International Essays |
Exploraciones de datos censales en el Campo de entrenamiento de ciencia de datos Wolfram
Exploraciones de datos censales en el Campo de entrenamiento de ciencia de datos Wolfram
24 de septiembre de 2021
Kevin Reiss, Alcance y comunicaciones
Este cuaderno es una traducción al español del artículo de la Comunidad Wolfram “Census Data Explorations at the Wolfram Data Science Boot Camp” producido con ayuda de un LLM y verificado por un traductor profesional
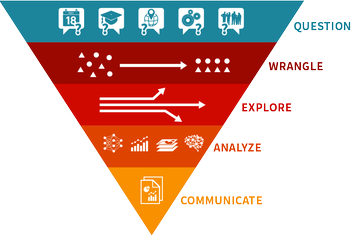
Recientemente terminé el Campo de entrenamiento de ciencia de datos Wolfram de dos semanas, y aprendí mucho sobre cómo llevar un proyecto desde una pregunta inicial hasta una respuesta coherente y visual. Como aprendimos, el enfoque de ciencia de datos multiparadigma tiene múltiples etapas:
Quise tomar algo de lo que aprendí en el campo de entrenamiento para mostrar cómo podemos superar las etapas de manipulación y exploración utilizando Wolfram Language y el marco de trabajo de para datos relacionales. Decidí probar con un conjunto de datos muy grande y comencé en Wolfram Data Repository. Encontré un conjunto de datos con la asombrosa cantidad de 72,818 entidades, el almacén de entidades Census Tract.
Podemos extraer la descripción de estos datos de manera programática:
In[]:=
ResourceObject["Census Tract Entity Store"]["Description"]
Out[]=
US Census tracts with location, polygon, and data from the American Community Survey
Estados Unidos está dividido en pequeñas “zonas censales”, cada una de las cuales contiene una gran cantidad de datos. Este conjunto de datos nos permite registrar un almacén de entidades que configura una base de datos relacional que podemos consultar para extraer datos. Por suerte para mí, recibimos una clase fantástica sobre bases de datos relacionales de Leonid Shifrin al principio del campamento; de lo contrario esto habría sido muy difícil para mí.
Registrar este almacén de entidades es extremadamente sencillo:
In[]:=
EntityRegister[ResourceData["Census Tract Entity Store"]]
Out[]=
{CensusTract}
Las entidades son un marco extremadamente potente para acceder a datos sin tener que salir nunca de Wolfram Language. Por ejemplo, podemos obtener fácilmente la población de Francia:
In[]:=
Out[]=
De la misma manera que este código utiliza una entidad de la clase “Country”, ahora tenemos entidades de la clase “CensusTract” (como es devuelto por nuestra línea ) que contienen todos nuestros datos. Explorar toda una clase de entidades puede ser abrumador, especialmente cuando hay más de 72,000 entidades individuales. He aprendido que lo mejor es comenzar extrayendo una al azar:
In[]:=
randomEntity=RandomEntity["CensusTract"]
Out[]=
La etiqueta de la entidad nos indica de inmediato a qué condado y estado pertenece la entidad. Podemos graficar el contorno exacto de este distrito censal utilizando :
In[]:=
GeoGraphics[Polygon[randomEntity]]
Out[]=
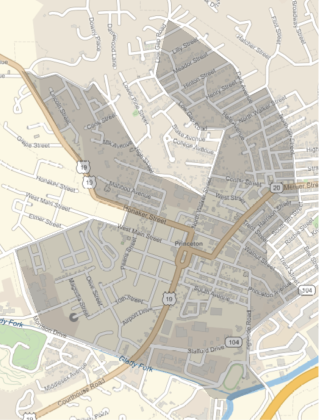
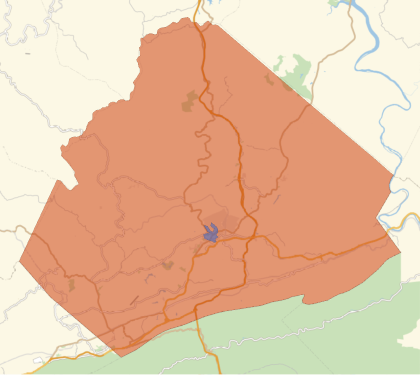
Observamos que la región es mucho más pequeña que todo el condado e incluso más pequeña que una sola ciudad. Mostrar ambas en un solo nos da una idea de cuán granular es cada uno de estos distritos censales:
In[]:=
GeoListPlot,{randomEntity},PlotLegends->Placed[Automatic,Below]
Out[]=
No es sorprendente que los distritos censales sean tan pequeños, dado que hay más de 72,000 de ellos en los EE. UU.:
In[]:=
EntityValue["CensusTract","EntityCount"]
Out[]=
72818
Explore Probemos a crear algunas visualizaciones a partir de los datos, comenzando con algo sencillo como la población.
Quiero representar la densidad de población de Connecticut, mi estado natal. Esto implica encontrar la propiedad que devuelve la población de un sector censal. Esto puede ser complicado cuando hay tantas propiedades:
In[]:=
EntityValue["CensusTract","PropertyCount"]
Out[]=
27058
Afortunadamente, las propiedades generalmente tienen nombres intuitivos. Usando la entidad aleatoria que elegimos antes, podemos obtener fácilmente la población:
In[]:=
randomEntity["Population"]
Out[]=
Si necesitáramos buscar una propiedad, podríamos colocar todas las propiedades en un para poder visualizarlas. En nuestro caso, la propiedad “Population” está cerca del final de la lista:
In[]:=
DatasetEntityProperties["CensusTract"],
Out[]=
Esto nos muestra una forma mucho mejor de filtrar por ubicación. Este ejemplo encuentra todos los distritos censales dentro de un condado dado utilizando una de las propiedades, “ADM2”, que representa los datos del condado. En particular, vemos que también hay una propiedad “ADM1” que representa el estado:
Para nuestra entidad aleatoria, que estaba en Virginia Occidental, vemos:
Al revisar los ejemplos de uso de nuestros datos, hemos encontrado una manera mucho mejor de obtener todos los distritos en un solo estado. Podemos crear una clase con todas las entidades dentro de Connecticut y también requerir que sus poblaciones sean positivas, de modo que obtengamos todas las regiones pobladas:
Analicemos cinco entradas aleatorias para asegurarnos de que nuestros datos estén en el formato que queremos: entidades CensusTract que apuntan a su densidad de población:
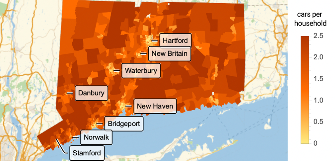
Ahora que tenemos esos datos, podemos superponer etiquetas en la representación de la densidad de población:
Bien, parece que las ubicaciones de las grandes ciudades coinciden con los centros de mayor densidad de población que encontramos en nuestro conjunto de datos. Este fue un ejercicio valioso para asegurarnos de que nuestros datos representan lo que creemos y de que sabemos cómo manipularlos para crear visualizaciones.
Si ampliamos una de las ciudades en la costa, vemos que podemos obtener una representación mucho más precisa de la costa a partir del conjunto de datos del censo. Primero, necesitamos recopilar todas las secciones censales en una ciudad costera. Esta vez, voy a usar GeoWithinQ porque no pude encontrar designaciones censales más pequeñas que el condado, y para una ciudad pequeña en un estado pequeño, no es demasiado ineficiente:
Luego podemos comparar estos polígonos con el polígono de Stamford, que se extiende hacia el estrecho de Long Island:
Existen razones por las cuales es importante tener un polígono de la ciudad que se extienda hacia las aguas costeras que posee, pero para alguien interesado en la línea costera, los polígonos de “CensusTract” tienen un nivel de detalle mucho más fino. Encontrar el mejor conjunto de datos para su proyecto es fundamental.
¿Recuerda antes, cuando restringí mi EntityClass para Connecticut para incluir solo los distritos censales con una población mayor que uno? Eso se debe a que, en mi exploración de los datos, encontré un par de lugares con población cero. Mi favorito en Connecticut fue esta joya:
Es un bonito Polygon que envuelve el Aeropuerto Internacional Bradley. Según los datos de la Oficina del Censo de los Estados Unidos datos, nadie vive allí. Me pregunto qué más se podría aprender sobre aeropuertos utilizando este conjunto de datos.
Esto nos da una lista de las propiedades dentro de esa clase, ¡hay 30!, y a partir de ahí encontré las que nos ayudan a responder nuestra pregunta:
Estos nos indican el número total de hogares con una cantidad determinada de vehículos. Por ejemplo, utilizando nuestra entidad seleccionada aleatoriamente anteriormente, podemos crear una asociación con claves que consisten en el número de coches y valores que consisten en el número de hogares:
Vamos a crear una EntityClass que representa todos los distritos censales en Connecticut con hogares:
Luego, obtener el valor de esta función para cada entidad nos da el número promedio de autos para todos los distritos censales en Connecticut. Este cálculo extrae muchos datos de la API del censo, así que he iconizado el resultado por conveniencia:
Vamos a asegurarnos de que los datos estén en el formato que queremos, algo que siempre hago antes de intentar usar datos nuevos:
Ahora queda claro que el número promedio más probable de autos por hogar en Connecticut es apenas inferior a 2. Podemos ir un poco más allá e intentar aproximar la distribución de probabilidad que siguen los datos:
Ahora que entendemos el uso de estos datos para un solo estado, podemos visualizar los datos para todo el país, que he iconizado para mayor comodidad:
Ahora podemos visualizar la propiedad de automóviles por hogar en los Estados Unidos continentales:
También me pareció interesante observar cuán raro es que una familia posea un auto en el norte de Alaska:
Todo lo que he hecho en este blog apenas ha tocado la superficie de lo que es posible con este conjunto de datos masivo y el marco de entidades de Wolfram Language. Espero que las técnicas de manipulación de datos que aprendí en el campo de entrenamiento y demostré aquí despierten su interés para que se sumerja en nuevos proyectos de datos propios. El Campo de entrenamiento de ciencia de datos Wolfram es una experiencia intensa y guiada de dos semanas, pero usted puede aprender a su propio ritmo e incluso obtener la Certificación en ciencia de datos multiparadigma con el curso interactivo de Wolfram U.
Además le invito a utilizar mi trabajo como punto de partida para sus propias exploraciones de estos datos y a compartir lo que aprenda en la Comunidad Wolfram. Para ver contenido en video cuyo objetivo es hacer la computación y la ciencia de datos menos intimidantes, consulte mi serie de livecoding con Zach Shelton, especialmente nuestro video más reciente sobre Wolfram Data Repository.