International Essays |
Lancement de Wolfram Neural Net Repository
Lancement de Wolfram Neural Net Repository
11 juin 2018
Sebastian Bodenstein, Matteo Salvarezza, Meghan Rieu-Werden, Taliesin Beynon
Groupe de recherche avancée
Groupe de recherche avancée
Aujourd’hui, nous sommes ravis d’annoncer le lancement officiel de Wolfram Neural Net Repository ! Une quantité considérable de travail a été consacrée à l’entraînement ou à la conversion d’environ 70 modèles de réseaux neuronaux qui se trouvent désormais dans le répertoire et peuvent être accessibles de manière programmatique dans Wolfram Language via NetModel :
net=NetModel["ResNet-101 Trained on ImageNet Competition Data"]
NetChain

net

Les réseaux neuronaux ont suscité beaucoup d’intérêt récemment, et à juste titre : ils constituent la base des solutions de pointe pour une gamme vertigineuse de problèmes, de la reconnaissance vocale à la traduction automatique, de la conduite autonome au jeu de Go. Heureusement, Wolfram Language dispose désormais d’un cadre de réseaux neuronaux de pointe (ainsi que d’une collection de tutoriels en expansion). Cela a rendu possible tout un nouvel ensemble de fonctions de Wolfram Language, telles que FindTextualAnswer, ImageIdentify, ImageRestyle et FacialFeatures. Et l’apprentissage profond jouera sans aucun doute un rôle important dans notre mission continue visant à rendre les connaissances humaines calculables.
Il est chose commune que les chercheurs rendent leurs réseaux entraînés accessibles au public. Ce qui est un grand avantage concernant l’apprentissage profond dans la communauté. Ces réseaux se présentent souvent sous la forme de scripts et de fichiers de données disparates utilisant une multitude de cardes de réseaux neuronaux. Un objectif majeur de notre dépôt est de sélectionner et de publier ces modèles dans un format standard et facile à utiliser peu de temps après leur publication. De plus, nous fournissons nos propres modèles entraînés pour diverses diverses tâches.
Cependant, l’entraînement des réseaux neuronaux de pointe nécessite souvent d’énormes ensembles de données et des ressources de calcul importantes qui sont inaccessibles à la plupart des utilisateurs. Un répertoire de réseaux offre aux utilisateurs de Wolfram Language un accès facile aux architectures de réseaux les plus récentes et à des réseaux pré-entraînés, représentant des milliers d’heures de temps de calcul sur des processeurs graphique puissants.
Ce blog couvrira trois principales façons d’utiliser Wolfram Neural Net Repository :
◼
Présentation des technologies basées sur l’apprentissage profond. Bien qu’une grande partie de ces fonctionnalités soit finalement intégrée sous forme de fonctions officielles de Wolfram Language, le dépôt fournit un accès anticipé à un vaste ensemble de fonctionnalités qu’il était jusqu’à présent entièrement impossible de réaliser dans Wolfram Language.
◼
Utilisation de réseaux pré-entraînés comme puissants extracteurs de caractéristiques. Les réseaux pré-entraînés peuvent être utilisés comme puissantes fonctions FeatureExtractor dans l’ensemble des autres fonctionnalités d’apprentissage automatique de Wolfram Language, telles que Classify, Predict, FeatureSpacePlot, etc. Cela offre aux utilisateurs un contrôle précis sur l’intégration des connaissances préalables dans leurs pipelines d’apprentissage automatique.
◼
Construction des réseaux à l’aide d’architectures prêtes à l’emploi et de composantes pré-entraînées. L’accès à des modules soigneusement conçus et entraînés ouvre un paradigme de plus haut niveau pour l’utilisation du cadre de réseaux neuronaux Wolfram. Ce paradigme libère les utilisateurs de la tâche difficile et laborieuse consistant à construire de bonnes architectures de réseaux à partir de couches individuelles et leur permet de transférer les connaissances issues de réseaux entraînés sur différents domaines vers leurs propres problèmes.
Disposer d’une bibliothèque diversifiée et riche en réseaux disponibles dans Wolfram Neural Net Repository permettant catalyser le développement le cadre Wolfram des réseaux neuronaux lui-même est un avantage important mais indirect. En particulier, l’ajout de modèles opérant sur l’audio et le textea entraîné un ensemble varié d’améliorations du cadre ; celles-ci incluent une prise en charge étendue des dimensions dites dynamiques (tenseurs de longueur variable), cinq nouveaux types audio de NetEncoder et NetStateObject pour une génération récurrente aisée.
Voici un exemple Chaque réseau publié dans Wolfram Neural Net Repository dispose de sa propre page web. Voici, par exemple, la page d’un réseau qui prédit la géo-position d’une image :
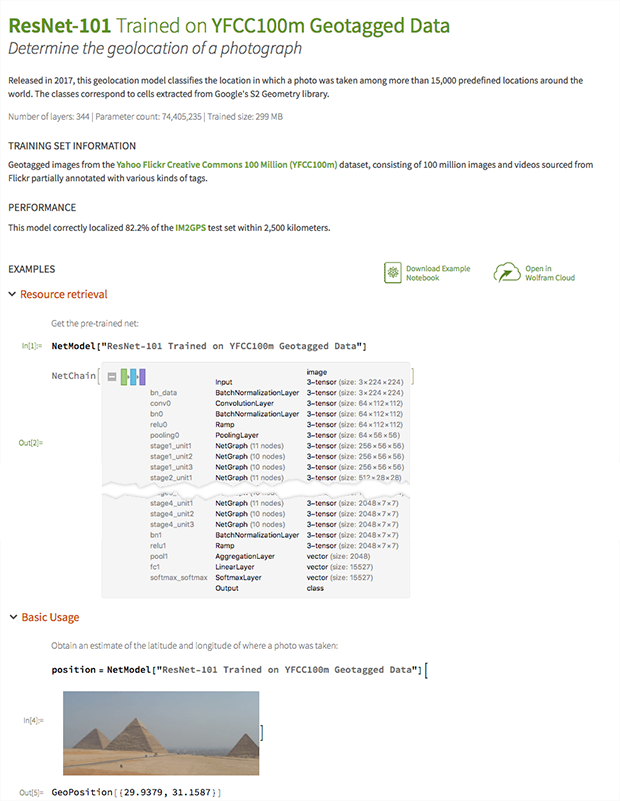
En haut de la page se trouvent des informations sur le réseau, telles que sa taille et les données sur lesquelles il a été entraîné. Dans ce cas, le réseau a été entraîné sur 100 millions d’images. Ensuite, un notebook Wolfram montre comment utiliser le réseau, lequel peut être téléchargé ou ouvert dans Wolfram Cloud via ces boutons :

L’utilisation de notebooks dans Wolfram Cloud permet d’exécuter les exemples dans votre navigateur sans avoir à installer quoi que ce soit.
Dans la section des utilisations de base, nous pouvons immédiatement voir à quel point il est facile d’effectuer un calcul avec ce réseau. Examinons cet exemple plus en détail. Tout d’abord, nous obtenons le réseau lui-même en utilisant NetModel :
net = NetModel["ResNet-101 Trained on YFCC100m Geotagged Data"]
NetChain
La première fois que ce réseau particulier est demandé, le fichier WLNet sera téléchargé depuis les serveurs de Wolfram Research, au cours de quoi une fenêtre de progression s’affichera :

Ensuite, nous appliquons immédiatement ce réseau à une image pour obtenir la prédiction de ce réseau, qui est la position géographique où la photo a été prise :
position=net

GeoPosition[{29.9379,31.1587}]
La GeoPosition produite en sortie de ce réseau contraste fortement avec la plupart des autres environnements, où seuls des tableaux numériques correspondent aux entrées et sorties valides d’un réseau. Un un script séparé est alors nécessaire est alors nécessaire pour importer une image, la redimensionner, la conformer à l’espace colorimétrique approprié et éventuellement supprimer l’image moyenne, avant de produire le tenseur numérique requis par le réseau. Dans Wolfram Language, nous aimons que les réseaux soient « batteries incluses », avec la logique de prétraitement et de post-traitement intégrée au réseau lui-même. Pour ce faire, un NetEncoder “Image” est connecté au port d’entrée du réseau et un NetDecoder “Class” interprète la sortie comme un objet GeoPosition.
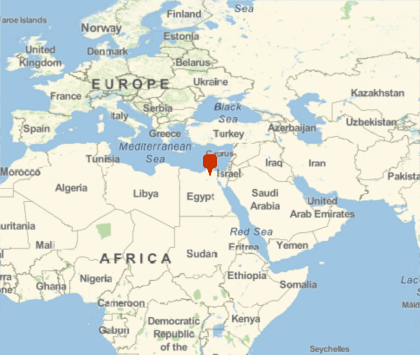
Comme le réseau renvoie un objet GeoPosition plutôt qu’une simple liste de données, on peut immédiatement effectuer des calculs supplémentaires dessus. Par exemple, nous pouvons tracer la position sur une carte :
GeoGraphics[GeoMarker[position],GeoRange4000000]
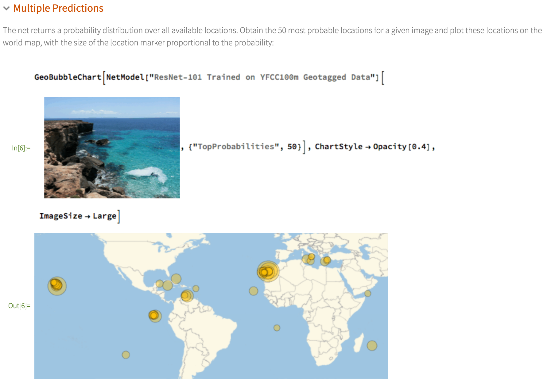
Après la section d’exemples de base se trouvent des sections présentant d’autres démonstrations intéressantes, par exemple :
La possibilité d’exporter des réseaux vers d’autres cadres est une fonctionnalité très importante que nous proposons. Actuellement, nous prenons en charge l’exportation vers Apache MXNet, et la section finale de chaque page d’exemple montre généralement comment procéder :

Qu’y a-t-il dans Wolfram Neural Net Repository jusqu’à présent ? Nous avons investi beaucoup d’efforts pour convertir des modèles accessibles au public provenant d’autres cadres de réseaux neuronaux (tels que Caffe, Torch, MXNet, TensorFlow, etc.) vers le format de réseau neuronal Wolfram. En outre, nous avons nous-mêmes entraîné un certain nombre de réseaux. Par exemple, le réseau appelé par ImageIdentify est disponible via NetModel[“Wolfram ImageIdentify Net V1”]. À la date de cette version, il existe environ 70 modèles disponibles :
Étant donné que l’ajout de nouveaux réseaux est une tâche en cours, de nombreux autres réseaux seront ajoutés au cours de l’année prochaine. Examinons quelques-unes des principales classes de réseaux disponibles dans le dépôt.
Il existe des réseaux qui effectuent la classification, par exemple, pour déterminer le type d’objet dans une image :
Ou estimer l’âge d’une personne à partir d’une image de son visage :
Il existe des réseaux qui effectuent une régression, par exemple, prédire la position des yeux, de la bouche et du nez dans une image de visage :
Ou reconstruire la forme 3D d’un visage :
Il existe des réseaux qui effectuent la modélisation du langage. Par exemple, un modèle anglais au niveau des caractères donne la probabilité du caractère suivant étant donnée une séquence de caractères :
Il existe des réseaux qui effectuent divers types de traitement d’image, par exemple, transférer le style d’une image à une autre :
Il existe des réseaux qui effectuent une classification au niveau des pixels des images (segmentation sémantique), par exemple, classifier chaque pixel dans l’image d’une scène urbaine :
Évaluation du réseau pour la segmentation sémantique
Évaluation du réseau pour la segmentation sémantique
Exécutez toutes les cellules de code dans cette section.
Il existe des réseaux neuronaux qui trouvent tous les objets et leurs boîtes englobantes dans une image (détection d’objets) :
Fonction d’évaluation pour le réseau de détection d’objets
Fonction d’évaluation pour le réseau de détection d’objets
Il existe des réseaux qui sont entraînés pour représenter des images, du texte, etc. sous forme de vecteurs numériques. Par exemple, NetModel[“GloVe 25-Dimensional Word Vectors Trained on Wikipedia and Gigaword 5 Data”] convertit des mots en vecteurs :
Ces vecteurs peuvent être projetés en deux dimensions et tracés à l’aide de FeatureSpacePlot :
Fait intéressant, les mots « Apple » et « Blackberry » ne sont pas regroupés avec les autres fruits, car ce sont aussi des noms de marque. Cela montre une limitation fondamentale de cet extracteur de caractéristiques : les homonymes ne peuvent pas être distingués, puisque le contexte est ignoré. Un réseau d’intégration de mots plus sophistiqué (ELMo) qui prend le contexte en compte peut lever l’ambiguïté des significations :
Effectuer un transfert d’apprentissage dans Wolfram Language est incroyablement simple. À titre d’exemple, considérons le problème consistant à classer des images comme étant soit des chats soit des chiens :
Entraînons un classifieur en utilisant Classify directement à partir des valeurs de pixels des images en spécifiant FeatureExtractor”PixelVector” :
La précision sur l’ensemble de test n’est pas meilleure que le simple fait de deviner la classe, ce qui signifie qu’aucun véritable apprentissage n’a eu lieu :
Pourquoi Classify n’a-t-il effectué aucun apprentissage ? La raison est simple : distinguer des chats des chiens en utilisant uniquement les valeurs des pixels est extrêmement difficile. Un ensemble d’exemples d’entraînement beaucoup plus vaste est nécessaire pour que Classify puisse déterminer les règles extrêmement complexes qui permettent de distinguer les chats des chiens à partir des valeurs des pixels.
Choisissons maintenant un réseau pré-entraîné similaire au problème que nous résolvons ici. Dans ce cas, un réseau entraîné sur le jeu de données ImageNet est un bon choix :
Une observation fondamentale concernant les réseaux neuronaux est que les premières couches effectuent une extraction de caractéristiques plus générique, tandis que les couches ultérieures sont spécialisées pour la tâche exacte sur laquelle le jeu de données est entraîné. Les deux dernières couches de ce réseau sont entièrement spécialisées pour la tâche ImageNet consistant à classer une image parmi 1 000 classes différentes. Ces couches peuvent être supprimées à l’aide de NetDrop afin que le réseau produise désormais un vecteur de dimension 2 048 lorsqu’il est appliqué à une image :
Ce vecteur est appelé une représentation ou une caractéristique de l’image, et vit dans un espace dans lequel les objets de différents types sont regroupés de manière harmonieuse. On peut visualiser cela en utilisant FeatureSpacePlot avec le réseau en tant que fonction FeatureExtractor :
Dans l’espace de pixels d’origine, les chiens et les chats ne sont pas du tout regroupés :
Ce réseau peut maintenant être utilisé comme fonction FeatureExtractor dans Classify, ce qui signifie que Classify utilisera ce vecteur de sortie à 2 048 dimensions au lieu des pixels bruts de l’image pour l’entraînement. Les performances s’améliorent considérablement :
Il n’est pas si surprenant de voir que cela fonctionne, une fois que vous avez réalisé que certaines des classes ImageNet sur lesquelles le réseau a été entraîné à faire la distinction sont différents types de chiens et de chats :
Mais supposons plutôt que vous utilisiez un réseau entraîné sur une tâche très différente, par exemple, pour prédire la géolocalisation d’une image :
Bien qu’il n’ait pas été directement entraîné à distinguer les chiens des chats, l’utilisation de ce réseau en tant que fonction FeatureExtractor dans Classify donne une précision parfaite sur l’ensemble du test :
C’est bien plus surprenant, et cela montre la véritable puissance de l’utilisation de réseaux pré-entraînés pour le transfert d’apprentissage : des réseaux entraînés sur une tâche peuvent être utilisés comme extracteurs de caractéristiques pour résoudre des tâches très différentes !
Il convient de mentionner que Classify essaiera automatiquement d’utiliser des réseaux pré-entraînés en tant que fonctions FeatureExtractor lorsque les types d’entrée sont des images. Par conséquent, il offrira également une grande précision de classification sur ce petit jeu de données :
Il existe une autre manière d’utiliser des réseaux pré-entraînés pour l’apprentissage par transfert qui offre à l’utilisateur beaucoup plus de contrôle et qui est plus générale que l’utilisation de Classify et de Predict. Il s’agit d’utiliser des réseaux pré-entraînés comme briques de base à partir desquelles construire de nouveaux réseaux, ce que nous examinerons dans la section suivante.
Développement de réseaux neuronaux de niveau supérieur L’un des principes clés à la base de la conception du cadre de réseaux neuronaux Wolfram est de viser un niveau d’abstraction plus élevé comparé à la plupart des autres cadres de réseaux neuronaux. Nous voulons libérer les utilisateurs de la nécessité de se préoccuper de la manière d’entraîner efficacement sur des données de séquences de longueur variable sur du matériel moderne, ou de la manière de mieux initialiser les poids et les biais du réseau avant l’entraînement. Même des détails d’implémentation comme l’omniprésente « dimension de lot » sont masqués. Notre philosophie est que le cadre doit prendre en charge ces détails afin que les utilisateurs puissent se concentrer entièrement sur leurs problèmes réels.
Disposer d’un vaste répertoire de modèles de réseaux neuronaux est un élément absolument essentiel pour concrétiser cette vision consistant à utiliser les réseaux neuronaux au plus haut niveau possible, car cela permet aux utilisateurs d’éviter l’une des parties les plus difficiles et les plus frustrantes de l’utilisation des réseaux neuronaux : trouver une bonne architecture de réseau pour un problème donné. En outre, commencer avec des réseaux pré-entraînés peut améliorer considérablement les performances des réseaux neuronaux sur des ensembles de données plus restreints grâce à l’apprentissage par transfert.
Pour comprendre les raisons pour lesquelles définir votre propre réseau est difficile, considérez le problème consistant à entraîner un réseau neuronal sur votre propre jeu de données en utilisant NetTrain. Pour ce faire, vous devez fournir à NetTrain un réseau à utiliser pour l’entraînement. À titre d’exemple, définissez un réseau simple (LeNet) capable de classer des images de chiffres manuscrits entre 0 et 9 :
Cette définition est d’un niveau assez bas, exigeant une compréhension attentive de ce que fait chacune de ces couches si l’on conçoit un tel réseau à partir de zéro. La liste des couches disponibles est également en constante expansion :
Laquelle de ces plus de 40 couches devriez-vous utiliser pour votre problème ? Et même si vous disposez d’un réseau existant à copier, le copier vous-même à partir d’un article ou d’une autre implémentation peut être une tâche très longue et sujette aux erreurs, car les réseaux modernes comportent généralement des centaines de couches :
Enfin, même si vous êtes un expert en réseaux neuronaux et que vous acquiescez à des affirmations telles que « l’utilisation du regroupement peut être considérée comme l’ajout d’un a priori infiniment fort selon lequel la fonction que la couche apprend doit être invariante aux petites translations », vous devriez néanmoins presque toujours éviter d’essayer de concevoir votre propre réseau. Pour comprendre pourquoi, considérez le défi ImageNet de reconnaissance visuelle à grande échelle, où les participants reçoivent plus d’un million d’images d’objets provenant de plus de 1 000 classes. Les meilleures performances au cours des cinq dernières années sont les suivantes (plus le nombre est faible, meilleure est la performance) :
Il a fallu une demi-décennie d'expérimentations menées par certains des chercheurs en apprentissage automatique les plus brillants encore vie, disposant de vastes ressources de calcul, pour découvrir une architecture de réseau capable d'obtenir une erreur top-5 inférieure à 2,5 %.
Le consensus actuel au sein de la communauté des réseaux neuronaux est que construire votre propre architecture de réseau est inutile pour la majorité des applications de réseaux neuronaux et nuit généralement aux performances. Au contraire, adapter un réseau pré-entraîné à votre propre problème constitue presque toujours une meilleure approche en termes de performances. Heureusement, cette approche présente l’avantage supplémentaire d’être beaucoup plus facile à utiliser !
Disposer d’un vaste dépôt de réseaux neuronaux est donc absolument essentiel pour être productif avec le cadre des réseaux neuronaux, car cela vous permet de rechercher un réseau proche du problème que vous résolvez, d’effectuer un minimum de « chirurgie » sur le réseau pour l’adapter à votre problème spécifique, puis de l’entraîner.
Examinons un exemple de ce processus de développement de « haut niveau » pour résoudre le problème de classification « chat contre chien » dans la section précédente. Tout d’abord, obtenez un réseau similaire à notre problème :
Les deux dernières couches sont spécialisées pour la tâche de classification ImageNet, nous supprimons donc simplement les deux dernières couches en utilisant NetDrop :
Notez qu’il est particulièrement facile d’effectuer une « chirurgie de réseau » dans Wolfram Language : les réseaux sont des expressions symboliques qui peuvent être manipulées à l’aide d’un large éventail de fonctions chirurgicales, telles que NetTake, NetDrop, NetAppend, NetJoin, etc. Nous devons maintenant simplement définir un nouveau NetChain qui classera une image comme « chien » (dog) ou « chat » (cat) :
Ce réseau peut être entraîné immédiatement :
Le taux d’erreur sur l’ensemble d’entraînement chute rapidement à 0 %, mais il n’est jamais inférieur à 25 % sur l’ensemble de validation. Il s’agit d’un cas classique de sur-apprentissage : notre modèle se contente de mémoriser l’ensemble d’entraînement et est incapable de reconnaître des exemples sur lesquels il n’a pas été entraîné. Il n’est guère surprenant que ce modèle soit en sur-apprentissage, étant donné qu’il possède plus de 20 millions de paramètres et que nous ne disposons que de 14 exemples d’entraînement :
Il est plus approprié pour ce minuscule jeu de données d’empêcher NetTrain de modifier tout paramètre sauf ceux de la couche « classifier ». On peut réaliser cela avec LearningRateMultipliers :
Cette procédure est presque identique à l’utilisation de Classify avec “LogisticRegression” comme Method et en utilisant netFeature comme fonction FeatureExtractor. Lorsque vous disposez d’un ensemble d’entraînement massif, empêcher les paramètres de changer pendant l’entraînement nuira aux performances, et l’utilisation de LearningRateMultipliers devrait donc être évitée. Même partir d’un réseau pré-entraîné pourrait nuire aux performances sur un jeu de données très volumineux, et il peut être judicieux de partir plutôt d’un réseau non initialisé :
Mais entre des ensembles de données « massifs » et « minuscules » se trouve tout un éventail de tailles, pour lesquelles une restriction plus sophistiquée sur la manière dont les paramètres peuvent varier est appropriée. Un exemple simple consiste à autoriser les paramètres de la couche « linéaire » et de l’avant-dernière couche du sous-réseau de « caractéristiques » à varier à un rythme réduit, tandis que tous les autres paramètres sont fixés :
Voici un exemple plus compliqué de construction de réseau Considérez le problème consistant à construire un réseau qui prend une image et une question à propos de l’image, et qui prédit la réponse à la question. Un jeu de données simplifié pour cette tâche est :
Il existe un certain nombre de bons jeux de données du monde réel disponibles. Comment concevrions-nous un réseau pour résoudre cette tâche ?
L’idée est très simple : trouver un NetModel qui est performant pour comprendre le texte, et un autre qui comprend les images. Pour l’entrée de la question, utilisez NetModel[“ELMo Contextual Word Representations Trained on 1B Word Benchmark”] pour obtenir une représentation vectorielle contextuelle des mots, puis appliquez une couche récurrente aux représentations des mots afin de produire une représentation vectorielle de la phrase :
Pour l’image, utilisez à nouveau un réseau entraîné sur ImageNet :
Nous combinons maintenant simplement les caractéristiques « question » et « image » en les additionnant, puis nous utilisons la caractéristique combinée pour la classification :
Il existe de meilleures méthodes plus complexes pour combiner des caractéristiques, mais cette procédure suffit pour qu’un certain entraînement ait lieu. Par exemple, nous entraînons ici le réseau tout en figeant les paramètres des extracteurs de caractéristiques :
Ce jeu de données est évidemment beaucoup trop petit pour qu’un apprentissage significatif ait lieu, mais il est suffisant pour montrer à quel point il est simple à résoudre. Nous pouvons maintenant évaluer le réseau entraîné sur un exemple :
À l’avenir Dans les mois à venir, vous assisterez à une expansion majeure du nombre de modèles dans Wolfram Neural Net Repository. Certains d’entre eux seront de nouveaux réseaux que nous entraînons nous-mêmes. D’autres seront importés d’autres cadres. La prise en charge du format ONNX que nous prévoyons d’ajouter pour Mathematica 12 devrait accélérer ce processus et faciliter le déploiement de ces modèles dans d’autres systèmes.
Pour finir, de meilleures façons de représenter des familles de modèles constituent également une partie importante de notre carnet de route. Des modèles comme Sketch-RNN possèdent des centaines de variantes entraînées, et nous prévoyons de fournir une manière uniforme d’y faire référence, p. ex. NetModel[{“Sketch-RNN Generative Net”, “Class” “Cat”}]. Les réseaux non entraînés se prêtent encore mieux à une paramétrisation de cette manière. Par exemple, un réseau convolutionnel VGG concret pourrait être construit en spécifiant les paramètres requis, p. ex. NetModel[{“Untrained VGG for Image Classification”, “Depth” -> 50, “FilterNumber” -> 100, “DropoutProbability” -> 0.1}].
Dans cet article de blog, nous avons mis en évidence quelques exemples de réseaux pré-entraînés qui sont accessibles en appelant simplement une fonction dans Wolfram Language. Nous avons également montré à quel point il est facile d’employer l’apprentissage par transfert pour résoudre de nouveaux problèmes en utilisant des réseaux existants comme point de départ. Et au fil de la présentation, nous avons vu quelques exemples du type de développement rapide et de haut niveau que le cadre de réseaux neuronaux Wolfram rend possible.
◼
Notes
Donc, effectuer les 20 exaFLOPs de calcul nécessaires pour entraîner Deep Speech 2 prendrait (en années) :
Pour effectuer l’entraînement dans des délais raisonnables, un matériel spécialisé est nécessaire. La solution la plus courante consiste à utiliser des unités de traitement graphique (processeur graphique), qui peuvent exploiter efficacement le parallélisme massif dans les calculs des réseaux neuronaux. NetTrain prend en charge un grand nombre d’entre elles via TargetDevice”GPU”.
Importance de l’utilisation d’architectures de réseaux neuronaux existantes Andrej Karpathy (directeur de l’IA chez Tesla) l’exprime bien :
◼
« Si vous ressentez une certaine fatigue à réfléchir aux décisions architecturales, vous serez heureux d’apprendre que, dans 90 % ou plus des applications, vous ne devriez pas avoir à vous en préoccuper. J’aime résumer ce point ainsi : “ne jouez pas les héros”, au lieu de concevoir votre propre architecture pour un problème, vous devriez examiner quelle architecture fonctionne actuellement le mieux sur ImageNet, télécharger un modèle pré-entraîné et l’affiner sur vos données. Vous ne devriez presque jamais avoir à entraîner un ConvNet à partir de zéro ni à en concevoir un à partir de zéro. »