International Essays |
Analyse du débat présidentiel démocrate à l’aide de Wolfram Language
Analyse du débat présidentiel démocrate à l’aide de Wolfram Language
6 février 2020
Brian Wood, rédacteur technique principal, systèmes de documentation et de médias
Lorsque 20 candidats à la présidence s’affrontent sur la scène d’un débat, qui gagne ? Les Américains ont suivi une saison des primaires très animée et controversée pour la nomination du candidat démocrate à la présidence en 2020. Après les débats, tout le monde parle de qui a eu le plus de temps de parole ou d’attention, quels échanges ont été les plus passionnants ou d’autres critères permettant de déterminer qui a « gagné » la soirée, et de qui pourrait finalement remporter la victoire lors des caucus. J’ai donc décidé de mener une petite exploration des débats en utilisant le cadre d’entités, l’analyse de texte et les fonctionnalités de graphes de Wolfram Language, afin de voir si je pouvais élaborer ma propre mesure d’une « victoire » lors d’un débat, basée sur le candidat ou la candidate le ou la plus central(e) dans la conversation.
Importation de texte : Qu’a-t-on dit ? Dans un monde idéal, l’audio et la vidéo du débat seraient lisibles par machine. Mais en l’état actuel des choses, nous avons au moins accès au texte sous forme de transcription. Avant de nous lancer, il est utile de disposer de quelques informations préliminaires.
Tout d’abord, récupérons une liste de noms de candidats. Comme des candidats continuent à se présenter et à se retirer, j’ai construit cette liste manuellement au fil du temps :
In[]:=
candidateNames={"Amy Klobuchar","Andrew Yang","Bernie Sanders","Beto O'Rourke","Bill De Blasio","Cory Booker","Elizabeth Warren","Eric Swalwell","Jay Inslee","Joe Biden","John Delaney","John Hickenlooper","Julián Castro","Kamala Harris","Kirsten Gillibrand","Marianne Williamson","Michael Bennet","Pete Buttigieg","Steve Bullock","Tim Ryan","Tulsi Gabbard","Tom Steyer"};
Nous pouvons utiliser pour voir quels candidats le système Wolfram reconnaît. Il s’avère que ce sont tous les candidats suivants :
In[]:=
candidates=Interpreter["Person"]@candidateNames
Out[]=
,,,,,,,,,,,,,,,,,,,,,
Pour une analyse syntaxique correcte des questions, nous choisissons aussi les noms des modérateurs (aucune entité requise dans ce cas) :
In[]:=
modNames={"Lester Holt","Savannah Guthrie","Chuck Todd","Rachel Maddow","Jake Tapper","Dana Bash","Don Lemon","George Stephanopoulos","Jorge Ramos","Linsey Davis","David Muir","Anderson Cooper","Erin Burnett","Marc Lacey","Andrea Mitchell","Ashley Parker","Kristen Welker","Judy Woodruff","Yamiche Alcindor","Amna Nawaz","Tim Alberta","Jose Diaz-Balart","Wolf Blitzer","Abby Phillip","Brianne Pfannenstiel","ANNOUNCER"};
Enfin, nous les combinons en une liste de toutes les personnes qui ont soit parlé, soit à qui on a parlé :
In[]:=
debateNames=Join[candidateNames,modNames];debatePeople=Join[candidates,modNames];
Pour parcourir la transcription, il est également utile de la diviser en listes de prénoms et de noms de famille :
In[]:=
{firstNames,lastNames}=Transpose[{First[#],StringRiffle@Rest@#}&/@StringSplit[debateNames]];
Les transcriptions peuvent provenir de n’importe quelle source ; heureusement, la mise en forme est assez standard d’une source à l’autre. L’importation de la transcription est très simple avec ; nous commencerons par le texte brut du débat le plus récent (14 janvier) tel que transcrit par Rev.com :
In[]:=
d7raw=Import["https://wolfr.am/K7dyQhOh"];
Vous pouvez voir sur le site web que chaque réplique prononcée commence par le nom de l’orateur, avec quelques variations comme « E. Warren », suivi de deux-points et d’un horodatage, puis du contenu de la réplique. Nous pouvons utiliser pour extraire chacun de ces éléments (y compris toutes les variantes de noms, mis en icône par souci de concision) de la transcription :
In[]:=
d7Lines=StringTrim/@StringCasesStringReplaced7raw,,Shortest[name:(debateNames)~~": "~~("("~~time:__~~")")~~__~~line__~~"\n"~~debateNames]{name,time,line},IgnoreCaseFalse,OverlapsTrue;
Chaque entrée est une liste contenant ces trois éléments :
In[]:=
RandomChoice[d7Lines]
Out[]=
{Brianne Pfannenstiel,40:50,Mayor Buttigieg, your response?}
Ensuite, nous convertissons cela en une liste chronologique de règles orateurréplique. Toutes les transcriptions que j’ai trouvées n’avaient pas d’horodatages, je les ai donc omis de ces données :
In[]:=
d7Data=(#1/.Thread[debateNamesdebatePeople])#3&@@@d7Lines;
Voici une entrée de cette liste :
In[]:=
RandomChoice[d7Data]
Out[]=
Bien que les étapes aient varié, j’ai pu constituer ces jeux de données pour chaque transcription de débat. Voici l’ensemble des données des sept débats jusqu’à présent :
In[]:=
allDebateData=CloudGet["https://wolfr.am/K7wv2AEd"];
Analyse : Qui a parlé de quoi, et combien de temps ? Les données du cloud nous donnent suffisamment d’informations pour commencer à explorer par le calcul. Par exemple, les gens jugent souvent le débat en fonction de la personne qui a eu le plus de temps de parole. Nous pouvons l’estimer approximativement en utilisant afin de voir combien de mots chaque personne a prononcés :
In[]:=
wordsSpoken[data_,person_]:=StringRiffle@Values[Select[data,First@#person&]]//WordCount
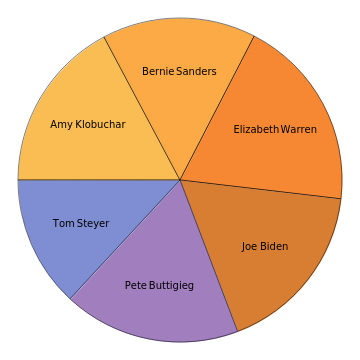
Un de ces données issues du débat le plus récent montre une répartition assez uniforme :
In[]:=
PieChart[wordsSpoken[d7Data,#]&/@candidates,ChartLabelscandidates]
Out[]=
Nous pouvons également approfondir un peu plus le contenu des mots des candidats. Avec , nous pouvons obtenir les personnes, les lieux et les concepts spécifiques mentionnés dans chaque ligne de texte :
In[]:=
entityMentions[data_,entType_String]:=Thread[data[[All,1]]Union/@TextCases[Values@data,entType"Interpretation",VerifyInterpretationTrue]]
Nous pourrions utiliser cela pour explorer un certain nombre de tendances, telles que les entreprises mentionnées lors d’un débat donné :
Counts[Flatten@Values@entityMentions[d7Data,"Company"]]
Out[]=
2,2,2,1,1,1,1,1
Tout au long des débats, plusieurs pays ont également été évoqués ; la visualisation des données avec montre l’accent récent mis sur l’Iran et l’Afghanistan :
In[]:=
WordCloud[Most@Sort@Counts[Flatten@Values@entityMentions[d7Data,"Country"]]]
Puisque le public semble aimer regarder les politiciens parler entre eux et parler les uns sur les autres, j’ai pensé qu’il serait intéressant d’examiner les mentions directes des autres candidats. Nous pouvons utiliser StringCases pour déterminer quand un candidat est mentionné par son prénom ou son nom de famille, y compris l’ancien président Barack Obama et le président actuel Donald Trump, tous deux étant invoqués assez souvent. Cette fonction repère de telles mentions, en associant chaque mention textuelle à une personne précise :
Bien que cette fonction puisse potentiellement renvoyer des faux positifs (par exemple « Warren Buffet » correspondant à « Elizabeth Warren »), j’ai constaté qu’il s’agissait d’un cas suffisamment rare pour que je ne tente pas d’en tenir compte. Dans un texte conversationnel plus large, cela pourrait être un peu plus difficile.
Puisque les modérateurs ne sont pas essentiels pour cette analyse, voici une fonction permettant d’obtenir une liste des seuls candidats démocrates se mentionnant les uns les autres (ou mentionnant Trump/Obama) :
Lorsqu’elle est appliquée à l’ensemble complet des données, nous constatons que les candidats ont mentionné des noms près d’un millier de fois :
Par curiosité, j’ai dû vérifier qui a le plus parlé des deux présidents tout au long des débats, j’ai donc créé une fonction rapide pour compter qui a mentionné le plus une personne donnée :
Amy Klobuchar a beaucoup à dire au sujet du président Trump, tandis qu’Obama est souvent mentionné par son ancien vice-président, Joe Biden. Fait notable, entre les deux listes, nous voyons les cinq principaux candidats actuels (à l’exception de Harris et Castro).
Voici toutes les auto-mentions ; fait amusant, Biden parle le plus de lui-même :
Pour restreindre encore davantage le champ d’analyse, voici une fonction qui fournit une liste des mentions entre les participants d’un débat spécifique uniquement, en supprimant Trump et Obama, ainsi que les auto-références :
Le résultat est une liste réduite de règles que nous pouvons utiliser pour explorer davantage les interactions dans chaque débat individuel.
Graphes : qui était au centre de l’attention ? Nous avons effectué un peu d’analyse de texte et de comptage de base ; il est maintenant temps de changer de perspective pour passer à la théorie des graphes. Si nous considérons la sortie de notre fonction précédente comme une liste de connexions à sens unique entre les candidats (c’est-à-dire des arêtes dirigées pointant de l’orateur vers le sujet), nous pouvons facilement afficher le graphe obtenu pour un débat donné :
Nous pouvons simplifier cette vue en représentant les mentions répétées par des poids d’arête, en stylisant chaque arête en conséquence. Tout d’abord, nous devons convertir les arêtes répétées en arêtes pondérées :
Voici le même graphe, mais avec des arêtes consolidées et redimensionnées en fonction des poids :
En combinant ces étapes (et en ajoutant un peu de couleur), nous pouvons créer une fonction pour afficher le graphe de manière compacte :
Ces graphes offrent un bon résumé visuel des échanges dans chaque débat. Notez que le positionnement des candidats n’est pas important ici, seules les arêtes et leurs styles comptent. Dans le débat le plus récent, vous pouvez observer une forte emphase sur Sanders et Warren, les deux candidats progressistes :
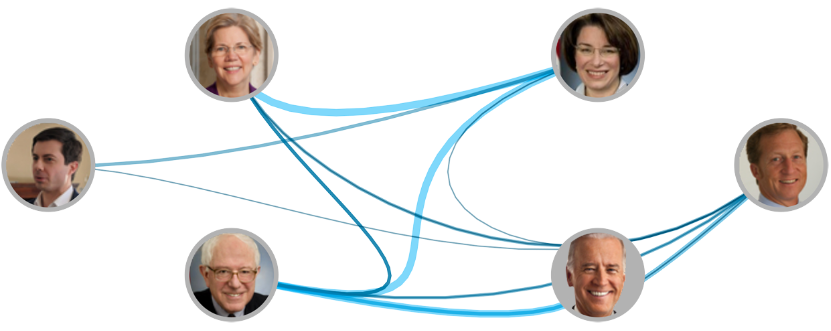
La plupart des candidats ont des images intégrées associées à leurs entités, donc au lieu d'étiqueter avec des noms, nous pourrions également utiliser des visages :
L’application de cela au premier débat donne un graphe intéressant, mais chargé :
D’après ces seuls chiffres, nous pourrions attribuer la victoire à Bernie Sanders pour l’affirmation de soi ou à Tom Steyer pour la popularité. Mais nous pouvons adopter une approche plus visuelle en superposant les données sur notre graphe. Nous calculons d’abord les deux mesures pour chaque sommet :
En combinant cela avec notre fonction existante, nous pouvons créer une nouvelle fonction pour afficher le graphe avec des couleurs de sommets basées sur ce mélange :
Examinons de nouveau le débat le plus récent :
L’histoire ici est claire : Sanders et Warren (violet) étaient au cœur de nombreux échanges, avec des commentaires supplémentaires de la part de Biden et Steyer (qui ont en fait mentionné tout le monde). Klobuchar a interpellé d’autres candidats mais a été à peine nommée, tandis que Buttegieg a été mentionné mais n’a pas parlé des autres. Selon un critère « équilibré » (scores élevés d’affirmation de soi et de popularité), Sanders et Warren semblent être les gagnants.
Revenons un peu plus en arrière au cinquième débat, diffusé le 20 novembre :
Une chose est évidente : davantage de candidats entraînent moins de mentions globales. Cela a du sens d’un point de vue logistique, chaque personne dispose de moins de temps pour s’exprimer, mais je pense que cela montre également l’importance croissante accordée aux différences entre les candidats à mesure que les débats se prolongent.
En combinant toutes les données, nous obtenons une indication de la manière dont les personnes ont eu tendance à interagir tout au long des débats :
Encore une fois, les données racontent une histoire. Biden, le favori présumé de longue date, reçoit beaucoup plus d’attention qu’il n’en accorde. Beaucoup des candidats secondaires, Bullock, Inslee, Delaney, tendent à (ou plutôt, sont capables de) interpeller les autres sans recevoir beaucoup de ripostes. On a presque l’impression que Tom Steyer n’est dans la course qu’en raison de son assertivité !
Pour cette section, revenons à l’analyse de texte ; j’ai trouvé un article Wikipédia regorgeant d’informations récentes présentées dans des tableaux organisés :
La page comprend beaucoup d’informations supplémentaires, et elle continue de s’allonger, mais nous nous intéressons principalement aux sondages entre juin dernier et aujourd’hui. Voici une liste combinée de toutes les entrées de cette période :
Nous avons maintenant des entrées pour chaque sondage, mais toutes les dates sont interprétées comme étant en 2020 :
Comme dernière étape de nettoyage, nous allons corriger les dates et standardiser les noms de clés :
Cependant, cet aperçu inclut plus d’informations que nécessaire, et de nombreux candidats ayant obtenu de faibles scores dans les sondages sont occultés. Examinons de plus près uniquement les leaders, c’est-à-dire toute personne ayant dépassé 10 % dans les sondages depuis le début des débats :
En ajoutant des lignes verticales pour chaque date de débat, nous pouvons obtenir une idée approximative de la manière dont les débats ont influencé les sondages :
Bien que les classements n’aient pas beaucoup évolué, vous pouvez observer quelques pics et creux qui résultent probablement des débats. Pour obtenir une estimation rapide de ceux qui auraient pu gagner ou perdre, nous pouvons agréger les données de la semaine précédant un débat, puis les comparer aux chiffres des sondages de la semaine suivant ce même débat :
La soustraction des deux valeurs donne une estimation des variations en pourcentage autour d’une date donnée :
À partir de là, nous pouvons utiliser la moyenne des sondages par candidat pour déterminer si l’opinion publique a évolué. Par exemple, la moyenne de Kamala Harris a augmenté considérablement après le premier débat en juin :
Cela devrait fournir une mesure globale de la manière dont la performance lors du débat a influencé les sondages pour chaque candidat. Voici les chiffres pour le débat le plus récent, en incluant uniquement les candidats qui y ont effectivement participé :
Caucus de l’Iowa et au-delà Bien entendu, aucun de ces chiffres ne signifient vraiment rien tant que le vote n’a pas commencé. Le premier événement de sélection des candidats de ce cycle, le caucus de l’Iowa, s’est tenu plus tôt cette semaine, avec Pete Buttegieg semblant arriver en tête (sous réserve des résultats définitifs).
Voyons comment cela se compare à nos mentions de débat. Nous devrons obtenir un jeu de données de sondages à l’échelle des États :
En utilisant les fonctions de la section précédente, nous pouvons importer les sondages les plus récents de l’Iowa :
Comme dans la section précédente, nous récupérons l’historique des sondages pour chaque candidat :
L’historique des sondages montre que les classements ont changé radicalement après le débat de l’Iowa :
Sanders et Biden se sont disputé la première place dans l’Iowa, mais Buttigieg et Warren avaient également un certain potentiel. Sanders a connu la plus forte progression dans les sondages au cours des semaines précédant le caucus :
Selon l’analyse standard, Sanders ou Biden auraient évidemment dû arriver en tête. Mais en se référant au graphe de centralité présenté plus tôt, Buttigieg était en réalité le plus « populaire » en ce sens que d’autres le mentionnaient sans qu’il ne mentionne jamais personne d’autre :
Peut-être qu’ignorer les critiques était une stratégie gagnante dans ce cas !
La théorie des graphes constitue un outil utile pour visualiser les échanges interpersonnels, en fournissant des perspectives computationnelles uniques sur la manière dont les candidats interagissent. En combinant cela avec d’autres calculs, il serait possible d’obtenir des informations encore plus intéressantes, par exemple en utilisant l’analyse des sentiments pour déterminer l’attitude des candidats les uns envers les autres. Dans les mois à venir, il sera intéressant de découvrir quels types de débatteurs remportent le plus de primaires : affirmés, populaires ou mixtes. Essayez vous-même, peut-être que vous pourrez définir votre propre mesure computationnelle sur le vainqueur d’un débat !