International Essays |
Explorations des données du recensement lors du stage intensif de Wolfram sur la science des données
Explorations des données du recensement lors du stage intensif de Wolfram sur la science des données
24 septembre 2021
Kevin Reiss, sensibilisation et communication
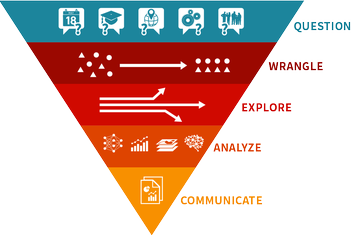
J’ai récemment terminé le stage intensif de Wolfram sur la science des données de deux semaines, et j’ai beaucoup appris sur la manière de mener un projet depuis la question initiale jusqu’à une réponse cohérente et visuelle. Comme nous l’avons appris, l’approche de la science des données multi-paradigme comporte plusieurs étapes :
Je voulais reprendre une partie de ce que j’ai appris au stage pour montrer comment nous pouvons franchir les étapes de préparation et d’exploration en utilisant le cadre de Wolfram Language pour les données relationnelles. J’ai décidé de m’essayer à un ensemble de données de très grande taille et j’ai commencé par le dépôt de données Wolfram Data Repository. J’y ai trouvé un ensemble de données comportant pas moins de 72 818 entités : le magasin d’entités de secteur de recensement (Census Tract Entity Store).
Nous pouvons extraire par programmation la description de ces données :
In[]:=
ResourceObject["Census Tract Entity Store"]["Description"]
Out[]=
US Census tracts with location, polygon, and data from the American Community Survey
Les États-Unis sont divisés en petites « sections », chacune disposant d’une grande quantité de données. Cet ensemble de données nous permet d’enregistrer un magasin d’entités qui met en place une base de données relationnelle que nous pouvons interroger afin d’en extraire des données. Heureusement pour moi, nous avons reçu une fantastique leçon sur les bases de données relationnelles donnée par Leonid Shifrin au début du stage ; sinon, cela aurait été très difficile pour moi.
L’enregistrement de ce magasin d’entités est extrêmement simple :
In[]:=
EntityRegister[ResourceData["Census Tract Entity Store"]]
Out[]=
{CensusTract}
Les entités constituent un cadre extrêmement puissant pour accéder aux données sans jamais avoir à quitter Wolfram Language. Par exemple, nous pouvons facilement obtenir la population de la France :
In[]:=
Out[]=
De la même manière que ce code utilise une entité de la classe “Country”, nous disposons maintenant d’entités de la classe “CensusTract” (telles que renvoyées par notre ligne ) qui contiennent toutes nos données. L’examen d’une classe entière d’entités peut être intimidant, surtout lorsqu’il y a plus de 72 000 entités individuelles. J’ai appris à commencer par en extraire une seule au hasard :
In[]:=
randomEntity=RandomEntity["CensusTract"]
Out[]=
L’étiquette de l’entité nous indique immédiatement à quel comté et à quel État l’entité appartient. Nous pouvons tracer le contour exact de ce secteur de recensement en utilisant :
In[]:=
GeoGraphics[Polygon[randomEntity]]
Out[]=
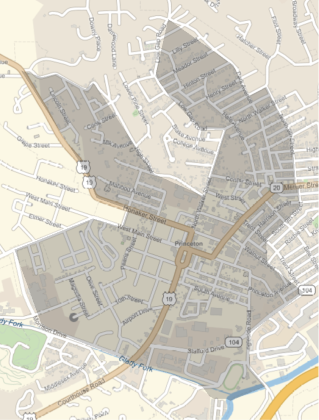
Nous constatons que la région est bien plus petite que l’ensemble du comté et même plus petite qu’une seule ville. L’affichage des deux dans un seul nous donne une idée du niveau de granularité de ces secteurs de recensement :
In[]:=
GeoListPlot,{randomEntity},PlotLegends->Placed[Automatic,Below]
Out[]=
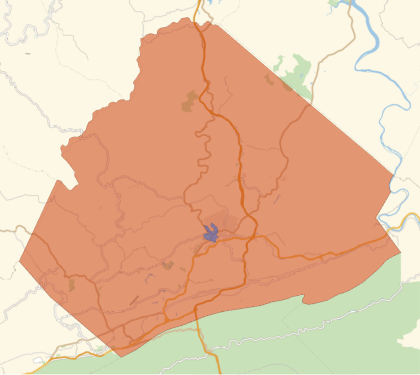
Il n’est pas surprenant que les secteurs de recensement soient si petits, étant donné qu’il y en a plus de 72 000 aux États-Unis :
In[]:=
EntityValue["CensusTract","EntityCount"]
Out[]=
72818
Exploration Essayons de créer quelques visualisations à partir des données en commençant par quelque chose de simple comme la population.
Je souhaite tracer la densité de population du Connecticut, mon État d’origine. Cela implique de trouver la propriété qui renvoie la population d’un secteur de recensement. Cela peut être difficile lorsqu’il y a autant de propriétés :
In[]:=
EntityValue["CensusTract","PropertyCount"]
Out[]=
27058
Heureusement, les propriétés sont généralement nommées de manière intuitive. En utilisant l’entité aléatoire que nous avons choisie plus tôt, nous pouvons facilement obtenir la population :
In[]:=
randomEntity["Population"]
Out[]=
Si nous devions rechercher une propriété, nous pourrions placer toutes les propriétés dans un afin de pouvoir les visualiser. Dans notre cas, la propriété “Population” se trouve vers le bas de la liste :
In[]:=
DatasetEntityProperties["CensusTract"],
Out[]=
Cela nous montre une bien meilleure façon de filtrer par emplacement. Cet exemple trouve tous les secteurs au sein d’un comté donné en utilisant l’une des propriétés, “ADM2”, qui représente les données du comté. En particulier, nous voyons qu’il existe également une propriété “ADM1” qui représente l’État :
Pour notre entité aléatoire, qui se trouvait en Virginie-Occidentale, nous voyons :
En examinant les exemples d’utilisation de nos données, nous avons trouvé une bien meilleure façon pour obtenir tous les secteurs de recensement dans un seul État. Nous pouvons créer une classe de toutes les entités à l’intérieur du Connecticut et exiger également que leurs populations soient positives, afin d’obtenir toutes les régions peuplées :
Examinons cinq entrées aléatoires pour nous assurer que nos données sont dans le format souhaité, les entités CensusTract pointant vers leur densité de population :
Maintenant que nous les avons, nous pouvons superposer des étiquettes au tracé de la densité de population :
Parfait ! Il semble que l’emplacement des grandes villes corresponde aux centres de densité de population plus élevée que nous avons trouvés dans notre jeu de données. Cet exercice valait la peine pour nous assurer que nos données représentent bien ce que nous pensons qu’elles représentent et que nous savons comment les manipuler pour créer des visualisations.
Si nous zoomons sur l’une des villes du littoral, nous voyons que nous pouvons obtenir une représentation beaucoup plus précise de la côte à partir des données du recensement. D’abord, nous devons collecter tous les secteurs de recensement d’une ville côtière. Cette fois-ci, je vais utiliser GeoWithinQ parce que je n’ai pas trouvé de subdivisions de recensement plus petites que le comté et, pour une petite ville dans un petit État, ce n’est pas terriblement inefficace :
Ensuite, nous pouvons comparer ces polygones au polygone de Stamford, qui s’étend dans le détroit de Long Island :
Il existe des raisons pour lesquelles il est important de disposer d’un polygone de la ville qui s’étend dans les eaux côtières qu’elle possède, mais pour une personne qui s’intéresse au littoral, les polygones “CensusTract” ont une granularité beaucoup plus fine. Il est essentiel de trouver le meilleur jeu de données pour votre projet.
Vous vous rappelez, plus tôt, lorsque j’ai restreint mon EntityClass pour le Connecticut afin de n’inclure que les secteurs de recensement ayant une population supérieure à un ? C’est parce que, lors de mon exploration des données, j’ai trouvé quelques emplacements avec une population nulle. Mon préféré dans le Connecticut était ce joyau :
C’est un joli polygone entourant l’aéroport international de Bradley. Selon les données du bureau de recensement des États-Unis, personne n’y habite. Je me demande ce que l’on pourrait apprendre d’autre sur les aéroports en utilisant cet ensemble de données ?
Cela nous donne une liste des propriétés à l’intérieur de cette classe. Il y en a 30 ! Et à partir de là, j’ai trouvé celles qui nous aident à répondre à notre question :
Cela nous indique le nombre total de ménages possédant un nombre donné de véhicules. Par exemple, en utilisant l’entité sélectionnée aléatoirement précédemment, nous pouvons créer une association dont les clés correspondent au nombre de voitures et les valeurs au nombre de ménages :
Allons de l’avant et créons une EntityClass qui représente tous les secteurs de recensement du Connecticut avec des ménages :
Ensuite, l’obtention de la valeur de cette fonction pour chaque entité nous donne le nombre moyen de voitures pour tous les secteurs de recensement du Connecticut. Ce calcul extrait une grande quantité de données de l’API du recensement, j’ai donc mis en icône le résultat pour que ce soit plus commode :
Assurons-nous simplement que les données sont au format que nous souhaitons, ce que je fais toujours avant d’essayer d’utiliser de nouvelles données :
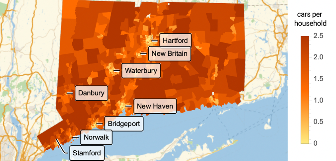
Il est maintenant clair que le nombre moyen de voitures par ménage dans le Connecticut le plus probable est légèrement inférieur à 2. Nous pouvons aller un peu plus loin et essayer d’approximer la distribution de probabilité que suivent les données :
Maintenant que nous comprenons l’utilisation de ces données pour un seul État, nous pouvons visualiser les données pour l’ensemble du pays, que j’ai mis en icône pour que ce soit plus commode :
Nous sommes maintenant en mesure de visualiser la possession de voitures par ménage à travers les États-Unis continentaux :
J’ai également trouvé intéressant de voir à quel point il est rare qu’une famille possède une voiture dans le nord de l’Alaska :
Tout ce que j’ai fait dans ce blog n’a fait qu’effleurer la surface de ce qui est possible avec cet ensemble de données massif et le cadre d’entités de Wolfram Language. J’espère que les techniques de préparation des données que j’ai apprises lors du stage intensif et présentées ici susciteront votre intérêt pour vous lancer dans de nouveaux projets de données personnels. Le stage intensif de Wolfram sur la science des données est une expérience intensive et encadrée durant deux semaines, mais vous pouvez apprendre à votre propre rythme et même obtenir la certification sur la science des données multi-paradigme grâce au cours interactif de la Wolfram U.
Je vous invite également à utiliser mon travail comme point de départ pour vos propres explorations de ces données, et à publier ce que vous apprenez sur la communauté Wolfram. Pour voir du contenu vidéo visant à rendre le calcul et la science des données moins intimidants, consultez ma série de codage en direct avec Zach Shelton, en particulier notre vidéo récente sur le dépôt de données Wolfram.