Robust LLM Pipelines
Robust LLM Pipelines
Making Robust LLM Computational Pipelines from Software Engineering Perspective
Anton Antonov
Wolfram U Data Science Boot Camp
South Florida Data Science Study Group
August, September 2024
Wolfram U Data Science Boot Camp
South Florida Data Science Study Group
August, September 2024

Video recording: "Robust LLM Pipelines" (YouTube/@AAAPrediction)
What is the talk about?
What is the talk about?
Basic premise of the talk:
LLMs are unreliable and slow.
Hence, we find techniques for harnessing LLMs for their more robust and effective utilization.
Goals
Goals
◼
Communicate how LLMs can be harnessed in some useful ways
◼
Exposure to Software Engineering and Software Architecture perspectives on LLMs utilization
◼
Techniques that can be used across different languages and systems
Out[]=

DALL-E 3 prompt
DALL-E 3 prompt
Caricature in the style of propaganda art that illustrates the following statement:
“I want AI to do my laundry and dishes so that I can do art and writing, not for AI to do my art and writing so that I can do my laundry and dishes.”
Make sure to represent the AI with a robot. DO NOT draw or place any text in the image.
“I want AI to do my laundry and dishes so that I can do art and writing, not for AI to do my art and writing so that I can do my laundry and dishes.”
Make sure to represent the AI with a robot. DO NOT draw or place any text in the image.
Who I am?
Who I am?
Pipelines? What pipelines? 1
Pipelines? What pipelines? 1
First encounter
First encounter
Here is a Machine Learning (ML) classification monad pipeline:
In[]:=
SeedRandom[33];clObj=ClConUnit[dsTitanic]⟹ClConSplitData[0.75`]⟹ClConEchoDataSummary⟹ClConMakeClassifier["LogisticRegression"]⟹ClConClassifierMeasurements[{"Accuracy","Precision","Recall"}]⟹ClConEchoValue⟹ClConROCPlot[ImageSize->Medium];
»
summaries:trainingData
,
,
,
,
,testData
,
,
,
,
1 id | ||||||||||||
|
2 passengerClass | ||||||
|
3 passengerAge | ||||||||||||
|
4 passengerSex | ||||
|
5 passengerSurvival | ||||
|
1 id | ||||||||||||
|
2 passengerClass | ||||||
|
3 passengerAge | ||||||||||||
|
4 passengerSex | ||||
|
5 passengerSurvival | ||||
|
»
value:Accuracy0.771341,Precisiondied0.82,survived0.695313,Recalldied0.807882,survived0.712
»
ROC plot(s):died
,survived
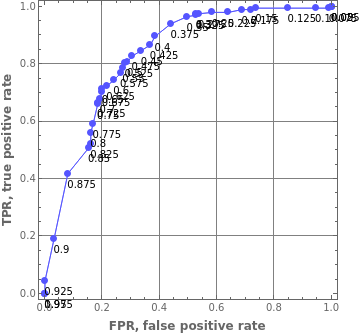

Re-done with LLMs
Re-done with LLMs
One possible way to use LLMs in software pipelines can be illustrated like this:
In[]:=
SeedRandom[33];clObj2=LLMClCon["use the dataset dsTitanic"]⟹LLMClCon["split the data with 0.75 ratio"]⟹LLMClCon["summarize the data"]⟹LLMClCon["make a logistic regression classifier"]⟹LLMClCon["show classifier measurements"]⟹LLMClCon["show ROC plots using image size 400"];
»
summaries:trainingData
,
,
,
,
,testData
,
,
,
,
1 id | ||||||||||||
|
2 passengerClass | ||||||
|
3 passengerAge | ||||||||||||
|
4 passengerSex | ||||
|
5 passengerSurvival | ||||
|
1 id | ||||||||||||
|
2 passengerClass | ||||||
|
3 passengerAge | ||||||||||||
|
4 passengerSex | ||||
|
5 passengerSurvival | ||||
|
Remark: Every time the pipeline is executed splitting is different -- RandomSample is used. (Hence the need of SeedRandom above.)
Pipelines? What pipelines? 2
Pipelines? What pipelines? 2
Schematically
Schematically
Outline
Outline
Modeling LLM-usage frustration (maybe)
Modeling LLM-usage frustration (maybe)
What we are not going to talk about?
What we are not going to talk about?
◼
Training LLMs from scratch
◼
Making and using Retrieval Augmented Generation (RAG) pipelines
◼
Remedies of LLMs “hitting the data wall”
◼
War wrangling, drone deploying, spying streamlining, etc.
Talk-meta
Talk-meta
... aka “Managing expectations and observations”
◼
The proposed techniques transfer to other systems and programming languages that use LLMs
◼
Do not get distracted by the shown pipelines
◼
They are just to communicate the concepts more effectively.
◼
The LLM Domain Specific Language (DSL) in WL is “timeless”
◼
The rest of the techniques would be always applicable, but become less relevant over time
◼
The loss of relevance would be very non-uniform.
◼
The talk uses a mind-map
◼
Questions are answered between the main branches.
◼
Or at any time...
◼
Wolfram Language (aka Mathematica) is used but corresponding examples in Python and Raku are also shown
◼
In order to safe time, not all LLM commands are going to be evaluated
◼
Poll
◼
Who does R? And who does Python?
◼
Who uses LLMs in any way?
◼
Who uses LLMs in production settings?
Pipelines (Data Wrangling)
Pipelines (Data Wrangling)
WL & R pipelines
WL & R pipelines
Here is a natural language specification of a data transformation workflow:
Remark: We call this kind of specifications Domain Specific Language (DSL) specifications.
Here is how this DSL specification is translated to R and WL:
Python pipeline
Python pipeline
obj = dsTitanic.copy()
print(obj.describe())
obj = obj.groupby(["passengerClass", "passengerSex"])
print(obj.size())
print(obj.describe())
obj = obj.groupby(["passengerClass", "passengerSex"])
print(obj.size())
WL pipeline
WL pipeline
Let us consider the execution steps of the WL pipeline:
Pipelines (Quantile Regression)
Pipelines (Quantile Regression)
WL
WL
Here we construct a pipeline (using built-in WL functions):
Here we evaluated it:
Take a more detailed look:
Python
Python
Here is pipeline that pipeline in Python:
LLMs failings (GeoGraphics)
LLMs failings (GeoGraphics)
This graffiti analysis is amazing:
But what happens we request complete, working WL code?
LLMs failings (Populations)
LLMs failings (Populations)
First call
First call
Failings
Failings
Should work, but it does not:
Fixes
Fixes
How to fix it? One way that should work (but is does not work reliably for countries like “Brazil”):
Remark: It this an LLM problem or a interpreter problem?
How do you use LLMs?
How do you use LLMs?
Narration
Narration
Here is a corresponding description:
◼
Start : The beginning of the process.
◼
Outline a workflow : The stage where a human outlines a general workflow for the process.
◼
Make LLM function(s) : Creation of specific LLM function(s).
◼
Make pipeline : Construction of a pipeline to integrate the LLM function(s).
◼
Evaluate LLM function(s) : Evaluation of the created LLM function(s).
◼
Asses LLM's Outputs : A human assesses the outputs from the LLM.
◼
Good or workable results? : A decision point to check whether the results are good or workable.
◼
Can you programmatically change the outputs? : If not satisfactory, a decision point to check if the outputs can be changed programmatically.
◼
The human acts like a real programmer.
◼
Can you verbalize the required change? : If not programmable, a decision point to check if the changes can be verbalized.
◼
The human programming is delegated to the LLM.
◼
Can you specify the change as a set of training rules? : If not verbalizable, a decision point to check if the change can be specified as training rules.
◼
The human cannot program or verbalize the required changes, but can provide examples of those changes.
◼
Is it better to make additional LLM function(s)? : If changes can be verbalized, a decision point to check whether it is better to make additional LLM function(s), or it is better to change prompts or output descriptions.
◼
Make additional LLM function(s) : Make additional LLM function(s) (since it is considered to be the better option.)
◼
Change prompts of LLM function(s) : Change prompts of already created LLM function(s).
◼
Change output description(s) of LLM function(s) : Change output description(s) of already created LLM function(s).
◼
Apply suitable (sub-)parsers : If changes can be programmed, choose, or program, and apply suitable parser(s) or sub-parser(s) for LLM's outputs.
◼
Program output transformations : Transform the outputs of the (sub-)parser(s) programmatically.
◼
Overall satisfactory (robust enough) results? : A decision point to assess whether the results are overall satisfactory.
◼
This should include evaluation or estimate how robust and reproducible the results are.
◼
Willing and able to apply different model(s) or model parameters? : A decision point should the LLM functions pipeline should evaluated or tested with different LLM model or model parameters.
◼
In view of robustness and reproducibility, systematic change of LLM models and LLM functions pipeline inputs should be considered.
◼
Change model or model parameters : If willing to change models or model parameters then do so.
◼
Different models can have different adherence to prompt specs, evaluation speeds, and evaluation prices.
◼
Make LLM example function : If changes can be specified as training rules, make an example function for the LLM.
◼
End : The end of the process.
To summarise:
◼
We work within an iterative process for refining the results of LLM function(s) pipeline.
◼
If the overall results are not satisfactory, we loop back to the outlining workflow stage.
◼
If additional LLM functions are made, we return to the pipeline creation stage.
◼
If prompts or output descriptions are changed, we return the LLM function(s) creation stage.
◼
Our (human) inability or unwillingness to program transformations has a few decision steps for delegation to LLMs.
Remark: We leave as exercises to the reader to see how the workflows programmed below fit the flowchart above.
Remark: The mapping of the workflow code below onto the flowchart can be made using LLMs.
DSLs for LLMs
DSLs for LLMs
◼
Coming up with the DSL design
◼
The three phases
◼
Configuration and Evaluator
◼
Invocation
◼
Post-processing
◼
Chat object management
res = llm_synthesize([
"What are the populations in India's states?",
llm_prompt("NothingElse")("JSON")],
llm_evaluator = llm_configuration(spec = "chatgpt", model = "gpt-3.5-turbo")
)
"What are the populations in India's states?",
llm_prompt("NothingElse")("JSON")],
llm_evaluator = llm_configuration(spec = "chatgpt", model = "gpt-3.5-turbo")
)
Example
Example
Here is a plot:
BTW, we get non-computational results without the “NothingElse” spec:
Creation of an LLM function
Creation of an LLM function
Here is a sequence diagram that follows the steps of a typical creation procedure of LLM configuration- and evaluator objects, and the corresponding LLM-function that utilizes them:
Compare with this spec:
LLM function examples
LLM function examples
Questions
Questions
◼
What other queries can be done with that LLM function?
◼
How do you change the LLM function to give other than GDP quantities?
◼
Can the LLM results be used further?
◼
Say, to plot a bar chart.
◼
What would you do to plot the answer?
◼
Change the LLM prompt / function?
◼
Transform the results?
Partial answer
Partial answer
Creation and execution
Creation and execution
Here is a sequence diagram for making an LLM configuration with a global (engineered) prompt, and using that configuration to generate a chat message response:
Narration
Narration
Step-by-step explanation of the UML sequence diagram:
Chatbook objects management
Chatbook objects management
The following Unified Modeling Language (UML) diagram outlines a chat objects management system that can be used in chatbooks:
Remark: This flowchart can be seen as closely reflecting what is conceptually happening when using WL chatbooks.
Prompt engineering
Prompt engineering
◼
No need to much talk about it after Michael Trott’s presentation and classes
◼
Long and elaborated prompts
◼
Give good results (most of the time)
◼
Slow
◼
Making your own LLM personas, functions, and modifiers within Wolfram’s ecosystem
◼
Jupyter/Raku versions
◼
See/execute in Jupyter/Python
◼
Chessboard generation -- deeper look
Examples-based 1
Examples-based 1
◼
Example of few shot-training
◼
Note that the GDP query above, actually, did not produce “actionable results.”
◼
Elaborated examples with monadic pipelines
Few-shot training
Few-shot training
Consider the following utility function:
Let us apply to the results from the fGDP* functions:
Convert numbers:
Ingest via JSON importing:
Pipeline segments translation 1
Pipeline segments translation 1
Rules
Rules
Here is a set of rules for translating “free text” commands into ML classification workflow code:
Example:
Wrapper function
Wrapper function
Pipeline segments translation 2
Pipeline segments translation 2
Full pipeline
Full pipeline
Continuation
Continuation
Question Answering System (QAS)
Question Answering System (QAS)
◼
In brief: Instead of training LLMs to produce code we ask them to extract parameter values.
◼
Private code: You do not have to share your code with the LLMs.
◼
The LLMs would only know what kind of parameters are associated.
◼
Simplicity: Using QAS is also based on the assumption of the generation of much shorter text is more robust than the generation of longer texts.
QAS with SMLs
QAS with SMLs
Here is an example of code generation via QAS that used a Small Language Model (SML):
How it works
How it works
QAS with LLMs
QAS with LLMs
Of course, we can use LLMs, and get -- most likely -- more reliable results. Here is example:
Here are a list of questions and a list of corresponding answers for getting the parameters of the pipeline:
Another example:
QAS neat example
QAS neat example
Random mandala creation by verbal commands
Random mandala creation by verbal commands
WFR’s RandomMandala takes its arguments -- like, rotational symmetry order, or symmetry -- through option specifications. Here we make a list of the options we want to specify:
Here we create corresponding "extraction" questions and display them:
Here we define rules to make the LLM responses (more) acceptable by WL:
Here we define a function that converts natural language commands into images of random mandalas:
Here is an example application:
Here is an application with multi-symmetry and multi-radius specifications:
Grammar-LLM combinations 1
Grammar-LLM combinations 1
Use case (formulation)
Use case (formulation)
Assume that we have been given the task to:
◼
Gather opinions about programming languages
◼
One person can given opinions for several languages
◼
Relatively large number of people is interviewed (e.g. 300+)
◼
Each interviewee is asked to give one sentence, short opinions
Grammar-LLM combinations 2
Grammar-LLM combinations 2
Grammar and parsers
Grammar and parsers
Here is an Extended Backus-Naur Form (EBNF) grammar for expressing programming language opinions:
Here are random sentences generated with that grammar:
Here are parsers generated for that grammar:
Grammar-LLM combinations 3
Grammar-LLM combinations 3
LLM function
LLM function
Here we define an LLM function that converts programming language opinions into JSON dictionaries:
Here is an example invocation:
Note that misspellings are handled:
Grammar does not parse it:
Grammar-LLM combinations 4
Grammar-LLM combinations 4
Overall retriever function
Overall retriever function
The following function combines the parsing with the grammar and the LLM function:
◼
If a statement can be parsed with the grammar then the parsing result is interpreted into a rule
◼
Otherwise the statement is given to the LLM function
Remark: Note that the function wraps the results with the symbols Grammar and LLM in order to have an indication which interpreter was used.
Grammar-LLM combinations 4
Grammar-LLM combinations 4
Experiments
Experiments
Here we expect the grammar to be used:
Here too:
Here we expect the LLM function to be used:
Here is a set of statements (some with misspellings):
Here is how they are interpreted:
Here we gather the opinions from the obtained interpretations:
Remark: The grammar can be extended in order to decrease the LLM usage.
Testings with data types and shapes
Testings with data types and shapes
This technique:
Testings with data types and shapes over multiple LLM results.
Is both a “no-brainer” and severely under-utilized.
Testings with data types and shapes 2
Testings with data types and shapes 2
In order to do apply this technique we have to have a way to comprehensively derive data types for different (serializable) data structures.
WL
WL
Python
Python
See the Jupyter notebook “Robust-LLM-Pipelines-SouthFL-DSSG-Python.ipynb”
Raku
Raku
Modeling accumulated frustration & money
Modeling accumulated frustration & money
... while using LLMs
◼
Using a System Dynamics (SD) model
◼
Using ”MonadicSystemDynamics”
◼
Based on the “LLM developer decisions” flowchart shown earlier
◼
Qualitative investigations
◼
Calibration challenges
◼
These are not excuses not to do calibration.
◼
The SD model:
Left over comments or Questions
Left over comments or Questions
Left over remarks
Left over remarks
◼
“Less is more” is at play with LLMs.
◼
Repository submissions during this South FL DSSG presentation:
◼
Small Language Models (SML) are/will/would become used more because of LLM.
◼
Using pictures to make pipelines.
◼
Experimenting with LLMs is like a having a second part-time job.
◼
And the know-how and impressions become obsolete quickly...
◼
Pareto principle for workflows.
◼
Figuring out Truchet tiling for the headline image
◼
Instead of Mandalas strip
Anticipated questions
Anticipated questions
◼
Which is your favorite technique? (Of those presented / related.)
◼
Why people prefer using ChatGPT’s interface?
◼
Instead of chatbooks.
◼
Are there Jupyter chatbooks?
◼
Yes, both in Python and Raku
◼
Does Python/Raku/WL support grammars?
◼
Why do you use Raku?
◼
Why do you use monads?
◼
Are these techniques applicable without monads or pipelines?
◼
Yes, fully.
◼
Monads and pipelines are used in the presentation to speed-up knowledge transfer.
References
References
Articles
Articles
[SW1] Stephen Wolfram, "The New World of LLM Functions: Integrating LLM Technology into the Wolfram Language", (2023), Stephen Wolfram Writings.
[SW2] Stephen Wolfram, "Introducing Chat Notebooks: Integrating LLMs into the Notebook Paradigm", (2023), Stephen Wolfram Writings.
Notebooks
Notebooks
[AAn4] Anton Antonov, «Comprehension AI aids for Stephen Wolfram's article "Can AI Solve Science?”», (2024), Wolfram Community.
Functions, paclets
Functions, paclets
[AAp2] Anton Antonov, MonadicContextualClassification WL paclet, (2024), Wolfram Language Paclet Repository.
[AAp1] Anton Antonov, MonadicQuantileRegression WL paclet, (2024), Wolfram Language Paclet Repository.
Videos
Videos
[AAv1] Anton Antonov, Natural Language Processing Template Engine, (2022), Wolfram Technology Conference 2022 presentation. YouTube/WolframResearch.
[AAv3] Anton Antonov, Monte Carlo demo notebook conversion via LLMs and parsers, (2024), YouTube/AntonAntonov.
Setup code
Setup code
Functions
Functions
Paclets
Paclets
Data
Data
Quantile Regression
Quantile Regression
Latent Semantic Analysis
Latent Semantic Analysis
Classification
Classification
LLM functions
LLM functions
Code formatting
Code formatting
ClCon
ClCon
QRMon
QRMon