このノートブックを使えば、『手を動かしながらやさしく学べるはじめてのAIデータサイエンスリテラシー』 (技術評論社)に掲載しているWolfram言語のプログラムを直接実行することができます。最初に、右上のメニュー [ Make Your Own Copy ] をクリックし、自分のWolfram Cloudにこのノートブックをコピーして利用しましょう。詳しくは、序章 「0-3 Wolfram言語を使うための準備」および「0-4 本書のプログラムを実行する方法」(P11〜16ページ)を参照して下さい。なお、このノートブックでは、本書独自のフォーマットを使ってプログラムの入力部分にオレンジの枠,出力部分にブルーの枠がついたものとなっています。新規でノートブックを開いた時のまっさらのノートブックとは異なりますが、通常のノートブックと同様にプログラムを自分で入力することもできます。
第6章 テキストデータから見える世界
第6章 テキストデータから見える世界
6-1 テキストデータとは
6-1 テキストデータとは
テキストのデジタル化
テキストのデジタル化
ToCharacterCode["W"]
Out[1]=
{87}
IntegerDigits[87,2]
Out[2]=
{1,0,1,0,1,1,1}
ToCharacterCode["A"]
Out[3]=
{65}
IntegerDigits[65,2]
Out[4]=
{1,0,0,0,0,0,1}
ToCharacterCode["あ","ASCII"]
Out[5]=
{None}
$CharacterEncodings
Out[6]=
{AdobeStandard,ASCII,CP936,CP949,CP950,EUC-JP,EUC,IBM-850,ISO8859-10,ISO8859-11,ISO8859-13,ISO8859-14,ISO8859-15,ISO8859-16,ISO8859-1,ISO8859-2,ISO8859-3,ISO8859-4,ISO8859-5,ISO8859-6,ISO8859-7,ISO8859-8,ISO8859-9,ISOLatin1,ISOLatin2,ISOLatin3,ISOLatin4,ISOLatinCyrillic,Klingon,koi8-r,MacintoshArabic,MacintoshChineseSimplified,MacintoshChineseTraditional,MacintoshCroatian,MacintoshCyrillic,MacintoshGreek,MacintoshHebrew,MacintoshIcelandic,MacintoshKorean,MacintoshNonCyrillicSlavic,MacintoshRomanian,MacintoshRoman,MacintoshRomanPDFExport,MacintoshThai,MacintoshTurkish,MacintoshUkrainian,Math1,Math2,Math3,Math4,Math5,Mathematica1,Mathematica2,Mathematica3,Mathematica4,Mathematica5,Mathematica6,Mathematica7,PrintableASCII,ShiftJIS,Symbol,UTF-8,UTF8,WindowsANSI,WindowsBaltic,WindowsCyrillic,WindowsEastEurope,WindowsGreek,WindowsThai,WindowsTurkish,ZapfDingbats}
ToCharacterCode["A","UTF-8"]
Out[7]=
{65}
ToCharacterCode["あ","UTF-8"]
Out[8]=
{227,129,130}
ToCharacterCode["うるふらむ","UTF-8"]
Out[9]=
{227,129,134,227,130,139,227,129,181,227,130,137,227,130,128}
ToCharacterCode["ウルフラム","UTF-8"]
Out[10]=
{227,130,166,227,131,171,227,131,149,227,131,169,227,131,160}
6-2 自然言語処理
6-2 自然言語処理
テキストデータを分割してみよう
テキストデータを分割してみよう
In[11]:=
wolframText="For more than three decades, we have progressively built an unprecedented base of technology that now makes possible our broad portfolio of innovative products.30年以上に渡り,弊社では,継続的に優れた技術ベースを構築し,それを使って多数の斬新な製品を生み出してきました。";
StringSplit[wolframText]//InputForm
Out[12]//InputForm=
{For, more, than, three, decades,, we, have,
progressively, built, an, unprecedented, base, of,
technology, that, now, makes, possible, our, broad,
portfolio, of, innovative, products.,
30年以上に渡り,弊社では,継続的に優れた技術ベースを構\
築し,それを使って多数の斬新な製品を,
生み出してきました。}
progressively, built, an, unprecedented, base, of,
technology, that, now, makes, possible, our, broad,
portfolio, of, innovative, products.,
30年以上に渡り,弊社では,継続的に優れた技術ベースを構\
築し,それを使って多数の斬新な製品を,
生み出してきました。}
テキストを単語単位に区切る
テキストを単語単位に区切る
StringSplit["私の髪も長かった"]//InputForm
Out[13]//InputForm=
{私の髪も長かった}
StringSplit["私 の 髪 も 長かっ た"]//InputForm
Out[14]//InputForm=
{私, の, 髪, も, 長かっ, た}
ストップワードで分割する
StringSplit["私の髪も長かった","の","も","た"]
Out[15]=
私,髪,長かっ
形態素解析で単語を分割する
形態素解析で単語を分割する
StringSplit["すもももももももものうち","の","も","た"]
Out[16]=
す,,,,,,,,,うち
構文解析で単語間の関係をつかむ
構文解析で単語間の関係をつかむ
TextStructure["I am a high school student in Kyoto, Japan. "]
Out[17]=
| ||||||||||||||||||||||||||||||||||
Sentence |
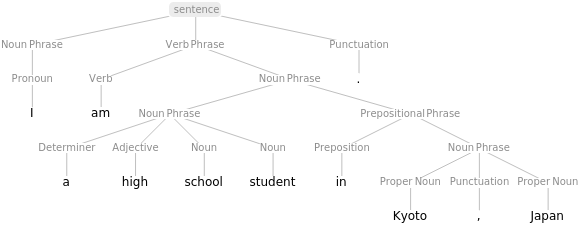
TextStructure["I am a high school student in Kyoto, Japan. ","ConstituentGraphs"]
Out[18]=
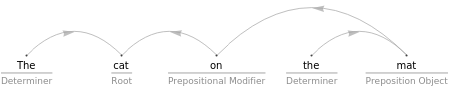
TextStructure["The cat on the mat. ","DependencyGraphs"]
Out[19]=
6-3 ワードクラウドとは
6-3 ワードクラウドとは
ワードクラウドによるテキストデータの可視化
ワードクラウドによるテキストデータの可視化
6-4 演習:「走れメロス」のワードクラウドを作ろう
6-4 演習:「走れメロス」のワードクラウドを作ろう
1. テキストデータの準備
1. テキストデータの準備
2. ワードクラウドの作成
2. ワードクラウドの作成
応用: ワードクラウドの色や形を変えてみよう
応用: ワードクラウドの色や形を変えてみよう