3D Modeling of the SARS-CoV-2 Virus in the Wolfram Language
Jeff Bryant
Wolfram|Alpha, LLC
Late 2019 and continuing through 2020 has seen a historic pandemic that has caused worldwide lockdowns, economic difficulties and of course sickness and death resulting from the onset of COVID-19. Because of the novel nature of the virus, known as SARS-CoV-2 or severe acute respiratory syndrome coronavirus 2, a massive amount of research is going into trying to understand its nature. Although the virus is tiny, trying to model the virus from its constituent molecules is a challenging task, but with a home computer and the Wolfram Language, along with reasonable hardware resources, this task can be tackled.
The original data and PDB files provided by the authors have been imported, cleaned and made computable. I want to thank Ondrej Strnad for his guidance in using their data. Due to the large size of the data and graphics, this can be taxing to systems with low system resources. For the record, I evaluated this using a Windows 10 system with an Intel Core i9 processor with 16 GB of system memory and a Nvidia GeForce 1660 graphics card.
Loading the Data
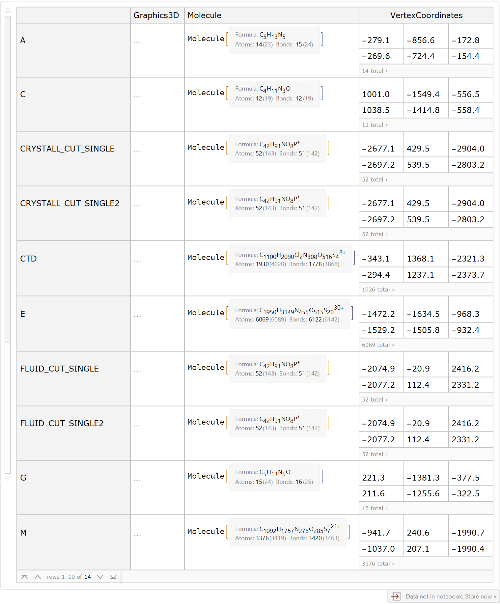
Get a dataset that contains the 3D graphic, molecule representation and VertexCount for each element of the SARS-CoV-2 model:
The resulting dataset is approximately 30 MB total:
In[]:=
ByteCount[modelds]
Out[]=
30784416
The byte count of the “S” element has been simplified by removing spheres and cylinders to reduce the memory footprint and is about 22 MB, and so makes up the bulk of the total size of the model:
In[]:=
modelds["S"]["Graphics3D"]
Out[]=
In[]:=
ByteCount[%]
Out[]=
22790896
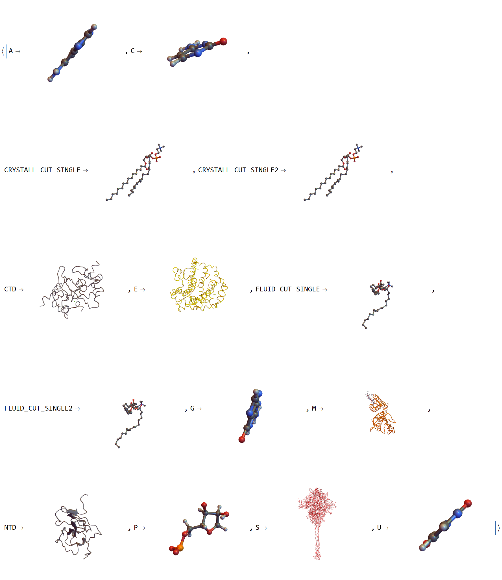
We can view the 3D models of the individual elements:
In[]:=
Normal[modelds[All,"Graphics3D"]]
Out[]=
We also need to know how to assemble the full model from the individual elements. This is done using a dataset containing structural information for all of the elements:
So the full model has nearly 25,000,000 atoms in it.
Analyze the Distance between Structures
Analyze the mean radial distance between structures:
Quaternion Rotation Approach
The structure data contains not just the 3D positions of the elements, but also the rotation for each element represented as a quaternion. For each quaternion, this needs to be converted into a rotation matrix:
Now we need to provide functions that will rotate and translate the specified element based on the structure data:
The “primary” elements seem to be the submodels called “M” and “S”. The position data is straightforward, and can just be plotted as points. The blue points are the positions of the “M” structures, and the orange ones are the positions of the “S” structures:
From a structural point of view, the “M” and “S” elements are the most important. The other elements have less impact on the visual appearance, and there are huge numbers of them:
Now we can actually construct the full 3D model from the elements. Because the spheres and cylinders that make up some of the models are so small, there is no need to render them in full detail, so we can use the Method option to reduce their complexity during rendering:
We can “slice” the model in half to let us see the internal detail:
The resulting Graphics3D expression takes up over 142 MB of memory:
Volumetric Approach
Another approach to visualizing the SARS-CoV-2 virus is based on volumetric data. This can be useful for getting a view that looks more like a fuzzy microscope image.
The original structural data file provides a scale factor that will be needed:
Next we use the vertex coordinates of the elements and scale them:
We can view the results of the above on the “S” element:
Next we rotate and translate all instances of the models:
In order to represent the model as a volumetric region, we need to discretize all of the vertex coordinates into voxels of size pp×pp×pp:
We can test the above my looking only at the instances of the “S” element, which make up the “spikes” of the virus:
We can visualize the volumetric results by looking at slices through the model:
We can also visualize the full volumetric data using Image3D:
Another variation also involves volumetric visualization, but is based on vertex density. To start, we make a gray-level version of atom density:
Since the “S” and “M” proteins make up the primary components of the structure, we use only those, and use a coarse grid initially:
We can also apply different color schemes:
We can include all of the structures, even the small ones, for a more complete and accurate picture. (Even on a 512×512×512 grid, you can rotate interactively with fairly good responsiveness.)
As was done in the Graphics3D variation, we can also slice the 3D structure to see inside:
Media-modeled images of the SARS-CoV-2 virus often come color-coded. We can incorporate some of those concepts as well. We can use colors for the “E”, “M” and “S” elements from here. Some of the small elements are not obvious in media images, so we just assign random colors to those:
Viewing the volumetric data in slices makes it easier to see the internal structure:
Reference
Nguyen, N., Strnad, O., Klein, T., Luo, D., Alharbi, R., Wonka, P., Maritan, M., Mindek, P., Autin, L., Goodsell, D. and Viola, I. 2020. “Modeling in the Time of COVID-19: Statistical and Rule-based Mesoscale Models.” https://arxiv.org/abs/2005.01804.