MathematicaでRAGを実装
MathematicaでRAGを実装
Key関数:CosineDistance, GPTTokenizer, Import, LLMSynthesize, PositionSmallest, StringRiffle
Mathematica: 14.0.0
Mathematica: 14.0.0
はじめに
LLMは学習外の内容に対応できない問題がありますが、RAG(Retrieval Augmented Generation)技術の使用により、未知の情報にも対応可能になります。
RAGの仕組みは以下となります。0. 事前準備 : ドキュメントを分割し、それをembeddingしたものとペアでデータベースの登録1. Retrieval : 質問に関連する情報をデータベースから検索2. Augmented : 質問に検索した情報を付け加え拡張してLLMに問い合わせ3. Generation : 問い合わせに対する回答を生成
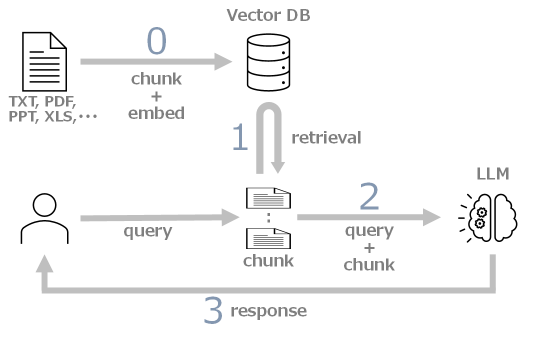
なお、ここで使用しているLLMは、gpt-4-32kです。
RAGを使用せずにLLMに問い合わせ
まず、RAGを使わない場合の問題点を検証します。
質問は、以下とします。
「日本国憲法で定められた両院議員の任期を教えてください。また、それは何条に書かれていますか?」
「日本国憲法で定められた両院議員の任期を教えてください。また、それは何条に書かれていますか?」
正解は、以下となります。 ・ 第45条:衆議院議員の任期は四年 ・ 第46条:参議院議員の任期は六年で三年ごとに議員の半数が改選 ・ 第102条:第一期の参議院議員のうち半数の任期は三年
情報を与えずLLMに問い合わせ
情報を与えずLLMに問い合わせ
In[]:=
question="日本国憲法で定められた両院議員の任期を教えてください。また、それは何条に書かれていますか?";
response1=LLMSynthesize[question]
Out[]=
日本国憲法では、衆議院議員の任期は4年、参議院議員の任期は6年と定められています。これはそれぞれ日本国憲法第54条と第46条に書かれています。
任期の情報は正確ですが、第54条ではなく第45条が正しいです。また、第102条については言及されていません。
日本国憲法の全文を与えてLLMに問い合わせ
日本国憲法の全文を与えてLLMに問い合わせ
日本国憲法の全文を用意します。
In[]:=
constitution=;StringTake[constitution,180]
Out[]=
〔天皇の地位と主権在民〕 第一条 天皇は、日本国の象徴であり日本国民統合の象徴であつて、この地位は、主権の存する日本国民の総意に基く。〔皇位の世襲〕 第二条 皇位は、世襲のものであつて、国会の議決した皇室典範の定めるところにより、これを継承する。〔内閣の助言と承認及び責任〕 第三条 天皇の国事に関するすべての行為には、内閣の助言と承認を必要とし、内閣が、
日本国憲法全文の文字数は約1.1万、トークン数は約1.3万
In[]:=
StringLength@constitution
Out[]=
10521
In[]:=
Length@[constitution,Method->"GPT-3.5"]
Out[]=
12675
ここで使用するLLMの最大トークン数は3.2万であるため、日本国憲法全文を与えてLLMに問い合わせてみます。
prompt1=question<>"\n以下の情報を参考にしてください。\n###\n"<>constitution;response2=LLMSynthesize[prompt1]
Out[]=
日本国憲法における両院議員の任期は、衆議院議員の任期は四年(第四十五条)、参議院議員の任期は六年(第四十六条)と定められています。
任期と条番号は正確になりましたが、第102条については言及されていません。これは、LLMに与える情報量が多すぎるためと思われます。
それでは、RAGを使って期待する回答が得られるか試してみましょう。
RAGの準備(Vector DBの作成)
データの読み込み
データの読み込み
Webから日本国憲法に関する記載をXMLObject形式でインポートします。
In[]:=
xml=Import["https://www.shugiin.go.jp/internet/itdb_annai.nsf/html/statics/shiryo/dl-constitution.htm","XMLObject"];
チャンク分割
チャンク分割
全103条に関連する部分だけを抽出します。
In[]:=
items=Cases[xml,(XMLElement["p",{"class""mid"},{x_}]|XMLElement["p",{"class""bun"},{x_}])StringTrim[x],∞];
RAGでは、意味のある塊としてのチャンク作成が回答の精度に大きく影響します。そのため、各条文を1文にまとめて1チャンクとし、それをベクトルDBに登録できるようにします。
In[]:=
chunks=Split[items,StringTake[#2,1]=!="〔"&];chunks=StringRiffle/@chunks;
chunksを確認しておきましょう。
In[]:=
Length@chunks
Out[]=
103
In[]:=
chunks[[;;5]]//TableForm
Out[]//TableForm=
〔天皇の地位と主権在民〕 第一条 天皇は、日本国の象徴であり日本国民統合の象徴であつて、この地位は、主権の存する日本国民の総意に基く。 |
〔皇位の世襲〕 第二条 皇位は、世襲のものであつて、国会の議決した皇室典範の定めるところにより、これを継承する。 |
〔内閣の助言と承認及び責任〕 第三条 天皇の国事に関するすべての行為には、内閣の助言と承認を必要とし、内閣が、その責任を負ふ。 |
〔天皇の権能と権能行使の委任〕 第四条 天皇は、この憲法の定める国事に関する行為のみを行ひ、国政に関する権能を有しない。 2 天皇は、法律の定めるところにより、その国事に関する行為を委任することができる。 |
〔摂政〕 第五条 皇室典範の定めるところにより摂政を置くときは、摂政は、天皇の名でその国事に関する行為を行ふ。この場合には、前条第一項の規定を準用する。 |
ベクトルDBの作成
ベクトルDBの作成
In[]:=
embs=EmbedE5["passage: "<>#]&/@chunks;
これにより、全103のチャンク(条文)が1024次元ベクトルに変換されました。
In[]:=
Dimensions@embs
Out[]=
{103,1024}
embsとchunksを用いてベクトルDBを作成します。
In[]:=
vectorDB=Transpose[{embs,chunks}];
ベクトルDBの中身を確認しておきましょう。
In[]:=
vectorDB[[1]]//Shallow
Out[]//Shallow=
{0.0425639,-0.0142385,-0.0147412,-0.0608437,0.0332272,-0.0478403,0.0334507,0.0484528,0.032726,-0.0139437,1014},〔天皇の地位と主権在民〕 第一条 天皇は、日本国の象徴であり日本国民統合の象徴であつて、この地位は、主権の存する日本国民の総意に基く。
RAGの実行
質問に近い条文の検索(Retrieval)
質問に近い条文の検索(Retrieval)
質問をチャンクと同様に1024次元ベクトルに変換します。
In[]:=
embQ=EmbedE5["query: "<>question];
質問内容に近い(質問とのベクトル余弦距離が小さい)チャンクを5つ選びます(選択数は任意です)。
In[]:=
distances=ParallelMap[CosineDistance[embQ,#]&,vectorDB[[All,1]]];top=5;pos=PositionSmallest[distances,top]
Out[]=
{{102},{46},{45},{43},{49}}
質問の回答に必要な第45, 46, 102条がTOP3に選ばれました!
質問に検索した情報を付け加え拡張(Augmented)
質問に検索した情報を付け加え拡張(Augmented)
質問に、選ばれた5つの情報(チャンク)を付け加えて拡張します。
拡張したプロンプトのトークン数は436で、日本国憲法全文を使用する場合の約1/30になりました。
拡張したプロンプトを用いてLLMに問い合わせ(Generation)
拡張したプロンプトを用いてLLMに問い合わせ(Generation)
この拡張したプロンプトを使ってLLMに問い合わせてみます。
期待どおりの回答が得られました!
関数化
関数化
以上の内容をまとめて関数化します。
上述の質問と回答は、以下となります。
これまでの3パターンの問い合わせ結果を再掲しておきます。
おわりに
LLMの問題点である、学習外の内容に対応できない、また情報過多で回答が不十分になる点を解決するRAGについて説明しました。
また、RAGを使うと、非公開情報を基にLLMが回答を生成することが可能になります。
ただし、ここで説明したベクトルDBの作成はプライベートな環境で行いましたが、LLMSynthesizeはOpenAIなどの外部サービスを利用しているため、非公開情報を使用することはできません。
この問題を解決するために、プライベートな環境で構築できるLLMモデルが日々公開されています。ハードウェア環境や日本語対応などの課題はありますが、AIのワープスピードの進化により、個人のPCでストレスなくLLMを動かせる日も近いと思います。
Helper Functions