International Essays |
Science des données citoyennes et piratage civique : le défi des données sur la salubrité de l’eau potable
Science des données citoyennes et piratage civique : le défi des données sur la salubrité de l’eau potable
9 août 2018
Swede White, responsable de la stratégie de communication, relations publiques
Le Code for America organise sa Journée nationale du piratage civique qui aura lieu le 11 août 2018. C’est une excellente occasion pour le personnel et les équipes de tous niveaux de compétence de participer au défi sur les données relatives à la salubrité de l’eau, un programme que Wolfram soutient en offrant un accès gratuit à Wolfram|One et en hébergeant des jeux de données structurées pertinents dans le dépôt de données : Wolfram Data Repository.
Selon l’État de Californie, environ 200 000 résidents de l’État ont de l’eau potable dangereuse qui coule de leurs robinets. Bien que le défi sur les données relatives à la salubrité de l’eau se concentre sur la Californie, des solutions en science des données pourraient avoir des répercussions et des applications pour offrir un meilleur accès à l’eau potable dans d’autres régions confrontées à des problèmes similaires.
L’objectif de cet article est de montrer la façon dont les technologies Wolfram permettent de récupérer facilement des données et de leur poser des questions, nous adopterons donc une approche multiparadigme et laisserons notre analyse être guidée par ces questions dans le cadre d’une analyse exploratoire, une manière de se familiariser rapidement avec les données.
Des informations sur les ressources pédagogiques, la documentation et la formation se trouvent au bas de cette publication.
Données du défi sur l’eau Pour commencer, parcourons l’un des ensembles de données qui a été ajouté à Wolfram Data Repository, voyons comment y accéder et comment l’examiner visuellement à l’aide de Wolfram Language.
Nous allons d’abord définir et récupérer des données sur l’approvisionnement et la production d’eau urbaine en utilisant ResourceData :
Nous allons d’abord définir et récupérer des données sur l’approvisionnement et la production d’eau urbaine en utilisant ResourceData :
In[]:=
uwsdata=ResourceData["California Urban Water Supplier Monitoring Reports"]
Out[]=
Ce que nous obtenons en retour est un cadre de données bien structuré avec plusieurs variables et mesures que nous pouvons commencer à explorer. (Si vous débutez dans le traitement des données en Wolfram Language, vous pouvez consulter ici une introduction fantastique et utile sur Association et Dataset, rédigée par l’un de nos utilisateurs expérimentés.)
Vérifions d’abord les dimensions des données :
In[]:=
uwsdata//Dimensions
Out[]=
{18965,33}
Nous pouvons constater que nous avons près de 19 000 rangées de données avec 33 colonnes. Extrayons la première colonne et la première rangée afin d’avoir une idée de ce que nous pourrions explorer :
In[]:=
uwsdata[1,1;;33]
Out[]=
(Nous pouvons également récupérer le dictionnaire de données depuis California Open Data Portal en utilisant Import.)
In[]:=
Import["https://data.ca.gov/sites/default/files/Urban_Water_Supplier_Monitoring_Data_Dictionary.pdf"]
La production d’eau déclarée semble constituer un point de départ intéressant, alors examinons-la à l’aide de quelques fonctions, TakeLargestBy et Select, pour analyser les dix niveaux de production d’eau les plus élevés par fournisseur pour la dernière période de déclaration :
In[]:=
top10=TakeLargestBy[Select[uwsdata,#ReportingMonthDateObject[{2018,4,15}]&],#ProductionReported&,10]
Out[]=
Sans surprise, nous constatons que les régions très peuplées de l’État de Californie présentent les niveaux les plus élevés de production d’eau déclarée. Puisque nous avons déjà défini notre ensemble de données des dix premiers, nous pouvons maintenant examiner d’autres variables dans ce sous-ensemble des données. Visualisons quels fournisseurs ont les pourcentages les plus élevés quant à leur utilisation résidentielle de l’eau avec BarChart. Nous utiliserons la définition top10 que nous venons de créer et emploierons All pour examiner chaque ligne des données selon la colonne “PercentResidentialUse” :
In[]:=
BarChart[top10[All,"PercentResidentialUse"],ColorFunction->"SolarColors",ChartLabels->Normal[top10[All,"SupplierName"]],BarOrigin->Left]
Out[]=
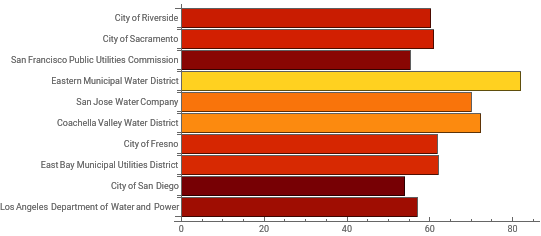
Vous remarquerez que j’ai utilisé ColorFunction pour indiquer les valeurs plus élevées par des couleurs plus vives. (Il existe de nombreuses palettes parmi lesquelles choisir.) À titre de brève exploration, examinons ces districts de fournisseurs selon la population desservie :
In[]:=
BarChart[top10[All,"PopulationServed"],ColorFunction->"SolarColors",ChartLabelsNormal[top10[All,"SupplierName"]],BarOriginLeft]
Out[]=
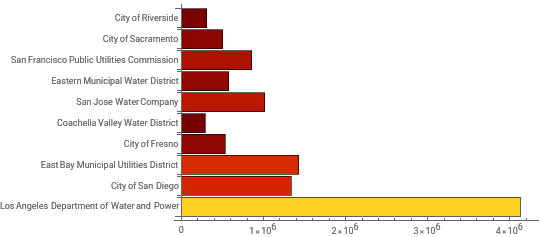
Le district municipal des eaux de l’Est (Eastern Municipal Water District) est parmi les plus petits d’entre eux en termes de population, mais nous examinons les pourcentages d’utilisation résidentielle de l’eau, ce qui pourrait indiquer qu’il y a moins d’utilisation industrielle ou agricole de l’eau dans ce district.
Données sur les pénalités et l’application de la réglementation Puisque nous examinons des données sur l’eau potable sans danger, explorons les pénalités imposées aux fournisseurs d’eau pour des violations réglementaires. Nous utiliserons les mêmes fonctions que précédemment, mais cette fois nous prendrons les cinq principaux, puis nous verrons ce que nous pouvons découvrir à propos d’un district particulier à l’aide des données intégrées :
In[]:=
top5=TakeLargestBy[Select[uwsdata,#ReportingMonthDateObject[{2018,4,15}]&],#PenaltiesRate&,5]
Out[]=
Nous constatons donc que le fournisseur de la ville de San Bernardino présente le taux de pénalité le plus élevé parmi nos cinq principaux acteurs. Commençons à examiner les taux de pénalité pour le district de la ville de San Bernardino. Nous disposons d’autres variables connexes, telles que les plaintes, les avertissements et les suivis. Étant donné que nous traitons des données temporelles, c’est-à-dire des pénalités au fil du temps, nous pourrions utiliser la fonctionnalité TimeSeries, nous allons donc commencer à définir quelques éléments, y compris notre plage de dates (qui est uniforme pour l’ensemble de nos données) ainsi que les variables que nous venons de mentionner. Nous utiliserons également Select pour extraire les données de production concernant uniquement la ville de San Bernardino :
In[]:=
dates=With[{sbdata=Select[uwsdata,#SupplierName"City of San Bernardino"&]},sbdata[All,"ReportingMonth"]//Normal];
Voici quelques points à remarquer ici. Tout d’abord, nous avons utilisé la fonction With pour combiner certaines définitions en un code plus compact. Nous avons ensuite utilisé Normal afin de transformer les dates en une liste pour qu’elles soient plus faciles à manipuler pour les séries temporelles.
En fait, ce que nous avons dit ici, c’est : « Avec les données fournies par le fournisseur nommé Ville de San Bernardino, définissez la variable dates comme le mois de déclaration issu de ces données et transformez-la en une liste. » Une fois que vous commencez à percevoir la logique narrative de votre code, vous pouvez programmer au rythme de votre pensée, un peu comme lors d’une saisie ordinaire, ce pour quoi Wolfram Language est particulièrement bien adapté.
Définissons maintenant nos variables liées aux pénalités :
En fait, ce que nous avons dit ici, c’est : « Avec les données fournies par le fournisseur nommé Ville de San Bernardino, définissez la variable dates comme le mois de déclaration issu de ces données et transformez-la en une liste. » Une fois que vous commencez à percevoir la logique narrative de votre code, vous pouvez programmer au rythme de votre pensée, un peu comme lors d’une saisie ordinaire, ce pour quoi Wolfram Language est particulièrement bien adapté.
Définissons maintenant nos variables liées aux pénalités :
In[]:=
{prate,warn,follow,complaints}=Normal[sbdata[All,#]]&/@Normal[{"PenaltiesRate","Warnings","FollowUps","Complaints"}];
Nous avons donc d’abord placé nos variables entre accolades et utilisé # (appelé « slot », bien qu’il soit tentant de l’appeler « hashtag » !) comme espace réservé pour un argument ultérieur. Ainsi, si nous devions lire cette ligne de code, ce serait quelque chose du genre : « Pour ces quatre variables, utilisez toutes les lignes des données de San Bernardino, transformez-les en une liste et définissez chacune de ces variables avec les colonnes du taux de pénalité, des avertissements, des suivis et des plaintes, dans cet ordre, sous forme de liste. Autrement dit, extrayez ces colonnes de données en tant que variables individuelles. »
Puisque nous utiliserons probablement TimeSeries assez fréquemment avec ces données particulières, nous pouvons également définir une fonction dès maintenant afin de gagner du temps par la suite :
Tout ce que nous avons dit ici, c’est : « Chaque fois que nous tapons ts[], tout ce qui se trouve entre les crochets sera inséré dans le membre droit de la fonction à l’endroit où v se trouve. » Ainsi, nous avons notre fonction TimeSeries, et nous y avons inséré dates afin de ne pas avoir à associer continuellement une plage de valeurs à chacune de nos valeurs de date chaque fois que nous souhaitons créer une série temporelle. Nous pouvons également définir certaines options de style pour gagner du temps lors des visualisations :
Maintenant qu’une partie de la configuration est faite (cela peut être fastidieux, mais il est important de rester organisé et efficace !), nous pouvons générer des graphiques :
Nous avons donc de nouveau utilisé With pour rendre notre code un peu plus compact et nous avons utilisé notre fonction de série temporelle ts[], puis nous sommes descendus d’un niveau en utilisant à nouveau # afin d’appliquer cette fonction de série temporelle à chacune de ces quatre variables. De nouveau, en termes simples, « Avec cette variable, prenez notre fonction de série temporelle et appliquez-la à ces quatre variables qui suivent &. Ensuite, créez un tracé de ces valeurs de séries temporelles et appliquez-lui le style que nous avons défini. »
Nous pouvons voir que certaines des valeurs sont plates le long de l’axe des x. Examinons la plage de valeurs de nos variables et voyons si nous pouvons améliorer cela :
Nous pouvons voir que certaines des valeurs sont plates le long de l’axe des x. Examinons la plage de valeurs de nos variables et voyons si nous pouvons améliorer cela :
Nous pouvons voir que le taux de pénalité a une valeur maximale extrêmement plus élevée que nos autres variables. Alors, que devons-nous faire ? Eh bien, nous pouvons prendre le logarithme des valeurs et les visualiser toutes en une seule fois avec DateListLogPlot :
Ainsi, il semble que le programme d’application n’ait réellement pris toute son ampleur qu’après 2015 et, à la suite d’actions préliminaires, des pénalités ont commencé à être infligées à très grande échelle. Les actions liées aux pénalités semblent également augmenter pendant les mois d’été, peut-être lorsque la production est plus élevée, ce que nous examinerons et confirmerons un peu plus tard. Examinons séparément les avertissements, les suivis et les plaintes :
Nous avons utilisé un code similaire à celui du graphique précédent, mais cette fois-ci nous avons omis notre style défini et utilisé PlotLegends afin de nous aider à voir quelles variables correspondent à quelles valeurs. Nous pouvons visualiser cela d’une manière légèrement différente en utilisant StackedDateListPlot :
Nous observons ici un schéma marqué de plaintes, d'avertissements et de suivis se produisant de concert, ce qui n'est pas très surprenant mais pourrait indiquer l'efficacité des systèmes de signalement.
Nous pouvons également visualiser l’utilisation des terres agricoles d’une autre manière en utilisant GeoSmoothHistogram avec une option GeoBackground :
Entre ces deux visualisations, nous pouvons clairement voir que la vallée centrale de la Californie présente les niveaux les plus élevés d’utilisation des terres agricoles.
Utilisons maintenant à nouveau notre fonction TakeLargestBy pour récupérer les cinq premiers districts en termes d’utilisation d’eau agricole à partir de notre jeu de données :
Utilisons maintenant à nouveau notre fonction TakeLargestBy pour récupérer les cinq premiers districts en termes d’utilisation d’eau agricole à partir de notre jeu de données :
Ainsi, pour le dernier mois de rapport, nous constatons que le district des eaux de Rancho en Californie (Rancho California Water District) présente la plus grande quantité d’utilisation d’eau agricole. Voyons si nous pouvons découvrir où cela se situe en Californie en utilisant WebSearch :
En examinant le premier lien, nous pouvons voir que le district des eaux dessert la ville de Temecula, des parties de la ville de Murrieta ainsi que le lac Vail.
L’une des fonctionnalités les plus pratiques de Wolfram Language est la base de connaissances intégrée directement dans le langage. (Il existe un excellent cours de formation à la Wolfram U sur le cadre de données Wolfram que vous pouvez consulter ici.)
Prenons une carte et une image satellite afin de voir à quel type de terrain nous avons affaire :
L’une des fonctionnalités les plus pratiques de Wolfram Language est la base de connaissances intégrée directement dans le langage. (Il existe un excellent cours de formation à la Wolfram U sur le cadre de données Wolfram que vous pouvez consulter ici.)
Prenons une carte et une image satellite afin de voir à quel type de terrain nous avons affaire :
Cela paraît assez rural et conforme à nos données montrant des niveaux plus élevés d’utilisation agricole de l’eau, mais il est intéressant de noter que cela ne se situe pas dans la vallée centrale où l’utilisation des terres agricoles est la plus élevée, un point à considérer pour une exploration et un examen futurs.
Utilisons maintenant WeatherData pour obtenir des données de précipitations pour la ville de Temecula, puisqu’elles proviennent probablement de la même station météorologique que Vail Lake et Murrieta :
Utilisons maintenant WeatherData pour obtenir des données de précipitations pour la ville de Temecula, puisqu’elles proviennent probablement de la même station météorologique que Vail Lake et Murrieta :
Nous pouvons également récupérer la production d’eau et l’utilisation agricole pour le district et voir s’il existe des corrélations avec la météo et l’utilisation de l’eau, une hypothèse assez évidente, mais il est toujours agréable de démontrer quelque chose avec des données. Allons-y et définissons d’abord une variable de légende :
Nous avons consigné certaines valeurs ici, mais nous pourrions également les redimensionner manuellement afin d’avoir une meilleure idée des comparaisons :
Et nous pouvons effectivement observer certaines baisses de la production d’eau et de l’utilisation agricole lorsque les précipitations augmentent, ce qui indique que l’utilisation et la production sont inversement corrélées aux précipitations et, par définition, que l’utilisation et la production sont corrélées l’une à l’autre.
Nous allons maintenant construire un classifieur avec la variable de résultat définie comme des restrictions obligatoires :
Nous avons obtenu une fonction de classification, et Wolfram Language a automatiquement choisi GradientBoostedTrees pour s’adapter au mieux aux données. Si nous étions certains de vouloir utiliser quelque chose comme la régression logistique, nous pourrions facilement préciser quel algorithme nous souhaitons utiliser parmi plusieurs choix.
Mais examinons de plus près ce que notre sélection automatisée de modèle a produit en utilisant ClassifierInformation :
Mais examinons de plus près ce que notre sélection automatisée de modèle a produit en utilisant ClassifierInformation :
Nous obtenons une description générale de l’algorithme choisi et pouvons voir les courbes d’apprentissage pour chaque algorithme, indiquant pourquoi les arbres à gradient boosté constituaient le meilleur ajustement. Utilisons maintenant ClassifierMeasurements avec nos données de test afin d’examiner dans quelle mesure notre classifieur se comporte :
Quatre-vingt-treize pour cent est acceptable pour nos besoins dans l’exploration de cet ensemble de données. Nous pouvons maintenant générer un tracé afin de voir quel est le seuil de rejet pour
Et affichons la matrice de confusion du classifieur pour voir ce que nous pouvons en tirer :
Il semble que le classifieur pourrait être amélioré pour prédire False. Calculons le score F pour en être sûrs :
Encore une fois, ce n’est pas trop mauvais pour prédire qu’à un moment donné un lieu spécifique sera soumis à des restrictions obligatoires d’irrigation extérieure en fonction des caractéristiques de notre jeu de données. Comme piste d’analyse supplémentaire, nous pourrions utiliser FeatureExtraction comme étape de prétraitement afin de voir si nous pouvons améliorer notre précision. Mais pour cette exploration, nous constatons que nous pourrions effectivement examiner les conditions dans lesquelles un district donné pourrait être tenu de restreindre l’irrigation extérieure et obtenir des informations sur les éléments auxquels les fournisseurs d’eau ou les décideurs politiques devraient accorder le plus d’attention en matière de conservation de l’eau.
Jusqu’à présent, nous avons examiné certains des districts produisant le plus d’eau, les zones présentant des taux de pénalité élevés et la comparaison avec d’autres mesures d’application, l’impact des précipitations sur l’utilisation agricole de l’eau à l’aide de certaines données intégrées, ainsi que la manière dont nous pourrions prédire quelles zones seront soumises à des restrictions obligatoires d’irrigation extérieure, un bon point de départ pour des explorations supplémentaires.
Jusqu’à présent, nous avons examiné certains des districts produisant le plus d’eau, les zones présentant des taux de pénalité élevés et la comparaison avec d’autres mesures d’application, l’impact des précipitations sur l’utilisation agricole de l’eau à l’aide de certaines données intégrées, ainsi que la manière dont nous pourrions prédire quelles zones seront soumises à des restrictions obligatoires d’irrigation extérieure, un bon point de départ pour des explorations supplémentaires.
Essayez par vous-même Pensez-vous être prêt pour le défi sur les données relatives à la salubrité de l’eau potable ? Essayez par vous-même ! Vous pouvez envoyer un e-mail à partner-program@wolfram.com et mentionner « Safe Drinking Water Data Challenge » en objet du message afin d’obtenir une licence pour Wolfram|One. Vous pouvez également accéder à une multitude de ressources de formation gratuites en science des données et en statistique sur la Wolfram U. Si vous êtes bloqué, vous pouvez consulter les ressources suivantes ou vous rendre sur la communauté Wolfram et veiller à y publier également votre analyse.
Ressources supplémentaires :
Ressources supplémentaires :
Nous avons hâte de voir quels problèmes vous pouvez résoudre avec de la créativité et la science des données grâce à Wolfram Language.