención de Futuras Muertes (PFD, por sus siglas en inglés) desempeñan un papel crucial en la garantía de la seguridad pública. Este es un tipo especial de informe forense que documenta más que solo las circunstancias de la muerte de una persona. Los PFD se emiten cuando un forense investiga una muerte y determina que un riesgo específico o una falla sistémica, considerados prevenibles, han desempeñado un papel significativo en dicha muerte.
Si bien estos formularios tienen una estructura en la medida en que cada uno posee secciones que deben ser completadas por los forenses, estas secciones son llenadas por los forenses en lenguaje natural, lo que hace que el análisis de estos formularios (hasta ahora) sea muy laborioso, ya que cada informe tiene que ser leído por una persona.
Wolfram Language cuenta con una extensa lista de funciones integradas que permite realizar llamadas a varios modelos de lenguaje de gran tamaño (LLM) desde dentro del kernel de Wolfram. Implementar LLM en Wolfram significa que la extracción de datos no estructurados, como el contenido de un informe forense, se lleva a cabo en una fracción del tiempo. Luego podemos utilizar las herramientas de análisis de datos de Wolfram para procesar lo que hemos recopilado.
Recopilación de los datos
Recopilación de los datos
El Poder Judicial de los Tribunales y Cortes del Reino Unido publica una muestra de estos PFD en su página web. Desafortunadamente, no disponen de una API pública para acceder a estos archivos, lo que significa que la única manera de ver los archivos es visitando la página y buscando cada archivo. Esto tomaría mucho tiempo si se hiciera manualmente, así que necesitaremos crear un rastreador web para recorrer y descargar automáticamente los PFD:
Nota: todos los datos se han obtenido de Courts and Tribunal Judiciary Prevention of Future Death Reports bajo Open Government Licence v3 .0.
In[]:=
(* To keep things simple, I'm only collecting pfd reports of a certain type *) pfdReportTypes= "hospital-death-clinical-procedures-and-medical-management-related-deaths", "alcohol-drug-and-medication-related-deaths", "care-home-health-related-deaths", "community-health-care-and-emergency-services-related-deaths", "emergency-services-related-deaths-2019-onwards", "mental-health-related-deaths";getPFDList[start_, end_] := Block[{htmlDocs, individualPageLinks, individualPages}, htmlDocs = Table[Import[URLBuild[<| "Scheme" -> "https", "Domain" -> "www.judiciary.uk", "Path" -> {"page", ToString[i]}, (* Iterate through the pages *) "Query" -> "pfd_report_type" -> #, (* Cycle throught just the report types we want *) "post_type" -> "pfd", "order" -> "desc" , "Fragment" -> None |>], "Text"]& /@ pfdReportTypes, {i, start, end}]; (* Now that we've got a list of the results pages, we need to grab each individual report's page *) individualPageLinks = Flatten[StringCases[#, "<a class=\"card__link\" href=\"" ~~ Shortest[url___] ~~ "\"" :> url]& /@ htmlDocs]; individualPageLinks = DeleteDuplicates[individualPageLinks]; (* The searches may have had overlapping results, which should be removed *) (* Each of these pages contains a link to a PDF file with the reports we want *) individualPages = Import[#, "Text"]& /@ individualPageLinks; First[StringCases[#, "related-content__link\" href=\"" ~~ Shortest[url___] ~~ "\"" :> url] ]& /@ individualPages ]
Probemos si este código funciona obteniendo las dos primeras páginas de enlaces:
In[]:=
getPFDList[1,2]//Short
Out[]//Short=
{https://www.judiciary.uk/wp-content/uploads/2024/08/Beverley-Stanisauskis-Prevention-of-Future-Deaths-Report-2024-0466.pdf,114,https://www.judiciary.uk/wp-content…aths-report-2024-0087_Published.pdf}
¡Genial! Ahora usémoslo para extraer de más páginas:
In[]:=
pfdLinks=getPFDList[1,2];
In[]:=
pfdLinks=getPFDList[1,60];
In[]:=
pfdLinks//Short
Out[]//Short=
{https://www.judiciary.uk/wp-content/uploads/2024/10/Kingsley-Imafidon-Prevention-of-Future-Deaths-Report-2024-0554.pdf,2216,https://www.judici…-0195-Redacted.pdf}
In[]:=
pfdLinks>>pfdtexts
In[]:=
Export["links.txt",<<pfdtexts]
Out[]=
links.txt
In[]:=
SystemOpen["links.txt"]
Ahora importemos todos para obtener el texto del documento:
In[]:=
pdfs=Import[#,"Plaintext"]&/@pfdLinks
In[]:=
pdfsWithLinks=<|"Link"->#1,"Text"->#2|>&@@@Thread[{#1,#2}&[pfdLinks,pdfs]];pdfsWithLinks=Select[pdfsWithLinks,StringLength[#Text]>150&];(*Filteroutanyemptyorincompletereports*)pdfsWithLinks//Dataset
Extracción de datos
Extracción de datos
Con los datos ya recopilados, una aplicación interesante es revisar la duración de estas investigaciones representada a lo largo del tiempo. La forma tradicional de hacer esto sería que alguien lea todos estos informes e ingrese manualmente las fechas de inicio y fin de una investigación en una hoja de cálculo. Esto suena muy laborioso (y aburrido). Los LLM pueden ser sumamente útiles aquí, ya que poseen suficiente conocimiento para poder leer el informe y extraer solo las dos fechas, sin tardar ni cerca de lo que tardaría una persona.
Una desventaja de utilizar los LLM es que a menudo se requiere mucho trabajo de redacción de indicaciones para restringir su comportamiento. Con indicaciones imprecisas o formuladas de manera ambigua, el LLM suele terminar siendo muy poco útil y produce resultados inesperados. Afortunadamente, Wolfram tiene una buena manera de combatir esta desventaja. no solo acepta una redacción estándar como argumento, sino que también permite proporcionar una lista de ejemplos que el LLM debe seguir:
Algunos ejemplos en esta publicación dependen de un modelo de lenguaje de gran tamaño (LLM) y requieren una clave de API.
In[]:=
extractDates = LLMExampleFunction[ "Extract the dates of both the start of an investigation and the end of an investigation. If you cannot find a date, return None", Import["https://www.judiciary.uk/wp-content/uploads/2024/07/Paula-Elsley-Prevention-of-future-deaths-report-2024-0361_Published.pdf", "Plaintext"] -> "{{2022,4,11},{2024,2,6}}", Import["https://www.judiciary.uk/wp-content/uploads/2024/07/Lee-McHale-Prevention-of-future-deaths-report-2024-0356_Published.pdf", "Plaintext"] -> "{{2023,11,28},{2024,6,17}}" ]
Out[]=
LLMFunction
Este fragmento de código utiliza LLMExampleFunction para crear una función que tomará como entrada archivos PDF importados y devolverá una lista que contiene las fechas de inicio y fin de las investigaciones:
In[]:=
datePairs=Monitor[Table[extractDates[pdfsWithLinks[[i,"Text"]]],{i,Length@pdfsWithLinks}],i]
Out[]=
In[]:=
datePairs=ToExpression/@datePairs
In[]:=
datePairs=extractDates/@pdfsWithLinks[[All,"Text"]];datePairs=ToExpression/@datePairs(*TurnsthestringstheLLMreturnedintoWolframexpressions*)
In[]:=
pfdsWithDates=Block[{pfd,newList,datePair},newList={};Table[pfd=pdfsWithLinks[[i]];datePair=datePairs[[i]];Quiet@AssociateTo[pfd,{"StartDate"->DateObject[datePair[[1]]],"EndDate"->DateObject[datePair[[2]]]}];AppendTo[newList,pfd];,{i,Length[pdfsWithLinks]}];Select[newList,FreeQ[#,None]&]];
Una representación gráfica de línea de tiempo de una muestra aleatoria de los resultados muestra que devolvió lo esperado (cada línea en la representación es una investigación):
Aplicaciones en el mundo real
Aplicaciones en el mundo real
La investigación académica previa de Alison Leary et al. ha investigado las principales áreas de preocupación que los forenses expresan en sus informes. Aquí utilizamos las categorías resultantes de dicha investigación y las aplicamos a nuestros propios datos. Con ello, podemos combinar los conocimientos previos de la academia, la potencia computacional de Wolfram Language y la fluidez de los LLM para obtener información sobre un corpus de datos mucho más amplio:
Código de categorización
Código de categorización
Representación gráfica
Representación gráfica
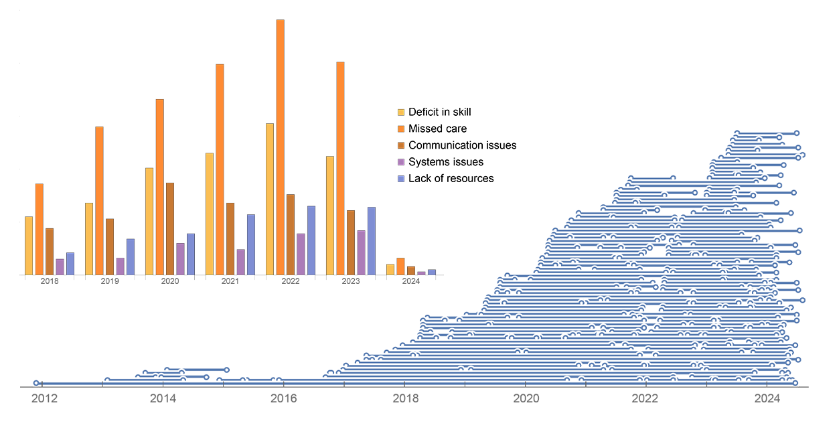
Al representar cada categoría para cada año del que tenemos informes en un diagrama de barras, podemos ver los PFD más comunes:
Un gráfico de barras apiladas es una forma alternativa de visualizar los mismos datos que nos permite centrarnos en la proporción de cada categoría dentro de cada año. Si bien la distribución es aproximadamente constante a lo largo de los años, podemos observar algunas tendencias temporales, por ejemplo, el pico en los problemas de comunicación en 2020. La barra correspondiente a 2024 es mucho más pequeña, ya que los datos se recopilaron en el verano de 2024, cuando la mayoría de los informes de ese año aún no se habían presentado:
Para visualizar mejor las tendencias actuales, podemos hacer que el gráfico de barras apiladas sea proporcional al 100% de las preocupaciones de cada año. De este modo, vemos que los problemas de comunicación van camino de tener una proporción mayor del total en comparación con años anteriores, pudiendo alcanzar los niveles que tuvieron en 2020:
Interestingly, these results mostly mirror the ones found in Leary’s work. This suggests that employing LLMs in the initial stages of tasks that aim to extract insights from natural language—such as thematic analyses—can be a valuable first step in getting meaning out of unstructured data. That is likely to be especially true in cases where broad categories have already been defined by previous works, and these definitions can be passed down as instructions to the LLMs.
Curiosamente, estos resultados reflejan en su mayoría los encontrados en el trabajo de Leary. Esto sugiere que emplear LLMs en las etapas iniciales de tareas que buscan extraer ideas a partir del lenguaje natural—como los análisis temáticos—puede ser un primer paso valioso para obtener significado de datos no estructurados. Probablemente esto sea especialmente cierto en casos donde las categorías generales ya han sido definidas por trabajos previos, y estas definiciones pueden transmitirse como instrucciones a los LLMs.
En adelante
En adelante
Usando las tecnologías Wolfram, podemos recopilar y preparar datos rápidamente para dedicar más tiempo a realizar análisis y encontrar soluciones que mejoren las prácticas en el futuro. ¡Si necesita ayuda adicional para aprender a computacionalizar su flujo de trabajo, asegúrese de consultar el nuevo Wolfram Notebook Assistant!