COVID-19 Progress in Peru Macro Regions: Coast vs. Mountain vs. Jungle
Francisco Rodríguez
Wolfram|Alpha
Background
Every day I’m taking a look at Peru data about COVID-19, and something I have found quite interesting is the fact that the disease has developed very differently in different regions of Peru.
I’ve prepared an EntityStore to handle Peruvian statistical regions (“departamentos”), which are almost exactly the top-level administrative divisions, except the Lima department, which is the union of “Lima” (city) and “Lima Provincias”. So, in this EntityStore, the main difference is that the polygons and values for “Lima” (department) are the union of the “Lima” and “Lima Provincias” entities. There is also information about how these departments can be classified.
Clean the data. “NA” means not available, and empty values are going to be shown as zero; also, split the column label as field-Departamento, to get the field and form the EntityStore “Departamento” standard name:
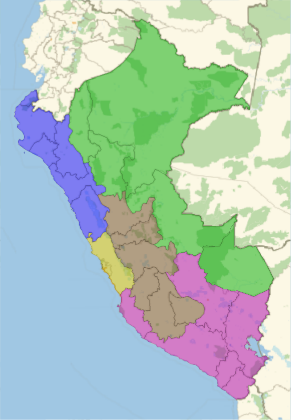
Traditional macro regions in Peru, as they used to be taught in the 1980s, split Peru basically into three regions: costa (coast), sierra (mountain) and selva (jungle). Even though this division is outdated (because not all the mountain region is the same, or not all the jungle shares the same features), we can still group departments using that division to do some statistics. This is how it is split:
Create the main plot function. It prepares the data, and then after plotting it, using the real range options, computes the logarithmic slope lines and where to place each label:
Create an auxiliary function to convert days to a nice-looking text (in Spanish and English):
Create an auxiliary function to clean the time series and shift the points to the initial point asked as a starting point:
Plot COVID-19 Progress by Traditional Divisions
Confirmed cases
Plot with the main plot function the total confirmed cases for each traditional macro region and for Peru as a whole:
Deaths
Plot with the main plot function the total deaths for each traditional macro region and for Peru as a whole:
Average deaths per million
To avoid the noise of deaths per day, let’s take an average over a week:
Compute the average per million by dividing each value by the total population:
Use DateListPlot to show this data for each traditional macro region and for Peru as a whole:
Discussion
Population is not evenly distributed among the regions:
Compute population density with the population property value and area of each polygon:
Let’s take a look at the average elevation of the capital of each macro region.
Use GeoElevationData to get the elevation of each capital coordinate:
In the coast and the jungle regions there are a couple of outliers:
Now we can try a weighted average by population:
So, high population and high population density may explain why spread on the coast is higher than in the mountain or jungle regions. Spread trends in the jungle and mountain regions are quite similar, but the deaths trends are totally different. There is already an article about how the elevation may play a role: https://www.sciencedirect.com/science/article/pii/S1569904820301014. These results may confirm a role, but I’m not sure yet if we can say that the influence is more because people are adapted to less oxygen or because weather helps stop the propagation. We may need to split the data by province or district to properly classify each smaller region by elevation if we want to have more reliable results.
Another factor that could be taken into account to improve these conclusions would be the age distribution of each region. The coast has more access to services and may have a different age distribution than the mountain or jungle regions. But again, such an analysis should be done with more detailed data in smaller regions.