International Essays |
Utiliser l’IA pour l’analyse thématique : analyser des rapports de coroner avec les LLM
Utiliser l’IA pour l’analyse thématique : analyser des rapports de coroner avec les LLM
21 janvier 2025
Harrison Boon, ancien stagiaire et auteur invité, et Ned Pratt, ancien stagiaire et auteur invité
Au Royaume-Uni, les formulaires de prévention des décès futurs (PDF) jouent un rôle crucial pour garantir la sécurité publique. Il s’agit d’un type particulier de rapport du coroner qui documente bien plus que les seules circonstances du décès d’une personne. Les PDF sont émis lorsqu’un coroner enquête sur un décès et conclut qu’un risque spécifique ou une défaillance systémique, considéré comme évitable, a joué un rôle significatif dans ledit décès.
Bien que ces formulaires possèdent une structure dans la mesure où chacun comporte des sections qui doivent être remplies par des coroners, ces sections sont rédigées par les coroners en langage naturel, ce qui rend l’analyse de ces formulaires (jusqu’à présent) très chronophage, chaque rapport devant être lu par un être humain.
La vaste liste de fonctions intégrées de Wolfram Language permet d’effectuer, depuis le noyau Wolfram, des appels à divers grands modèles de langage (LLM). L’implémentation des LLM dans Wolfram signifie que l’extraction des données non structurées, telles que le contenu d’un rapport de médecin légiste, s’effectue en une fraction du temps. Nous pouvons ensuite utiliser les outils d’analyse de données de Wolfram pour traiter les informations recueillies.
Collecte des données
Collecte des données
Les tribunaux et cours judiciaires du Royaume-Uni publient un échantillon de ces PDF sur leur site web. Malheureusement, ils ne disposent pas d’une API publique permettant d’accéder à ces fichiers, ce qui signifie que la seule façon de les consulter est de visiter la page et de trouver chaque fichier. Cela prend énormément de temps à faire manuellement, nous devons donc créer un web scraping pour parcourir et télécharger automatiquement les PDF :
Remarque : toutes les données sont tirées des rapports judiciaires sur la prévention des décès futurs provenant des cours et des tribunaux sous la licence en accès libre v3 .0 du gouvernement.
In[]:=
(* To keep things simple, I'm only collecting pfd reports of a certain type *) pfdReportTypes= "hospital-death-clinical-procedures-and-medical-management-related-deaths", "alcohol-drug-and-medication-related-deaths", "care-home-health-related-deaths", "community-health-care-and-emergency-services-related-deaths", "emergency-services-related-deaths-2019-onwards", "mental-health-related-deaths";getPFDList[start_, end_] := Block[{htmlDocs, individualPageLinks, individualPages}, htmlDocs = Table[Import[URLBuild[<| "Scheme" -> "https", "Domain" -> "www.judiciary.uk", "Path" -> {"page", ToString[i]}, (* Iterate through the pages *) "Query" -> "pfd_report_type" -> #, (* Cycle throught just the report types we want *) "post_type" -> "pfd", "order" -> "desc" , "Fragment" -> None |>], "Text"]& /@ pfdReportTypes, {i, start, end}]; (* Now that we've got a list of the results pages, we need to grab each individual report's page *) individualPageLinks = Flatten[StringCases[#, "<a class=\"card__link\" href=\"" ~~ Shortest[url___] ~~ "\"" :> url]& /@ htmlDocs]; individualPageLinks = DeleteDuplicates[individualPageLinks]; (* The searches may have had overlapping results, which should be removed *) (* Each of these pages contains a link to a PDF file with the reports we want *) individualPages = Import[#, "Text"]& /@ individualPageLinks; First[StringCases[#, "related-content__link\" href=\"" ~~ Shortest[url___] ~~ "\"" :> url] ]& /@ individualPages ]
Vérifions que ce code fonctionne en récupérant les deux premières pages de liens :
In[]:=
getPFDList[1,2]//Short
Out[]//Short=
{https://www.judiciary.uk/wp-content/uploads/2024/08/Beverley-Stanisauskis-Prevention-of-Future-Deaths-Report-2024-0466.pdf,114,https://www.judiciary.uk/wp-content…aths-report-2024-0087_Published.pdf}
Brillant ! Maintenant, utilisons-le pour extraire davantage de pages :
In[]:=
pfdLinks=getPFDList[1,2];
In[]:=
pfdLinks=getPFDList[1,60];
In[]:=
pfdLinks//Short
Out[]//Short=
{https://www.judiciary.uk/wp-content/uploads/2024/10/Kingsley-Imafidon-Prevention-of-Future-Deaths-Report-2024-0554.pdf,2216,https://www.judici…-0195-Redacted.pdf}
In[]:=
pfdLinks>>pfdtexts
In[]:=
Export["links.txt",<<pfdtexts]
Out[]=
links.txt
In[]:=
SystemOpen["links.txt"]
Importons-les maintenant tous pour obtenir le texte du document :
In[]:=
pdfs=Import[#,"Plaintext"]&/@pfdLinks
In[]:=
pdfsWithLinks=<|"Link"->#1,"Text"->#2|>&@@@Thread[{#1,#2}&[pfdLinks,pdfs]];pdfsWithLinks=Select[pdfsWithLinks,StringLength[#Text]>150&];(*Filteroutanyemptyorincompletereports*)pdfsWithLinks//Dataset
Extraction de données
Extraction de données
Avec les données désormais collectées, il est maintenant intéressant d’examiner la durée de ces enquêtes représentée au fil du temps. La manière traditionnelle de procéder serait de demander à quelqu’un de lire tous ces rapports et de saisir manuellement les dates de début et de fin d’une enquête dans une feuille de calcul. Cela semble très chronophage (et ennuyeux). Les LLM peuvent être extrêmement utiles ici, en ayant suffisamment de connaissances pour pouvoir lire le rapport et en extraire uniquement les deux dates, tout en prenant beaucoup moins de temps qu’un être humain.
Un des inconvénients concernant l’utilisation des LLM est qu’il faut souvent leur fournir de nombreuses instructions (invites) afin de contraindre leur comportement. Avec des instructions imprécises ou formulées de manière vague, le LLM finit souvent par être peu utile et produit des résultats inattendus. Heureusement, Wolfram dispose d’un bon moyen de remédier à cet inconvénient. accepte non seulement des instructions standard comme argument, mais vous permet également de fournir une liste d’exemples que le LLM doit suivre :
Certains exemples dans cet article reposent sur un grand modèle de langage (LLM) et nécessitent une clé API.
In[]:=
extractDates = LLMExampleFunction[ "Extract the dates of both the start of an investigation and the end of an investigation. If you cannot find a date, return None", Import["https://www.judiciary.uk/wp-content/uploads/2024/07/Paula-Elsley-Prevention-of-future-deaths-report-2024-0361_Published.pdf", "Plaintext"] -> "{{2022,4,11},{2024,2,6}}", Import["https://www.judiciary.uk/wp-content/uploads/2024/07/Lee-McHale-Prevention-of-future-deaths-report-2024-0356_Published.pdf", "Plaintext"] -> "{{2023,11,28},{2024,6,17}}" ]
Out[]=
LLMFunction
Ce morceau de code utilise LLMExampleFunction pour créer une fonction qui prendra des PFF importés en entrée et renverra une liste contenant les dates de début et de fin des enquêtes :
In[]:=
datePairs=Monitor[Table[extractDates[pdfsWithLinks[[i,"Text"]]],{i,Length@pdfsWithLinks}],i]
Out[]=
In[]:=
datePairs=ToExpression/@datePairs
In[]:=
datePairs=extractDates/@pdfsWithLinks[[All,"Text"]];datePairs=ToExpression/@datePairs(*TurnsthestringstheLLMreturnedintoWolframexpressions*)
In[]:=
pfdsWithDates=Block[{pfd,newList,datePair},newList={};Table[pfd=pdfsWithLinks[[i]];datePair=datePairs[[i]];Quiet@AssociateTo[pfd,{"StartDate"->DateObject[datePair[[1]]],"EndDate"->DateObject[datePair[[2]]]}];AppendTo[newList,pfd];,{i,Length[pdfsWithLinks]}];Select[newList,FreeQ[#,None]&]];
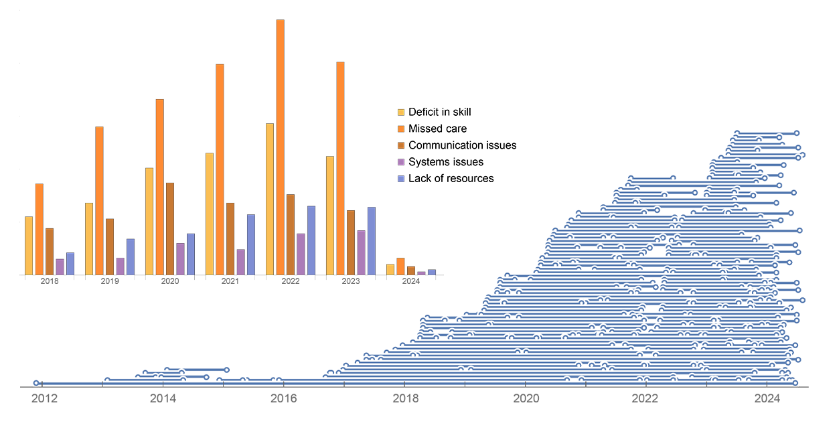
Un tracé chronologique d’un échantillon aléatoire des résultats montre qu’il a donné ce qui était attendu (chaque ligne du tracé représente une enquête) :
Applications concrètes
Applications concrètes
Des recherches universitaires antérieures menées par Alison Leary et al. ont étudié les principaux domaines de préoccupation que les coroners expriment dans leurs rapports. Ici, nous utilisons les catégories issues de cette recherche et les appliquons à nos propres données. Ainsi, nous sommes en mesure de combiner les enseignements académiques antérieurs, la puissance de calcul de Wolfram Language et la fluidité des LLM afin de dégager des analyses sur un corpus de données beaucoup plus vaste :
Code de catégorisation
Code de catégorisation
Traçage
Traçage
En traçant chaque catégorie pour chaque année pour laquelle nous disposons de rapports dans un diagramme à barres, nous pouvons voir les PDF les plus courants :
Un diagramme à barres empilées est une autre manière de visualiser les mêmes données qui nous permet de nous concentrer sur la proportion de chaque catégorie au sein de chaque année. Bien que les résultats soient globalement cohérents d’une année à l’autre, nous pouvons observer certaines tendances temporelles, par exemple le pic des problèmes de communication en 2020. La barre pour 2024 est beaucoup plus petite puisque les données ont été collectées à l’été 2024, lorsque la plupart des rapports pour cette année n’avaient pas encore été soumis :
Pour mieux visualiser les tendances actuelles, nous pouvons faire en sorte que le diagramme à barres empilées soit proportionnel à 100 % des préoccupations de l’année. Nous constatons alors que les problèmes de communication sont en passe de représenter une proportion plus élevée de la part totale par rapport aux années précédentes, atteignant potentiellement les niveaux qu’ils avaient en 2020 :
Fait intéressant, ces résultats reflètent en grande partie ceux observés dans les travaux de Leary. Cela suggère que l’utilisation des LLM aux premières étapes des tâches visant à extraire des enseignements du langage naturel, telles que les analyses thématiques, peut constituer une première étape précieuse pour dégager du sens à partir de données non structurées. Cela est probablement particulièrement vrai dans les cas où de grandes catégories ont déjà été définies par des travaux antérieurs, et où ces définitions peuvent être transmises comme instructions aux LLM.
Pour la suite
Pour la suite
En utilisant les technologies Wolfram, nous pouvons rapidement collecter et préparer des données afin de consacrer davantage de temps à effectuer des analyses et à trouver des solutions pour améliorer les pratiques à l’avenir. Pour obtenir une aide supplémentaire afin d’apprendre à computationnaliser votre flux de travail, n’oubliez pas de consulter le nouvel assistant : Wolfram Notebook Assistant !